Introduction
This blog describes the best-practice approach in regards to the data ingestion from SQL Server into Hadoop. The case scenario is described as under:- Single table ingestion (no joins)
- No partitioning
- Complete data ingestion (trash old and replace new)
- Data stored in Parquet format
Pre-requisites
This example has been tested using the following versions:- Hadoop 2.5.0-cdh5.3.0
- Hive 0.13.1-cdh5.3.0
- Sqoop 1.4.5-cdh5.3.0
- Oozie client build version: 4.0.0-cdh5.3.0
Process Flow Diagram
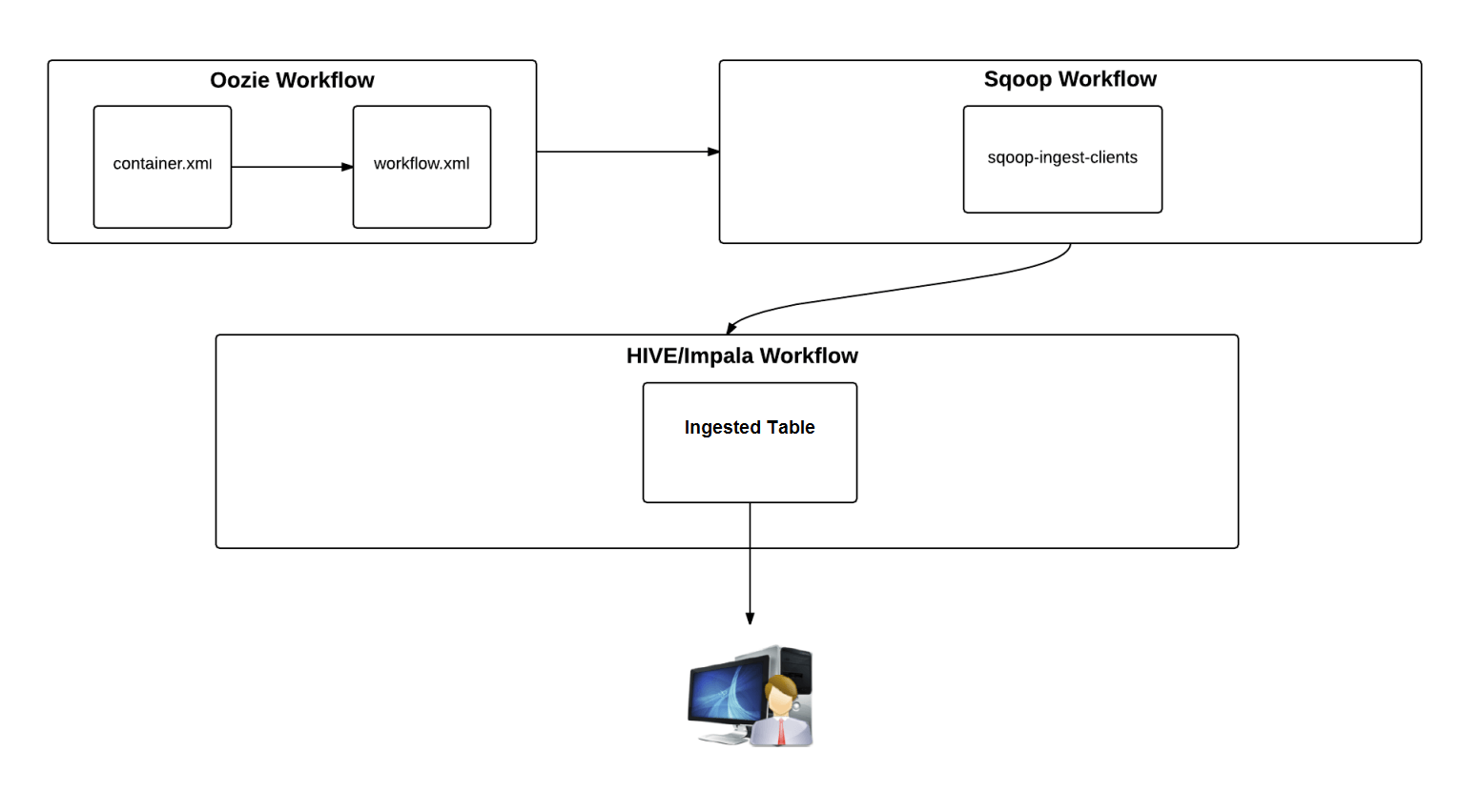
Configuration
- Create the following directory/file structure (one per data ingestion process). For a new ingestion program please adjust the directory/file names as per requirements. Make sure to replace the tag with your table name
<table_name>_ingest
+ hive-<table_name>
create-schema.hql
+ oozie-properties
<table_name>.properties
+ oozie-<table_name>-ingest
+ lib
kite-data-core.jar kite-data-mapreduce.jar sqljdbc4.jar
coordinator.xml impala_metadata.sh workflow.xml
- The ingestion process is invoked using an oozie workflow. The workflow invokes all steps necessary for data ingestion including pre-processing, ingestion using sqoop and post-processing.
oozie-<table_name>-ingest This directory stores all files that are required by the oozie workflow engine. These files should be stored in HDFS for proper functioning of oozie
oozie-properties This directory stores the <table_name>.properties. This file stores the oozie variables such as database users, name node details etc. used by the oozie process at runtime.
hive-<table_name> This directory stores a file called create-schema.hql which contains the schema definition of the HIVE tables. This file is required to be run in HIVE only once.
- Configure files under oozie-<table_name>-ingest
1. Download kite-data-core.jar and kite-data-mapreduce.jar files from https://mvnrepository.com/artifact/org.kitesdk 2. Download sqljdbc4.jar from https://msdn.microsoft.com/en-us/sqlserver/aa937724.aspx
3. Configure coordinator.xml. Copy and paste the following XML.
<coordinator-app name="<table_name>-ingest-coordinator" frequency="${freq}" start="${startTime}" end="${endTime}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2"> <action> <workflow> <app-path>${workflowRoot}/workflow.xml</app-path> <configuration> <property> <name>partition_name</name> <value>${coord:formatTime(coord:nominalTime(), 'YYYY-MM-dd')}</value> </property> </configuration> </workflow> </action> </coordinator-app>
4. Configure workflow.xml. This workflow has three actions:
a) mv-data-to-old – Deletes old data before refreshing new b) sqoop-ingest-<table_name> – Sqoop action to fetch table from SQL Server c) invalidate-impala-metadata – Revalidate Impala data after each refresh
Copy and paste the following XML.
<workflow-app name="<table_name>-ingest" xmlns="uri:oozie:workflow:0.2"><start to="mv-data-to-old" /><action name="mv-data-to-old"> <fs> <delete path='${sqoop_directory}/<table_name>/*.parquet' /> <delete path='${sqoop_directory}/<table_name>/.metadata' /> </fs><ok to="sqoop-ingest-<table_name>"/> <error to="kill"/> </action><action name="sqoop-ingest-<table_name>"> <sqoop xmlns="uri:oozie:sqoop-action:0.3"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <prepare> <delete path="${nameNode}/user/${wf:user()}/_sqoop/*" /> </prepare><configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration><arg>import</arg> <arg>--connect</arg> <arg>${db_string}</arg> <arg>--table</arg> <arg>${db_table}</arg> <arg>--columns</arg> <arg>${db_columns}</arg> <arg>--username</arg> <arg>${db_username}</arg> <arg>--password</arg> <arg>${db_password}</arg> <arg>--split-by</arg> <arg>${db_table_pk}</arg> <arg>--target-dir</arg> <arg>${sqoop_directory}/<table_name></arg> <arg>--as-parquetfile</arg> <arg>--compress</arg> <arg>--compression-codec</arg> <arg>org.apache.hadoop.io.compress.SnappyCodec</arg> </sqoop><ok to="invalidate-impala-metadata"/> <error to="kill"/> </action><action name="invalidate-impala-metadata"> <shell xmlns="uri:oozie:shell-action:0.1"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node><configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <exec>${impalaFileName}</exec> <file>${impalaFilePath}</file> </shell> <ok to="fini"/> <error to="kill"/> </action> <kill name="kill"> <message>Workflow failed with error message ${wf:errorMessage(wf:lastErrorNode())}</message> </kill><end name="fini" /></workflow-app>
5. Configure impala_metadata.sh. This file will execute commands to revalidate impala metadata after each restore. Copy and paste the following data.
#!/bin/bash export PYTHON_EGG_CACHE=./myeggs impala-shell -i <hive_server> -q "invalidate metadata <hive_db_name>.<hive_table_name>"
- Configure files under oozie-properties. Create file oozie.properties with contents as under. Edit the parameters as per requirements.
# Coordinator schedulings freq=480 startTime=2015-04-28T14:00Z endTime=2029-03-05T06:00Z
jobTracker=<jobtracker> nameNode=hdfs://<namenode> queueName=<queue_name>
rootDir=${nameNode}/user//oozie workflowRoot=${rootDir}/<table_name>-ingest
oozie.use.system.libpath=true oozie.coord.application.path=${workflowRoot}/coordinator.xml
# Sqoop settings sqoop_directory=${nameNode}/data/sqoop
# Hive/Impala Settings hive_db_name=<hive_db_name> impalaFileName=impala_metadata.sh impalaFilePath=/user/oozie/<table_name>-ingest/impala_metadata.sh
#impala_metadata.sh
# MS SQL Server settings db_string=jdbc:sqlserver://;databaseName=<sql_server_db_name> db_username=<sql_server_username> db_password=<sql_server_password> db_table=<table_name> db_columns=<columns>
- Configure files under hive-<table_name>. Create a new file create-schema.hql with contents as under.
DROP TABLE IF EXISTS ;CREATE EXTERNAL TABLE () STORED AS PARQUET LOCATION 'hdfs:///data/sqoop/<table_name>';
Deployment
- Create new directory in HDFS and copy files
$ hadoop fs -mkdir /user/<user>/oozie/<table_name>-ingest $ hadoop fs -copyFromLocal <directory>/<table_name>/oozie-<table_name>-ingest/lib /user/<user>/oozie/ <table_name>-ingest $ hadoop fs -copyFromLocal <directory>/<table_name>/oozie-<table_name>-ingest/ coordinator.xml /user/<user>/oozie/ <table_name>-ingest $ hadoop fs -copyFromLocal <directory>/<table_name>/oozie-<table_name>-ingest/ impala_metadata.sh /user/<user>/oozie/<table_name>-ingest $ hadoop fs -copyFromLocal <directory>/<table_name>/oozie-<table_name>-ingest/ workflow.xml /user/<user>/oozie/ <table_name>-ingest
- Create new directory in HDFS for storing data files
$ hadoop fs -mkdir /user/SA.HadoopPipeline/oozie/<table_name>-ingest $ hadoop fs -mkdir /data/sqoop/<table_name>
- Now we are ready to select data in HIVE. Go to URL https://<hive_server>:8888/beeswax/#query.
a. Choose existing database on left or create new. b. Paste contents of create-schema.hql in Query window and click Execute. c. You should now have an external table in HIVE pointing to data in hdfs://<namenode>/data/sqoop/<table_name>
- Create Oozie job
a. Choose existing database on left or create new. $ oozie job -run -config /home/<user>/<<directory>/<table_name>/oozie-properties/oozie.properties
Validation and Error Handling
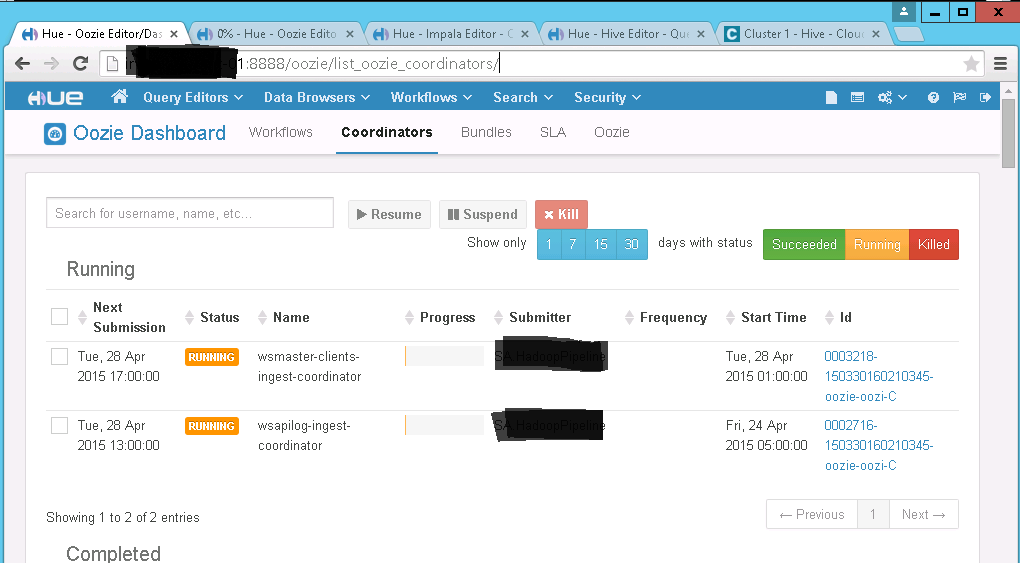
- At this point an oozie job should be created. To validate the oozie job creation open URL https://<hue_server>:8888/oozie/list_oozie_coordinators. Expected output as under. In case of error please review the logs for recent runs.
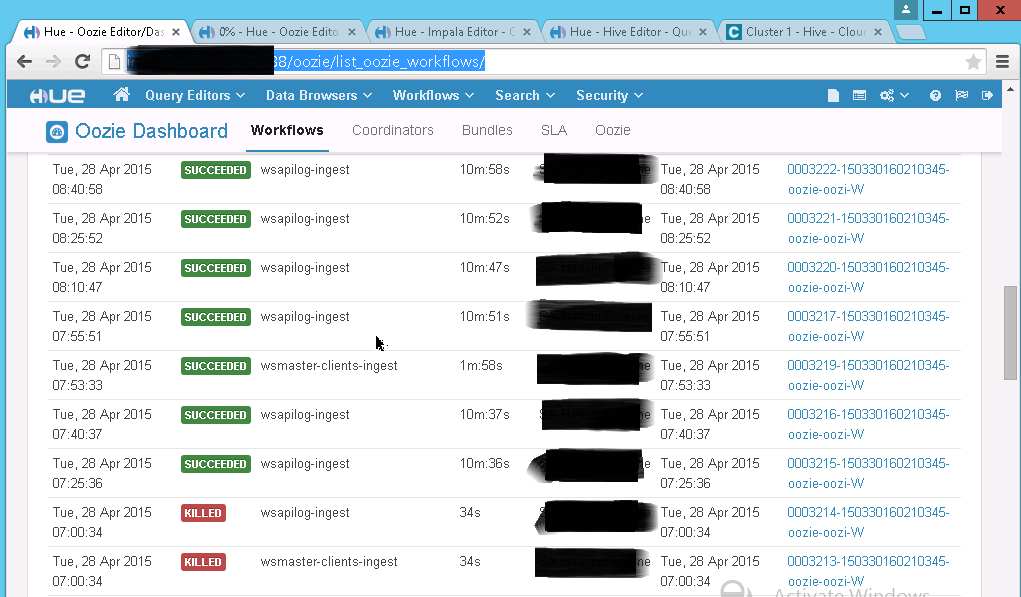
- To validate the oozie job is running open URL https://<hue_server>:8888/oozie/list_oozie_workflows/ . Expected output as under. In case of error please review the logs for recent runs.
- To validate data in HDFS execute the following command. You should see a file with *.metadata extension and a number of files with *.parquet extension.
$ hadoop fs -ls /data/sqoop/<table_name>/
- Now we are ready to select data in HIVE or Impala. For HIVE go to URL https://<hue_server>:8888/beeswax/#query For Impala go to URL https://<hue_server>:8888/impala Choose the newly created database on left and execute the following SQL - select * from <hive_table_name> limit 10 You should see the the data being outputted from the newly ingested data.
Share this
How to get the most value out of your SAP data (hint: you need a plan)
![]()
How to get the most value out of your SAP data (hint: you need a plan)
Sep 28, 2022 12:00:00 AM
6
min read
How Data Analytics Is Revolutionizing Project Management in 2025

How Data Analytics Is Revolutionizing Project Management in 2025
Apr 30, 2025 10:21:13 AM
4
min read
Data Literacy as an Accelerator

Data Literacy as an Accelerator
Apr 7, 2022 12:00:00 AM
2
min read
No Comments Yet
Let us know what you think