 I’ll provide a quick start tutorial for GraphQL in this article. We'll start with an overview and then go into a small use case involving movie dataset analysis (querying) hosted on a Mongo database to see how the GraphQL server interacts with database data.
I’ll provide a quick start tutorial for GraphQL in this article. We'll start with an overview and then go into a small use case involving movie dataset analysis (querying) hosted on a Mongo database to see how the GraphQL server interacts with database data.
The link contains additional information on the movie dataset.
Prerequisites
- Understanding containers and docker.
- Basic knowledge of Kubernetes (GKE) and commands.
- Basic knowledge of Mongo database and commands.
- Node JS.
Overview
Graph Query Language (GraphQL) is an API developed by Facebook. GraphQL follows the Schema Definition Language (SDL) framework. GraphQL supports numerous languages, including Javascript, Python, Java, C#, and others; further information can be found on the GraphQL Code Libraries.
The link has more information on GraphQL.
Why GraphQL?
Why would we need to use GraphQL when the REST API already offers a well-organized method for data transmission? Let's examine the advantages and reasons for selecting GraphQL over the REST API:
- Single endpoint for all the requests: Unlike rest API where we have multiple endpoints for data retrieval, GraphQL provides a single endpoint for data fetching.
- With a single request, several resources can be retrieved
- Avoids over-fetching and under-fetching issues.
The link [What’s the Difference Between GraphQL and REST] contains additional information about the uses of GraphQL and compares it to REST API
Architecture/Design
Let's have a look at the use case's architectural design.
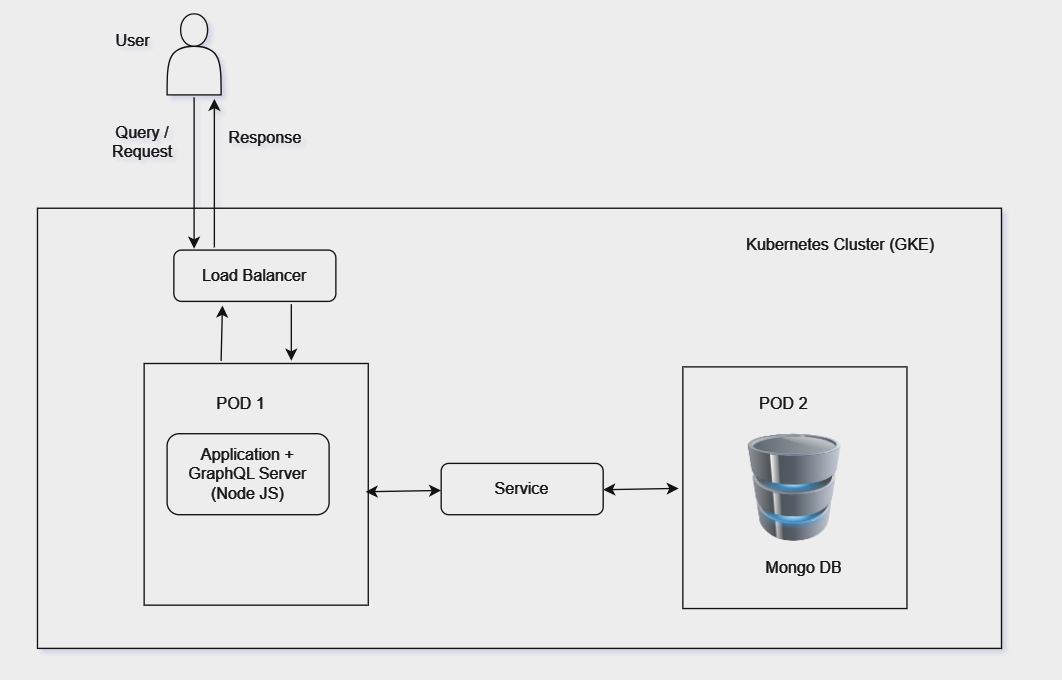
In GCP (GKE), we would set up a Kubernetes cluster. In the cluster, we would deploy the application (developed in Node JS) and database as deployments (pods). A load balancer is required for users to interact (externally, outside of the cluster) with the GraphQL application. We require a service that allows applications to access data in MongoDB.
Please note: The code snippets are simply meant to be used as examples, therefore recommended practices (such as persistent volumes etc.) might be absent.
I have divided the content into three different sections:
- Setting up a Mongo Database in the kubernetes cluster.
- Application development.
- Containerising the app and deployment in the kuberneter cluster.
Mongo Database Setup
If you already have a MongoDB cluster, you may skip the following MongoDB setup. Please make sure to include the movie dataset in your cluster.
Assuming the Kubernetes cluster is already configured, let's look at how to configure MongoDB in a Kubernetes cluster.
Steps:
1. Activate the cloud shell (or use cloud SDK).
2. Copy and paste the connect command from the cluster into the cloud shell. This creates the kubeconfig entry.
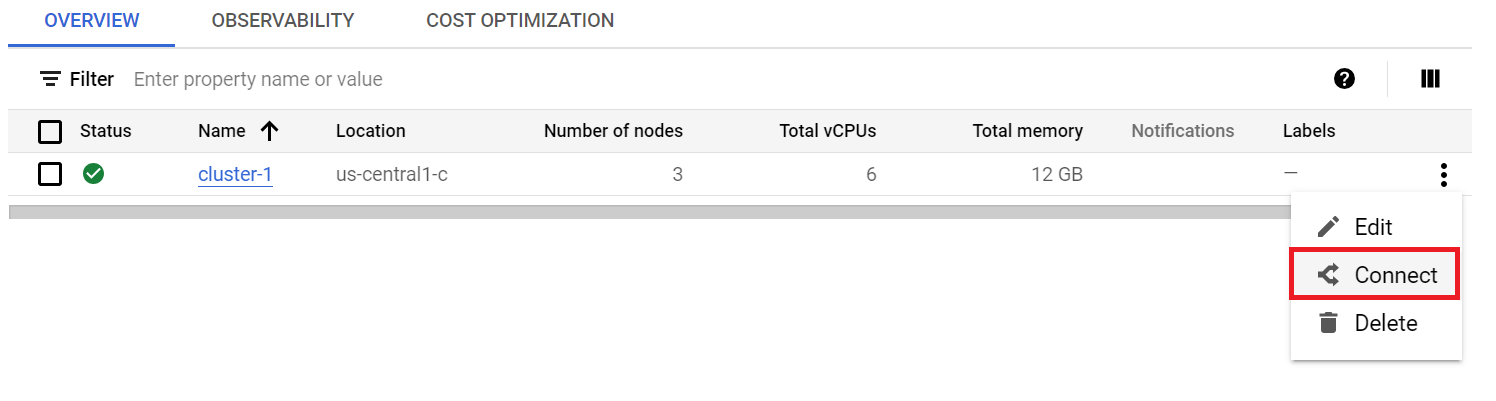

Now we can run Kubernetes commands to deploy the PODs and service.
3. Let’s take a look at the pod and service yaml file.
Pod:
apiVersion: v1
kind: Pod
metadata:
labels:
app: mongodb
name: mongodb
spec:
containers:
- image: mongo
name: mongodb
ports:
- containerPort: 27017
restartPolicy: Always
status: {}
Service:
apiVersion: v1
kind: Service
metadata:
name: mongodb-service
labels:
app: mongodb
name: mongodb
spec:
ports:
- port: 27017
targetPort: 27017
clusterIP: None
selector:
app: mongodb
You would receive outcomes similar to the one in the below picture after creating the pod and service -

4. Now that the Mongo database is running in a pod, let's load some test data. For demonstration purposes, I will manually load data for one collection.
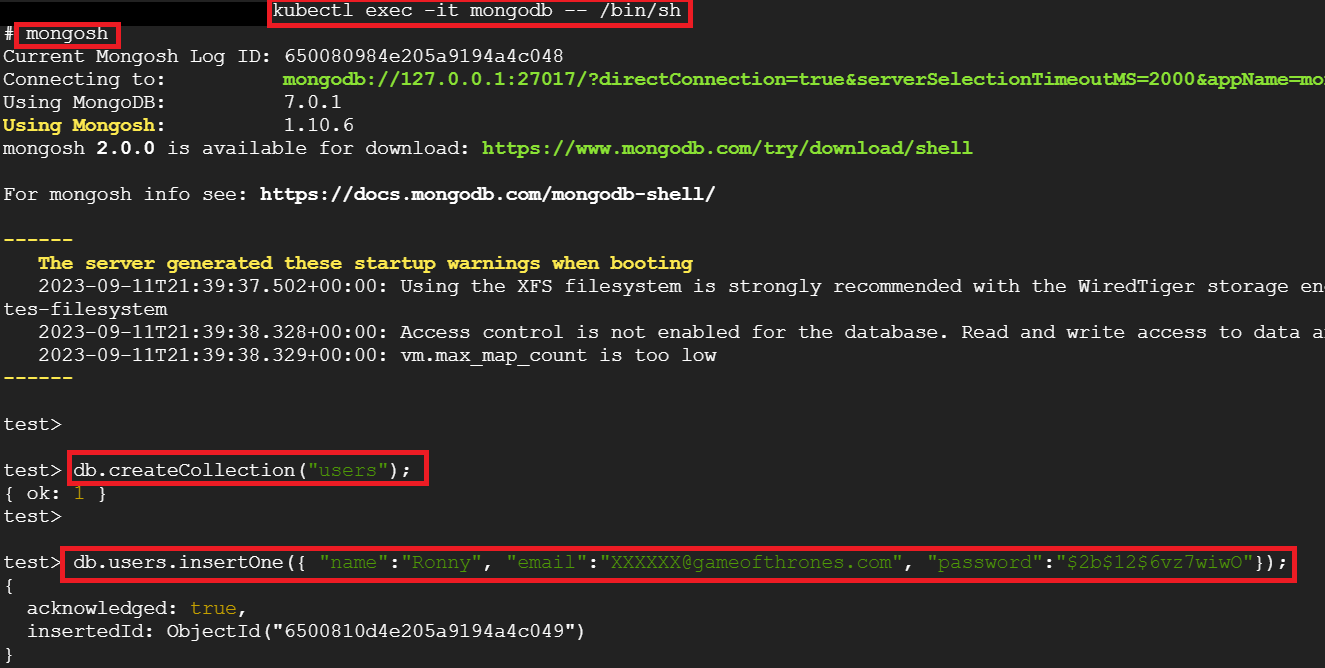
4.1 Login to the pod/container: kubectl exec -it mongodb -- /bin/sh
4.2 Login to Mongo database: mongosh
4.3 Make a collection and add data to it.
5. Let's quickly test the connection and query data in MongoDB from another pod.
5.1 Spin up a new mongo db pod (test pod) for validation purposes.
5.2 Login to test pod
5.3 Query the users collection using the MongoDB service.
Commands:
kubectl run test-mongodb --image=mongo
kubectl get pods
kubectl get service
kubectl exec -it test-mongodb -- /bin/sh
mongosh mongodb://mongodb-service:27017
db.users.find({'name' : 'Ronny'});
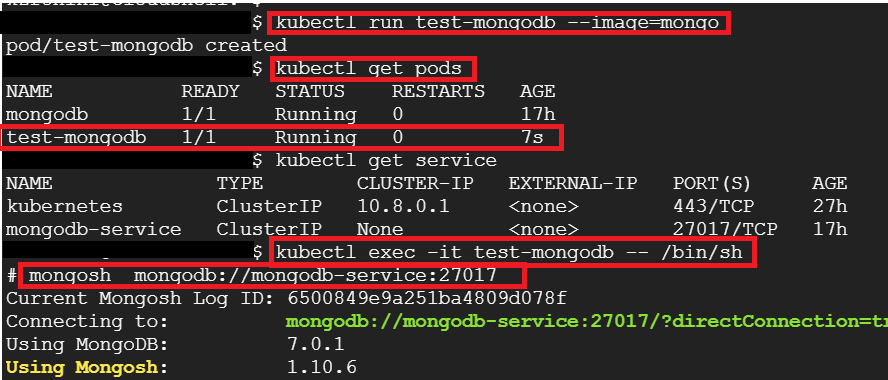
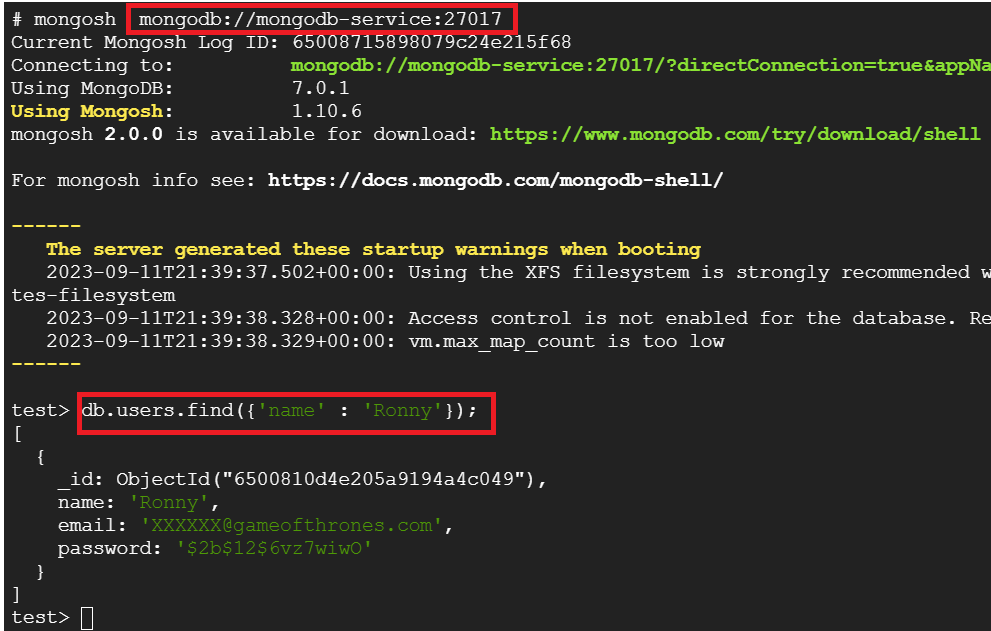
As we can see, we can connect to MongoDB from another pod and query the data. This completes the installation of MongoDB in a Kubernetes cluster and the creation of a service to access it.
Now that we've finished configuring MongoDB. In Part 2, let's get started on developing the application.
MongoDB Database Consulting Services
Ready to optimize your MongoDB Database for the future?
Share this
Share this

How to Back Up and Restore a Set of Collections in MongoDB Atlas
Difference between Oracle's table and Mongo's collection
