Snowflake FinOps: Maximize the Investment on Your Cloud Data Warehouse
Snowflake is one of the most popular cloud data platforms companies rely on for their data...

Snowflake is one of the most popular cloud data platforms companies rely on for their data...

Data governance has become an essential agenda item for many organizations. The reasons are varied,...

For many, homogeneous system copies aren’t as hot a topic compared to cloud replication and virtual...

Migration to a new data platform can be a complex and time-consuming process. A well-defined plan...
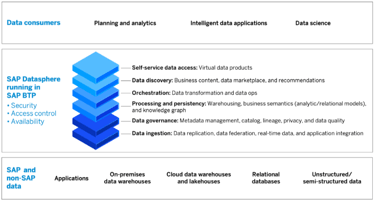
SAP Datasphere, SAP’s comprehensive data service and solution, was released on March 8th, 2023....

As data breaches become increasingly common, protecting sensitive data has become a top priority...

One of our clients patched its EBS database 19.13 to DBRU 19.17 and faced an issue with one of the...

Point-In-Time-Restore using pg_basebackup on PostgreSQL I had a conversation with another DBA about...
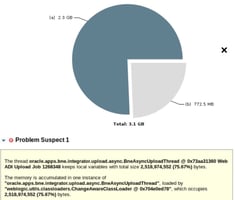
A new client was experiencing regular issues with its OA Core servers on its EBS 12.2 environment....

Is your Prometheus performance causing your Grafana experience to suffer? Could you explain which...

