1. Introduction
Recently Pythian's Cassandra team worked on one customer's request to copy data of several Cassandra tables between two Cassandra clusters (not Cassandra data centers). The original approach we used to copy data is through Cassandra COPY TO/FROM commands because the size of the data to be copied is not large (several hundred mega-bytes per table). The execution of the commands was successful, but for one of the tables that we did data copy, the application complained about missing data. We examined the data for that table using Cassandra cqlsh utility and found no discrepancy. After a further discussion with the customer, we realized that the source tables were created and manipulated by a Thrift based application and the application can dynamically create different columns for different rows, although each row does share a common set of statically defined columns. It is the data in these dynamic columns that are missing during the data copy process. We addressed the issue, but in the end we felt that we should write something about Cassandra data migration from Thrift to CQL because this is quite a common problem faced by many existing Cassandra users right now, considering that Cassandra is gradually phasing out Thrift and replacing it with CQL. This post is the first part of a three-post series. In this post (Part 1), we're going to dive into the details of Cassandra storage engine (pre-3.0 version) and explore some fundamental concepts that are key to better understanding the discussion in the following posts. In the next post ( Part 2), we're going to explore how Cassandra tables can be defined statically, dynamically, or in a mixed mode in Thrift and what the corresponding table definition in CQL are. In the last post ( Part 3), we'll present an effective approach to migrate dynamically generated data in Thrift into a statically defined CQL table, without suffering any data loss.1.1. Cassandra Transition from Thrift to CQL API
Apache Thrift is a software framework developed at Facebook for "scalable cross-language services development". In early days of Cassandra, Thrift base API was the only method to develop Cassandra client applications. But with the maturity of CQL (Cassandra query language), Cassandra is gradually moving away from Thrift API to CQL API. Along with this trend,- Thrift based client drivers are not officially supported.
- Thrift API will not get new Cassandra features; it exists simply for backward compatibility purpose.
- CQL based “cqlsh” utility is replacing thrift based “cassandra-cli” utility as the main command-line tool to interact with Cassandra.
2. Overview of Internal Cassandra Data Storage Structure
Please note that since Cassandra 3.0, the underlying storage engine for Cassandra has gone through a lot of changes. The discussion in this post series is for pre-3.0 Cassandra (v 2.2 and before). At very high level, a Cassandra table (or column family by old term) can be seen as a map of sorted map in the following format *: [code language="sql"] Ma<RowKey, SortedMap<ColumnKey, ColumnValue>> [/code] A graphical representation looks like below: Please note that although there are more complex structures such as Super Column and Composite Column, the basic idea remains the same and the representation above is good enough for us to describe the problem in this document. Internally, such a storage structure is where both Thrift and CQL APIs are based. The difference is that Thrift API manipulates the storage structure directly, but CQL API does so through an abstraction layer and expresses the data to user in a tabular form similar to what SQL does for a relational database. In order to make this clearer, let’s use an example to compare the outputs between cassandra-cli and cqlsh command utilities, which are based on Thrift and CQL protocols separately. The table schema is defined as below (in CQL format): [code language="sql"] CREATE TABLE song_tags ( id uuid, tag_name text, PRIMARY KEY (id, tag_name) ) WITH COMPACT STORAGE [/code] This simple table is used to maintain the song tags. After inserting several rows in this table, we examined the table content using both Thirft based "
cassandra-cli" utility and CQL based "
cqlsh" utility. The result is as below:
Please note that although there are more complex structures such as Super Column and Composite Column, the basic idea remains the same and the representation above is good enough for us to describe the problem in this document. Internally, such a storage structure is where both Thrift and CQL APIs are based. The difference is that Thrift API manipulates the storage structure directly, but CQL API does so through an abstraction layer and expresses the data to user in a tabular form similar to what SQL does for a relational database. In order to make this clearer, let’s use an example to compare the outputs between cassandra-cli and cqlsh command utilities, which are based on Thrift and CQL protocols separately. The table schema is defined as below (in CQL format): [code language="sql"] CREATE TABLE song_tags ( id uuid, tag_name text, PRIMARY KEY (id, tag_name) ) WITH COMPACT STORAGE [/code] This simple table is used to maintain the song tags. After inserting several rows in this table, we examined the table content using both Thirft based "
cassandra-cli" utility and CQL based "
cqlsh" utility. The result is as below:
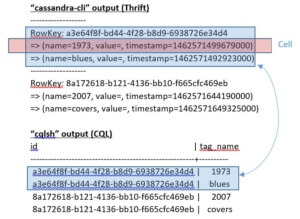 From the example above, it can be easily noticed that between Thrift and CQL, the terms “row” and “column” don’t share the same meaning and this causes some confusion when people do Thrift to CQL migration. For example,
From the example above, it can be easily noticed that between Thrift and CQL, the terms “row” and “column” don’t share the same meaning and this causes some confusion when people do Thrift to CQL migration. For example,
- In Thrift, one row means one data partition that is determined by the partition key definition. Each row has multiple columns, or more precisely “cells”. Each cell contains the time-stamp of when it is created. The name/key of the cell/column is not necessarily the name as defined in the table definition, especially when there are clustering column(s) defined (just as in the example above)
- In CQL, one row could be one partition, or could be one part of a partition. It really depends on how the partition key and cluster key are designed
- “CQL Row”, or simply "Row", refers to a row in CQL context
- “Storage Row”, refers to a row in Thrift context
- “Column”, refers to a column in both CQL or Thrift contexts
- “Cell” particularly refers to a column in Thrift context
- “Table” refers to a table in CQL context, or a column family in Thrift context
- "Partition" refers to a data partition determined by the hash key. In Thrift context, "Partition" and "Storage Row" has the same meaning. In CQL context, one "Partition" includes multiple "CQL Rows".
3. Compact Storage
In CQL, a table property, called for COMPACT STRORAGE, is created for backward compatibility. As the name suggests, tables created with this directive consumes less storage space compared with those created without this directive. To make this clear, we also uses an example to explain. Basically, two tables are created to keep track of the average student grades for classes in a school. The table definition for them are exactly the same except that one ( avg_grade) is defined without COMPACT STORAGE property, but another ( avg_grade2) does. The same records of data are also inserted into both tables, as below: [code language="sql"] CREATE TABLE avg_grade ( student_id int, class_id int, grade double, PRIMARY KEY (student_id, class_id) ) CREATE TABLE avg_grade2 ( student_id int, class_id int, grade double, PRIMARY KEY (student_id, class_id) ) WITH COMPACT STORAGE insert into avg_grade(student_id, class_id, grade) values (1, 1, 75.2); insert into avg_grade(student_id, class_id, grade) values (2, 1, 81.3); insert into avg_grade2(student_id, class_id, grade) values (1, 1, 75.2); insert into avg_grade2(student_id, class_id, grade) values (2, 1, 81.3); [/code] The statements are executed in cqlsh utility. The data is then flushed from memory to disk with “nodetool flush” command. After that, sstable2json utility is used to examine the contents of the SSTable data files for both tables. Below is the output: From the output above, we can see that tables NOT in compact storage mode has more cells within each Storage Row (e.g. the extra cell with empty value for clustering column “class”) and each Cell stores more metadata (e.g. the name of the “grade” column is added in each of the row). So just from storage perspective, having a table defined in compact storage could save quite some storage space, especially when we’re dealing with many columns and/or with complex column types like collections. In Thrift, tables are always stored in compact storage mode. In CQL, tables by default are stored in non-compact storage mode, unless the tables are defined with “COMPACT STRORAGE” property. As a result of this, CQL tables without “COMPACT STORAGE” property are not visible in Thrift based utilities like cassandra-cli. When a CQL table is defined with COMPACT STORAGE property, it gets the benefit of saving some disk space. However, there are also some caveats that need to pay attention to. For example:
From the output above, we can see that tables NOT in compact storage mode has more cells within each Storage Row (e.g. the extra cell with empty value for clustering column “class”) and each Cell stores more metadata (e.g. the name of the “grade” column is added in each of the row). So just from storage perspective, having a table defined in compact storage could save quite some storage space, especially when we’re dealing with many columns and/or with complex column types like collections. In Thrift, tables are always stored in compact storage mode. In CQL, tables by default are stored in non-compact storage mode, unless the tables are defined with “COMPACT STRORAGE” property. As a result of this, CQL tables without “COMPACT STORAGE” property are not visible in Thrift based utilities like cassandra-cli. When a CQL table is defined with COMPACT STORAGE property, it gets the benefit of saving some disk space. However, there are also some caveats that need to pay attention to. For example:
- It cannot have new columns added or existing columns dropped.
- If it has a compound primary key (multiple columns), then at most one column can be defined as not part of the key.
- It cannot have a column defined with non-frozen collection types.
- Note that for people who are not familiar with the concept of “frozen” vs. “non-frozen” collection, a frozen collection serializes all sub-components of the collection into one single value when stored, which is treated as a blob and the whole value must be updated once. On the contrary, A non-frozen collection allows updates on individual fields.

