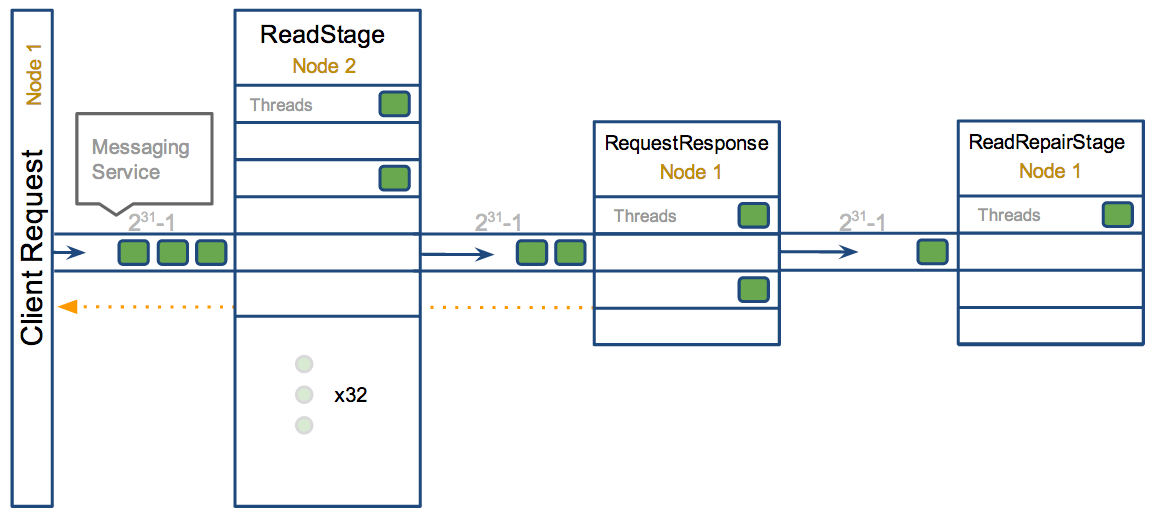
Cassandra is based off of a Staged Event Driven Architecture (SEDA). This separates different tasks in stages that are connected by a messaging service. Each like task is grouped into a stage having a queue and thread pool (ScheduledThreadPoolExecutor more specifically for the Java folks). Some stages skip the messaging service and queue tasks immediately on a different stage if it exists on the same node. Each of these queues can be backed up if execution at a stage is being over run. This is a common indication of an issue or performance bottleneck.To demonstrate take for example a read request:
For manual debugging this is the output given by
nodetool tpstats Pool Name Active Pending Completed Blocked All time blocked ReadStage 0 0 113702 0 0 RequestResponseStage 0 0 0 0 0 MutationStage 0 0 164503 0 0 ReadRepairStage 0 0 0 0 0 ReplicateOnWriteStage 0 0 0 0 0 GossipStage 0 0 0 0 0 AntiEntropyStage 0 0 0 0 0 MigrationStage 0 0 0 0 0 MemoryMeter 0 0 35 0 0 MemtablePostFlusher 0 0 1427 0 0 FlushWriter 0 0 44 0 0 MiscStage 0 0 0 0 0 PendingRangeCalculator 0 0 1 0 0 commitlog_archiver 0 0 0 0 0 InternalResponseStage 0 0 0 0 0 HintedHandoff 0 0 0 0 0 Message type Dropped RANGE_SLICE 0 READ_REPAIR 0 PAGED_RANGE 0 BINARY 0 READ 0 MUTATION 0 _TRACE 0 REQUEST_RESPONSE 0 COUNTER_MUTATION 0The description of the pool values (Active, Pending, etc) is defined in the table below. The second table lists dropped tasks by message type, for more information on that read below.
These are all available via JMX as well in:
org.apache.cassandra.request:type=*and
org.apache.cassandra.internal:type=*
with the attributes (relative to tpstats) being:
| MBean Attribute | tpstats name | Description |
|---|---|---|
| ActiveCount | Active | Number of tasks pulled off the queue with a Thread currently processing. |
| PendingTasks | Pending | Number of tasks in queue waiting for a thread |
| CompletedTasks | Completed | Number of tasks completed |
| CurrentlyBlockedTasks | Blocked | When a pool reaches its max thread count (configurable or set per stage, more below) it will begin queuing until the max size is reached. When this is reached it will block until there is room in the queue. |
| TotalBlockedTasks | All time blocked | Total number of tasks that have been blocked |
| Message Type | Stage | Notes |
|---|---|---|
| BINARY | n/a | This is deprecated and no longer has any use |
| _TRACE | n/a (special) | Used for recording traces (nodetool settraceprobability) Has a special executor (1 thread, 1000 queue depth) that throws away messages on insertion instead of within the execute |
| MUTATION | MutationStage | If a write message is processed after its timeout (write_request_timeout_in_ms) it either sent a failure to the client or it met its requested consistency level and will relay on hinted handoff and read repairs to do the mutation if it succeeded. |
| COUNTER_MUTATION | MutationStage | If a write message is processed after its timeout (write_request_timeout_in_ms) it either sent a failure to the client or it met its requested consistency level and will relay on hinted handoff and read repairs to do the mutation if it succeeded. |
| READ_REPAIR | MutationStage | Times out after write_request_timeout_in_ms |
| READ | ReadStage | Times out after read_request_timeout_in_ms. No point in servicing reads after that point since it would of returned error to client |
| RANGE_SLICE | ReadStage | Times out after range_request_timeout_in_ms. |
| PAGED_RANGE | ReadStage | Times out after request_timeout_in_ms. |
| REQUEST_RESPONSE | RequestResponseStage | Times out after request_timeout_in_ms. Response was completed and sent back but not before the timeout |
-Dcassandra.available_processorsto JVM_OPTS. Falls back to default of Runtime.availableProcessors
Performing a local read. Also includes deserializing data from row cache. If there are pending values this can cause increased read latency. This can spike due to disk problems, poor tuning, or over loading your cluster. In many cases (not disk failure) this is resolved by adding nodes or tuning the system.
| JMX beans: | org.apache.cassandra.request.ReadStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.request.ReadStage | |
| Number of threads: | concurrent_reads (default: 32) |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
When a response to a request is received this is the stage used to execute any callbacks that were created with the original request
| JMX beans: | org.apache.cassandra.request.RequestResponseStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.request.RequestResponseStage | |
| Number of threads: | number of processors |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Performing a local including:
| JMX beans: | org.apache.cassandra.request.MutationStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.request.MutationStage | |
| Number of threads: | concurrent_writers (default: 32) |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Performing read repairs. Chance of them occurring is configurable per column family with read_repair_chance. More likely to back up if using CL.ONE (and to lesser possibly other non-CL.ALL queries) for reads and using multiple data centers. It will then be kicked off asynchronously outside of the queries feedback loop, demonstrated in the diagram above. Note that this is not very likely to be a problem since does not happen on all queries and is fast providing good connectivity between replicas. The repair being droppable also means that after write_request_timeout_in_ms it will be thrown away which further mitigates this. If pending grows attempt to lower the rate for high read CFs:
ALTER TABLE column_family WITH read_repair_chance = 0.01;
| JMX beans: | org.apache.cassandra.request.ReadRepairStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.request.ReadRepairStage | |
| Number of threads: | number of processors |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
CounterMutation in 2.1, also counters changing dramatically so post 2.0 should consider this obsolete. Performs counter writes on non-coordinator nodes and replicates after a local write. This includes a read so can be pretty expensive. Will back up if the rate of writes exceed the rate that the mutations can occur. Particularly possible with CL.ONE and high counter increment workloads.
| JMX beans: | org.apache.cassandra.request.ReplicateOnWriteStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.request.ReplicateOnWriteStage | |
| Number of threads: | concurrent_replicates (default: 32) |
| Max pending tasks: | 1024 x number of processors |
| Alerts: | pending > 15 || blocked > 0 |
Post 2.0.3 there should no longer be issue with pending tasks. Instead monitor logs for a message:
Gossip stage has {} pending tasks; skipping status check ...
Before that change, in particular older versions of 1.2, with a lot of nodes (100+) while using vnodes can cause a lot of cpu intensive work that caused the stage to get behind. Been known to of been caused with out of sync schemas. Check NTP working correctly and attempt nodetool resetlocalschema or the more drastic deleting of system column family folder.
| JMX beans: | org.apache.cassandra.internal.GossipStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.GossipStage | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Repairing consistency. Handle repair messages like merkle tree transfer (from Validation compaction) and streaming.
| JMX beans: | org.apache.cassandra.internal.AntiEntropyStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.AntiEntropyStage | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Making schema changes
| JMX beans: | org.apache.cassandra.internal.MigrationStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.MigrationStage | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Operations after flushing the memtable. Discard commit log files that have had all data in them in sstables. Flushing non-cf backed secondary indexes.
| JMX beans: | org.apache.cassandra.internal.MemtablePostFlusher |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.MemtablePostFlusher | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Sort and write memtables to disk. A vast majority of time this backing up is from over running disk capability. The sorting can cause issues as well however. In the case of sorting being a problem, it is usually accompanied with high load but a small amount of actual flushes (seen in cfstats). Can be from huge rows with large column names. i.e. something inserting many large values into a cql collection. If overrunning disk capabilities, it is recommended to add nodes or tune the configuration.
| JMX beans: | org.apache.cassandra.internal.FlushWriter |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.FlushWriter | |
| Number of threads: | memtable_flush_writers (1 per data directory) |
| Max pending tasks: | memtable_flush_queue_size (default: 4) |
| Alerts: | pending > 15 || blocked > 0 |
Snapshotting, replicating data after node remove completed.
| JMX beans: | org.apache.cassandra.internal.MiscStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.MiscStage | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Responding to non-client initiated messages, including bootstrapping and schema checking
| JMX beans: | org.apache.cassandra.internal.InternalResponseStage |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.InternalResponseStage | |
| Number of threads: | number of processors |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Sending missed mutations to other nodes. Usually a symptom of a problem elsewhere so dont treat as root issue. Can use nodetool disablehandoff to prevent further saving. Can also use JMX (nodetool truncatehints) to clear the handoffs for specific endpoints or all of them with org.apache.cassandra.db:HintedHandoffManager operations. This must be followed up with repairs!
| JMX beans: | org.apache.cassandra.internal.HintedHandoff |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.HintedHandoff | |
| Number of threads: | max_hints_delivery_threads (default: 1) |
| Max pending tasks: | 231-1 |
| Alerts: | pending > 15 || blocked > 0 |
Measures memory usage and live ratio of a memtable. The pending should not grow beyond size of number of memtables (front ended by set to prevent duplicates). This can take minutes for large memtables.
| JMX beans: | org.apache.cassandra.internal.MemoryMeter |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.MemoryMeter | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
| Alerts: | pending > column_family_count || blocked > 0 |
Calculates the token ranges based on bootstrapping and leaving nodes. Instead of blocking this stage discards tasks when one already in progress so no value in monitoring
| JMX beans: | org.apache.cassandra.internal.PendingRangeCalculator |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.PendingRangeCalculator | |
| Number of threads: | 1 |
| Max pending tasks: | 1 |
(Renamed CommitLogArchiver in 2.1) Executes a command to copy (or user defined command) commit log files for recovery. Read more at DataStax Dev Blog
Alerts:pending > 15 || blocked > 0| JMX beans: | org.apache.cassandra.internal.commitlog_archiver |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.commitlog_archiver | |
| Number of threads: | 1 |
| Max pending tasks: | 231-1 |
Number of active repairs that are in progress. Will not show up until after a repair has been run so any monitoring utilities should be able to handle it not existing.
Alerts:pending > 1 || blocked > 0| JMX beans: | org.apache.cassandra.internal.AntiEntropySessions |
|---|---|
| org.apache.cassandra.metrics.ThreadPools.internal.AntiEntropySessions | |
| Number of threads: | 4 |
| Max pending tasks: | 231-1 |
Ready to handle massive data volumes with zero downtime?
{kind=link}