
This is the second article in a series about internals and performance of concurrent managers. In this post, we'll take a look at three important settings that affect the performance of concurrent managers:
number of processes, "sleep seconds", and "cache size". This article might be a bit on the theoretical side, but it should provide a good understanding of how these settings actually affect the behavior and performance of concurrent managers. Most of the statements in this article are built off of information from my previous post:
The Internal Workflow of E-Business Suite Concurrent Manager Process. It may be helpful to take a look at it before continuing with this one.
 The Life cycle of a Concurrent Request (CR)[/caption] Based on the diagram above, the pending time of the request is the interval between the time the request was scheduled to start and the time it actually started. This time can be split in two parts:
The Life cycle of a Concurrent Request (CR)[/caption] Based on the diagram above, the pending time of the request is the interval between the time the request was scheduled to start and the time it actually started. This time can be split in two parts:
Life cycle of a concurrent request
The interesting thing about tuning concurrent managers is the fact that we don't tune a particular query or a running process, but we actually tune the pending time of concurrent requests. The goal of the tuning is to make sure concurrent requests start executing soon enough after the time they have been scheduled for. Let's take a look at the life cycle of a concurrent request: [caption id="attachment_53399" align="aligncenter" width="1377"]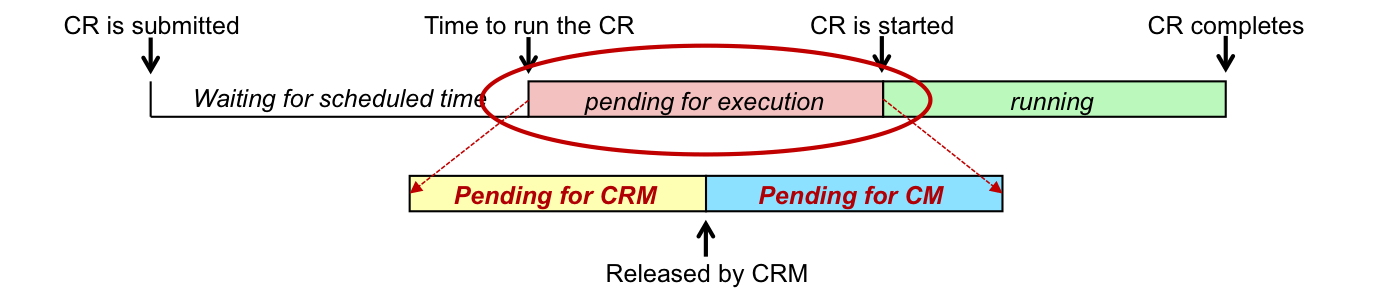 The Life cycle of a Concurrent Request (CR)[/caption] Based on the diagram above, the pending time of the request is the interval between the time the request was scheduled to start and the time it actually started. This time can be split in two parts:
The Life cycle of a Concurrent Request (CR)[/caption] Based on the diagram above, the pending time of the request is the interval between the time the request was scheduled to start and the time it actually started. This time can be split in two parts:
- Pending for Conflict Resolution Manager (CRM) - Here the CRM checks the incompatibility rules effective for the pending concurrent request against other running requests. The CRM allows the request to execute only when all incompatible requests have completed.
- Pending for Concurrent Manager (CM) - This is the time spent waiting for an available concurrent manager process. It also includes the time the CM process takes to fetch the request from FND_CONCURRENT_REQUESTS table and to start executing it. "Pending for CM" is the interval that can be tuned by altering the number of manager processes, "sleep seconds", and the "cache size" settings.
Requirements
Understanding the requirements is a mandatory step for any tuning attempt. Otherwise, it's hard to know when to stop tuning, as it can become unclear if the performance is sufficient or not. When you're tuning concurrent managers, the requirements can be defined by answering a simple question: How long is the request allowed to stay pending after the scheduled start? You should also keep in mind the following items while thinking about the answer:- Be realistic - "Requests should start immediately" is not a valid answer. It's simply impossible because of how concurrent managers work. If there is anything you have to run immediately, concurrent programs are not the correct way of doing it.
- Think of groups of concurrent programs - If you have similar requirements for a group of requests (i.e. a program printing invoices while the customer is waiting on-site should start executing in 10 seconds after it's submitted), a dedicated concurrent manager should be implemented for them.
- Unsure of requirements? - If the requirements are not known, ask the end users if they have experienced situations when requests stay in the queue for too long. Was it because the managers couldn't cope with the amount of incoming requests? If so, the settings might be too low.
- Work Shifts - If the requirements differ at different times of the day, concurrent manager Work Shifts can be used to define different settings depending on the time of the day.
Settings
The settings related to concurrent managers are explained in the documentation: Oracle E-Business Suite System Administrator's Guide - Configuration. But I find the explanations are too often unclear to effectively tune the concurrent managers. In this chapter I'll reveal the basic principles behind each of the three main settings and will describe how I utilize them to control the performance of concurrent managers.Number of Processes
From the Documentation: " The number of operating system processes you want your work shift to run simultaneously. Each process can run a concurrent request."- It's important to add that there is no coordination between processes of a concurrent manager. If all concurrent processes were fetched from the FND_CONCURRENT_REQUESTS table at exactly the same time, they would all read exactly the same information about pending requests. A simple mechanism of row locking is utilized later to allow the execution of a concurrent request on a single manager process.
- Choosing the correct number of concurrent processes is not easy since the workloads are not constant and the number of pending requests can vary. Here are some clues you should consider (I'm also planning a future blog post about measuring the actual utilization levels of concurrent managers):
- Don't configure too many processes! Your hardware is limited. If you configure too many processes you'll exhaust the server resources. For example, if you run lots of big Oracle Reports (CPU-intensive workload) and you have 4 CPUs on your only web/forms/concurrent node, configuring 8 processes for the concurrent manager is risky. If 8 reports where to be generated at the same time, the users could experience web/forms slowness. The same applies to the database tier. Additionally, if too many processes are configured, they can use a significant amount of resources even when they are idle. This is especially important for RAC configurations. (This too will be explained in one of my upcoming blog posts.)
- Don't configure too few processes! If the number of processes is insufficient, the requests will start queuing. If that becomes an issue, increase the number of processes slightly. Consider defining a Work Shift with a different number of processes at different times of the day to accommodate your requirements.
- Don't be afraid of queuing! Queuing is normal, especially if all requests still manage to start as expected based on the requirements. If you see recurring queuing at particular times, check with the users to see if that is going to be a problem.
- Start low! If you're unsure of what setting should be used, start with a low number of processes. Check if any queuing occurs and if the users start complaining.
Sleep Seconds
From the Documentation: " The sleep time for your manager during this work shift. Sleep time is the number of seconds your manager waits between checking the list of pending concurrent requests (concurrent requests waiting to be started)"- The documentation is inaccurate - It should clearly state that it's effective for each manager process - i.e. if you have 5 concurrent manager processes for the Standard Manager and the "Sleep Seconds" setting is set to 30, then the average time between checks for pending requests (if all managers are idle) is 30 / 5 = 6 seconds.
- A manager process sleeps only when there are no pending requests - The manager process checks the requests queue immediately after it has processed the last request it fetched. A common misconception is that if the rate of incoming requests is very high, the "Sleep Seconds" should be low to process all of them quickly. Not true! If the rate of incoming requests is high, there is a good chance some requests will be executing at any given time. So, when they complete, the requests queue will be checked immediately and the new requests will be started.
- What value to use? - Calculate it! Three parameters are important to estimate the "Sleep Seconds" (S) setting: the number of manager processes (N), the average utilization level (U) of concurrent managers (this setting will be explained later), and the average time of how long the request is allowed to be pending (T). As "Sleep Seconds" are effective only for the idle processes, it can be calculated using the following: S = N * (1 - U) * T.
- Example 1: if N = 5 processes, U= 20%, T=20 seconds - let's calculate the "Sleep Seconds" setting: S = 5 * (1 - 0.2) * 20 = 5 * 0.8 * 20 = 80 seconds. It seems high, but think about it - if the average utilization of 5 processes is 20%, then there are 4 idle processes at any given time. Each of these will have a sleep interval of 80 seconds, so on average the requests queue will be checked every 20 seconds.
- Example 2: if N = 3 processes, U= 90%, T=20 seconds: S = 3 * (1 - 0.9) * 20 = 3 * 0.1 * 20 = 6 seconds. This example reveals a problem as the calculated "Sleep Seconds" are lower than the requirement we have set - this means the requirement can't be reached with the number of running processes. Think about it - we have 3 processes each utilized 90% of time; it's impossible to meet the 20 seconds goal because all managers are busy most of the time. There simply aren’t enough processes to execute the incoming requests. The defined requirements can be reached only if at least one manager process is idle. This scenario also describes a "perfect world", where all but one manager is busy, so all new requests are picked up in time and the processing overhead of the idle manager processes is minimal.
Cache Size
From the Documentation: " The number of requests your manager remembers each time it reads which requests to run"- Almost useless setting - Unless you have a manager with only one running process. If multiple manager processes are running, there is a good chance that most of the cached requests will be processed (remember, the processes don't coordinate the work - they compete the work) by other manager processes while the first request is running.
- Example: There are 10 manager processes, and 10 requests are submitted. One of the manager processes starts executing the 1st request, the other managers start running the remaining requests. So, by the time the request completes all the cached requests will be obsolete, but the manager process will try to lock the corresponding rows in FND_CONCURRENT_REQUESTS table anyway, and will fail for all 9 requests. It will then immediately query the queue to check if more requests are pending.
- I think it's best to set "Cache Size" setting to 1 so the hardware resources aren't spent on trying to lock the processed requests, but rather on checking the requests queue.
- Request priorities are cached too - If you have a cache size greater than 1, keep in mind the request priorities are cached too. If the priority is changed for a cached request, the manager process will not notice it.


