@pub_identity_range : has a role when the subscribers also re-publish data because those republishing subscribers will synchronize data with their own subscribers and eventually will synchronize with the original publisher. It’s not a common practice but can happen , we won’t talk about it here.Let’s create the subscriptions and run the snapshot: [sourcecode language="sql"] use [Pub] exec sp_addmergesubscription @publication = N'Pub1', @subscriber = N'MYINSTANCE', @subscriber_db = N'sub1', @subscription_type = N'Push', @sync_type = N'Automatic', @subscriber_type = N'Global', @subscription_priority = 75, @use_interactive_resolver = N'False' Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_addmergepushsubscription_agent @publication = N'Pub1', @subscriber =@instance, @subscriber_db = N'sub1', @subscriber_security_mode = 1, @publisher_security_mode = 1; GO exec sp_addmergesubscription @publication = N'Pub1', @subscriber = N'MYINSTANCE', @subscriber_db = N'sub2', @subscription_type = N'Push', @sync_type = N'Automatic', @subscriber_type = N'Global', @subscription_priority = 75, @use_interactive_resolver = N'False' Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_addmergepushsubscription_agent @publication = N'Pub1', @subscriber =@instance, @subscriber_db = N'sub2', @subscriber_security_mode = 1, @publisher_security_mode = 1; GO -- Start snapshot agent Exec pub..sp_startpublication_snapshot 'pub1' GO Waitfor delay '00:00:15' GO [/sourcecode] Get snapshot agent output: Exec sp_MSenum_replication_agents @type = 1 GO
| dbname | name | status | publisher | publisher_db | publication | start_time | time | duration | comments |
| distribution | MYINSTANCE-Pub-Pub1-2 | 2 | MYINSTANCE | Pub | Pub1 | 20140118 18:05:30.750 | 20140118 18:05:40.523 | 10 | [100%] A snapshot of 1 article(s) was generated. |
| Session_id | Status | StartTime | EndTime | Duration | UploadedCommands | DownloadedCommands | ErrorMessages | PercentageDone | LastMessage |
| 3 | 2 | 1/18/2014 18:14:42 | 1/18/2014 18:14:54 | 13 | 0 | 0 | 0 | 100 | Applied the snapshot and merged 0 data change(s) (0 insert(s),0 update(s), 0 delete(s), 0 conflict(s)). |
| publication | article | subscriber | subscriber_db | range_begin | range_end | is_pub_range | next_range_begin | next_range_end |
| Pub1 | tbl_pub | MYINSTANCE | Pub | 1 | 101 | 0 | 101 | 201 |
| Pub1 | tbl_pub | MYINSTANCE | sub2 | 201 | 301 | 0 | 301 | 401 |
| Pub1 | tbl_pub | MYINSTANCE | sub1 | 401 | 501 | 0 | 501 | 601 |
| Pub1 | tbl_pub | MYINSTANCE | sub2 | 601 | 1601 | 1 | 1601 | 2601 |
| Pub1 | tbl_pub | MYINSTANCE | sub1 | 2601 | 3601 | 1 | 3601 | 4601 |
| Node | name | definition |
| Publisher | repl_identity_range_21A0E50F_D0F6_4E43_9FE1_349C1210247F | ([col1]>=(1) AND [col1](101) AND [col1]<=(201)) |
| Sub1 | repl_identity_range_21A0E50F_D0F6_4E43_9FE1_349C1210247F | ([col1]>(401) AND [col1](501) AND [col1]<=(601)) |
| Sub2 | repl_identity_range_21A0E50F_D0F6_4E43_9FE1_349C1210247F | ([col1]>(201) AND [col1](301) AND [col1]<=(401)) |
| publication | article | subscriber | subscriber_db | range_begin | range_end | is_pub_range | next_range_begin | next_range_end |
| Pub1 | tbl_pub | MYINSTANCE | Pub | 4601 | 4701 | 0 | 4701 | 4801 |
exec sys.sp_MSrefresh_publisher_idrange '[dbo].[tbl_pub]', '95208516-4B98-451D-B264-C1F27B20449A', '21A0E50F-D0F6-4E43-9FE1-349C1210247F', 2, 1Some people complained about this, but, no dice! https://connect.microsoft.com/SQLServer/feedback/details/330476/identity-range-not-working-for-merge-replication-in-sql-server-2005
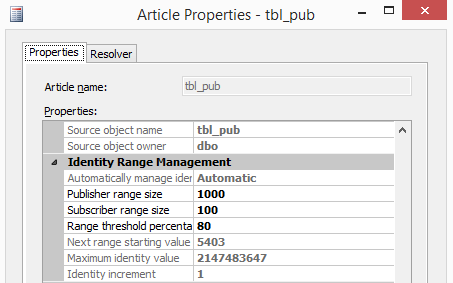{kind=link}