Isolation levels are a rare subject in MySQL literature. The documentation provides a terse description and focuses mainly on locking issues, but does not discuss the semantics of each isolation level. This is not only a problem that affects MySQL documentation but also the SQL standard itself. Both the lack of documentation and the absence of a deeper description of the expected behavior in the SQL standard make
isolation levels a topic that is more assumed than known by database administrators and developers. In this blog post, I aim to help you understand how the default isolation level in MySQL works and show you some surprising facts about it. But first let's see how isolation levels are described in the standard: "The transaction isolation level of a SQL-transaction defines the degree to which the operations on SQL-data, or schemas in that SQL-transaction are affected by the effects of and can affect operations on SQL-data or schemas in concurrent SQL-transactions". To put it in plain words, isolation levels define how concurrent transactions interact while modifying data. MySQL uses
Repeatable-read as the default level. In the standard, this level forbids
dirty reads (non committed data) and
non repeatable reads (executing the same query twice should return the same values) and allows
phantom reads (new rows are visible). But MySQL implements it in a different way. Let's see how it is implemented with some examples.
 Now we move to Session Red and insert two rows into the table. We commit the transaction to make sure data is updated.
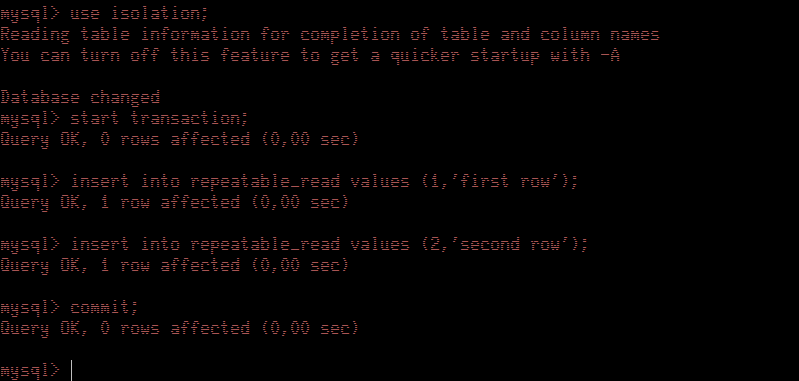
Now we move to Session Red and insert two rows into the table. We commit the transaction to make sure data is updated.
 Next we check what data is retrieved in Session Blue.
Next we check what data is retrieved in Session Blue.
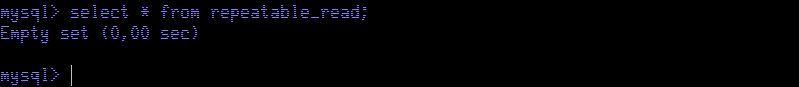 As we can see,
repeatable-read in MySQL avoids
Phantom Reads, as rows are not retrieved. This is more restrictive than the standard description of the isolation level. But, what happens if we try to update the table contents? Our intuition is that we should not update any rows.
As we can see,
repeatable-read in MySQL avoids
Phantom Reads, as rows are not retrieved. This is more restrictive than the standard description of the isolation level. But, what happens if we try to update the table contents? Our intuition is that we should not update any rows.
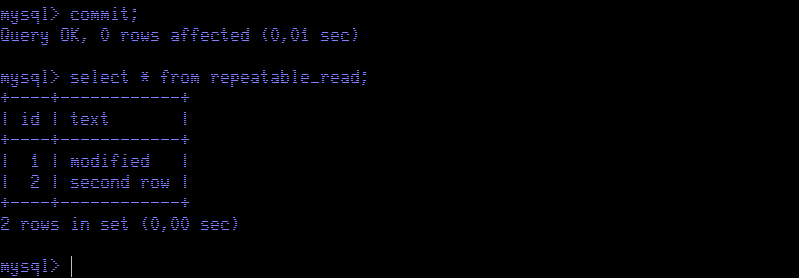
 Surprise! The update command tells us that one row matched and one row was changed. Let's select table contents to view what is happening.
Surprise! The update command tells us that one row matched and one row was changed. Let's select table contents to view what is happening.
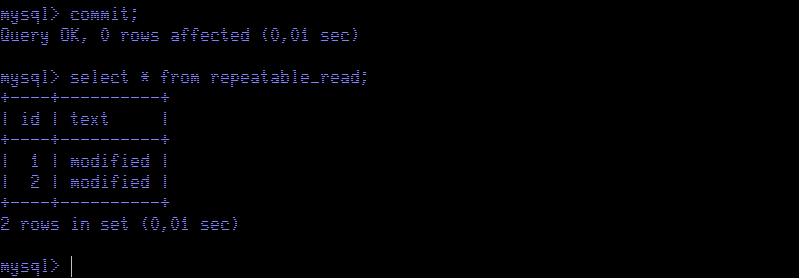
 We see just one row, the row that was modified by the update executed before. This is quite unexpected and counter-intuitive as the table never had one single row committed; we inserted and committed two rows. We are seeing a view of the table that never existed. As expected, when we commit, we see both rows, the one we modified and the other that was inserted before in Session Red.
We see just one row, the row that was modified by the update executed before. This is quite unexpected and counter-intuitive as the table never had one single row committed; we inserted and committed two rows. We are seeing a view of the table that never existed. As expected, when we commit, we see both rows, the one we modified and the other that was inserted before in Session Red.
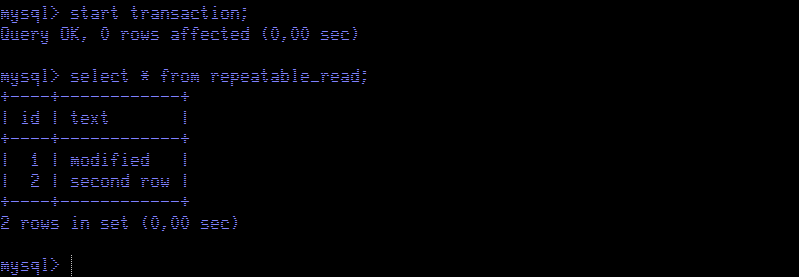 Back in Session Red, we will run a transaction to update the contents of the table. Note:
Phantom reads only affect new rows, not the ones already existing.
Back in Session Red, we will run a transaction to update the contents of the table. Note:
Phantom reads only affect new rows, not the ones already existing.
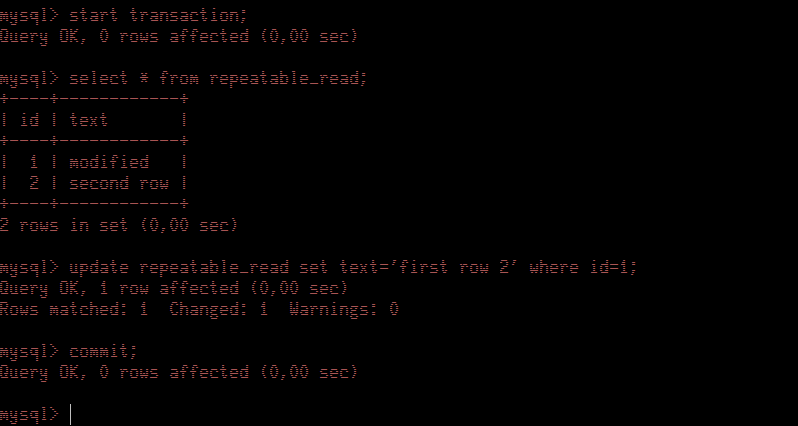 Let's find what Session Blue retrieves and what can update.
Let's find what Session Blue retrieves and what can update.
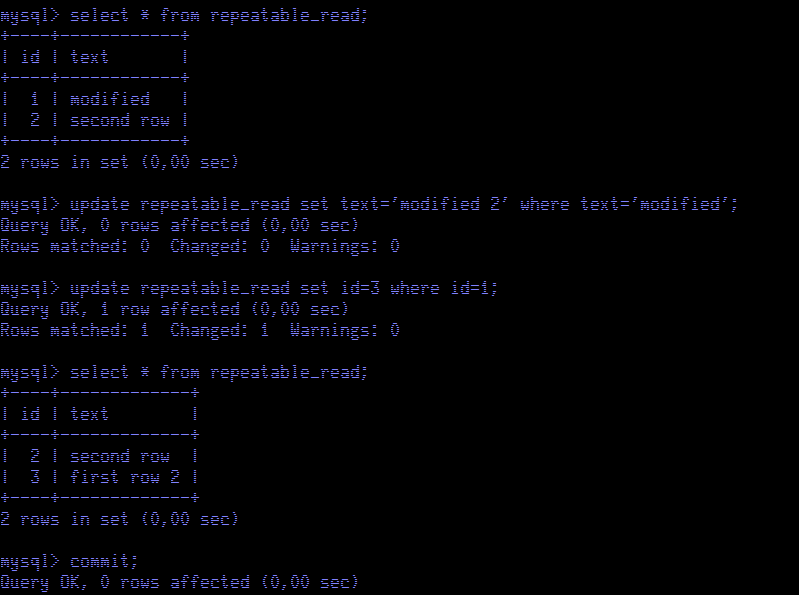 Initially, we see the table unchanged. But no rows matched when we try to update the table using the data we retrieved in the select. We see one row with value "modified" for the
text column, but the update finds no rows. When we update the table using a column value that was not modified by any transaction, in this case
id, then we are able to proceed. Now we see the new value for the
text column.
Initially, we see the table unchanged. But no rows matched when we try to update the table using the data we retrieved in the select. We see one row with value "modified" for the
text column, but the update finds no rows. When we update the table using a column value that was not modified by any transaction, in this case
id, then we are able to proceed. Now we see the new value for the
text column.
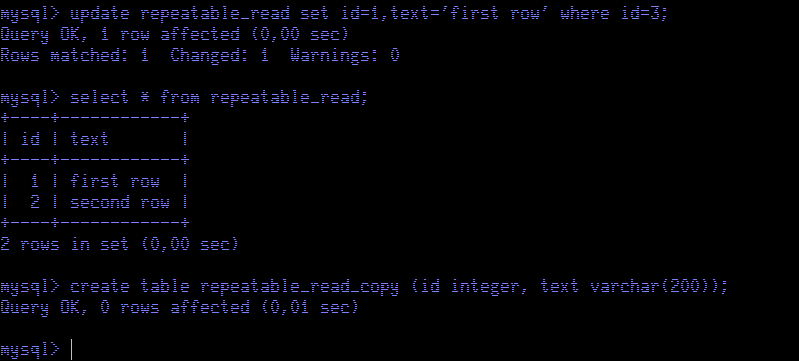 As usual we start a new transaction and we retrieve table contents to create the snapshot.
As usual we start a new transaction and we retrieve table contents to create the snapshot.
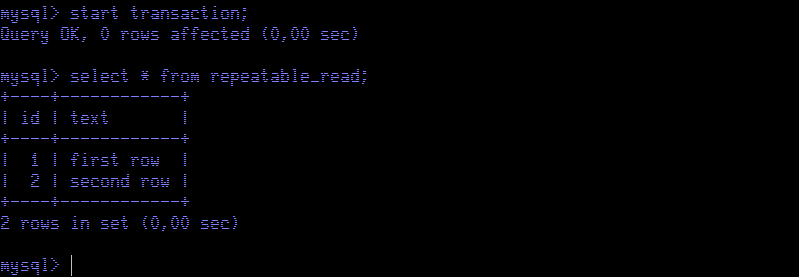 Now we go back to Session Red to update the contents of the whole table.
Now we go back to Session Red to update the contents of the whole table.
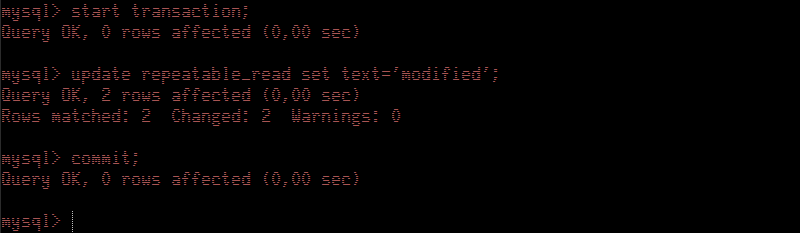 Returning to Session Blue, we "clone" the contents of the table
repeatable_read to
repeatable_read_copy table using an
insert into ... select statement. After that we retrieve the values of both tables using a select.
Returning to Session Blue, we "clone" the contents of the table
repeatable_read to
repeatable_read_copy table using an
insert into ... select statement. After that we retrieve the values of both tables using a select.
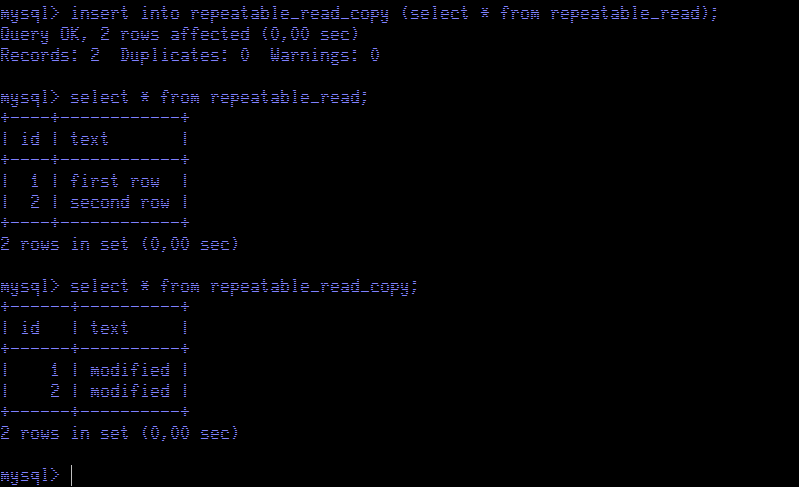 The values of rows inserted into the copy table using an
insert into ... as select is
different than the values of rows retrieved using a regular
select statement. Once we commit the transaction, as expected, we are able to see the modified data in the original table too.
The values of rows inserted into the copy table using an
insert into ... as select is
different than the values of rows retrieved using a regular
select statement. Once we commit the transaction, as expected, we are able to see the modified data in the original table too.
MySQL Repeatable-Read tests
We create two connections against a MySQL server. We will call them Session Blue and Session Red (The fact that these are the colors of FC Barcelona is purely coincidental). In Session Blue we will create the database isolation and the table repeatable_read, both will be required for this test.
No phantom reads... only phantom writes!
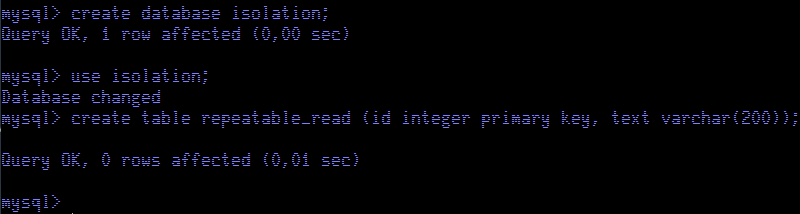
We start a transaction, verify current isolation level by checking the value of the variable tx_isolation, and retrieve the contents of repeatable_read table, this way we create a snapshot of that table for the whole transaction. Now we move to Session Red and insert two rows into the table. We commit the transaction to make sure data is updated.
Next we check what data is retrieved in Session Blue.
As we can see,
repeatable-read in MySQL avoids
Phantom Reads, as rows are not retrieved. This is more restrictive than the standard description of the isolation level. But, what happens if we try to update the table contents? Our intuition is that we should not update any rows.
Surprise! The update command tells us that one row matched and one row was changed. Let's select table contents to view what is happening.
We see just one row, the row that was modified by the update executed before. This is quite unexpected and counter-intuitive as the table never had one single row committed; we inserted and committed two rows. We are seeing a view of the table that never existed. As expected, when we commit, we see both rows, the one we modified and the other that was inserted before in Session Red.
More phantom writes!
Now we will begin another transaction and retrieve table contents. We retrieve table contents to create a snapshot (probably we should call it a version) of the table. Back in Session Red, we will run a transaction to update the contents of the table. Note:
Phantom reads only affect new rows, not the ones already existing.
Let's find what Session Blue retrieves and what can update.
Initially, we see the table unchanged. But no rows matched when we try to update the table using the data we retrieved in the select. We see one row with value "modified" for the
text column, but the update finds no rows. When we update the table using a column value that was not modified by any transaction, in this case
id, then we are able to proceed. Now we see the new value for the
text column.
WYSINWYW (What you see is NOT what you write)
We will return our table to the original values and we will create an additional table required for the next test. As usual we start a new transaction and we retrieve table contents to create the snapshot.
Now we go back to Session Red to update the contents of the whole table.
Returning to Session Blue, we "clone" the contents of the table
repeatable_read to
repeatable_read_copy table using an
insert into ... select statement. After that we retrieve the values of both tables using a select.
The values of rows inserted into the copy table using an
insert into ... as select is
different than the values of rows retrieved using a regular
select statement. Once we commit the transaction, as expected, we are able to see the modified data in the original table too.
Conclusions
After these tests, we have found about MySQL implementation of Repeatable-read isolation level:- When using just select statements is even more restrictive than SQL Standard, as Phantom Reads do not happen. Besides the snapshot is used for all tables and all rows, as we find while we use a mysqldump with --single-transaction.
- When the transaction modifies data, the behavior is a mix of Repeatable-read (rows not modified are not visible) and Read committed (modified rows are visible). We cannot say that this is not the standard as these situations are not described in it and do not fit in the three concurrency phenomena: Dirty Read, Non-repeatable Read and Phantom Read.
- When the transaction writes new data based on existing data, it uses the committed data, instead of the snapshot retrieved previously. This is valid both for modified and new rows, mimicking Read committed behavior.

