On this page
Share this
Share this
Apache beam pipelines With Scala: Part 2 - Side Input
![]()
Apache beam pipelines With Scala: Part 2 - Side Input
Dec 12, 2017 12:00:00 AM
3
min read
Building a custom routing NiFi processor with Scala
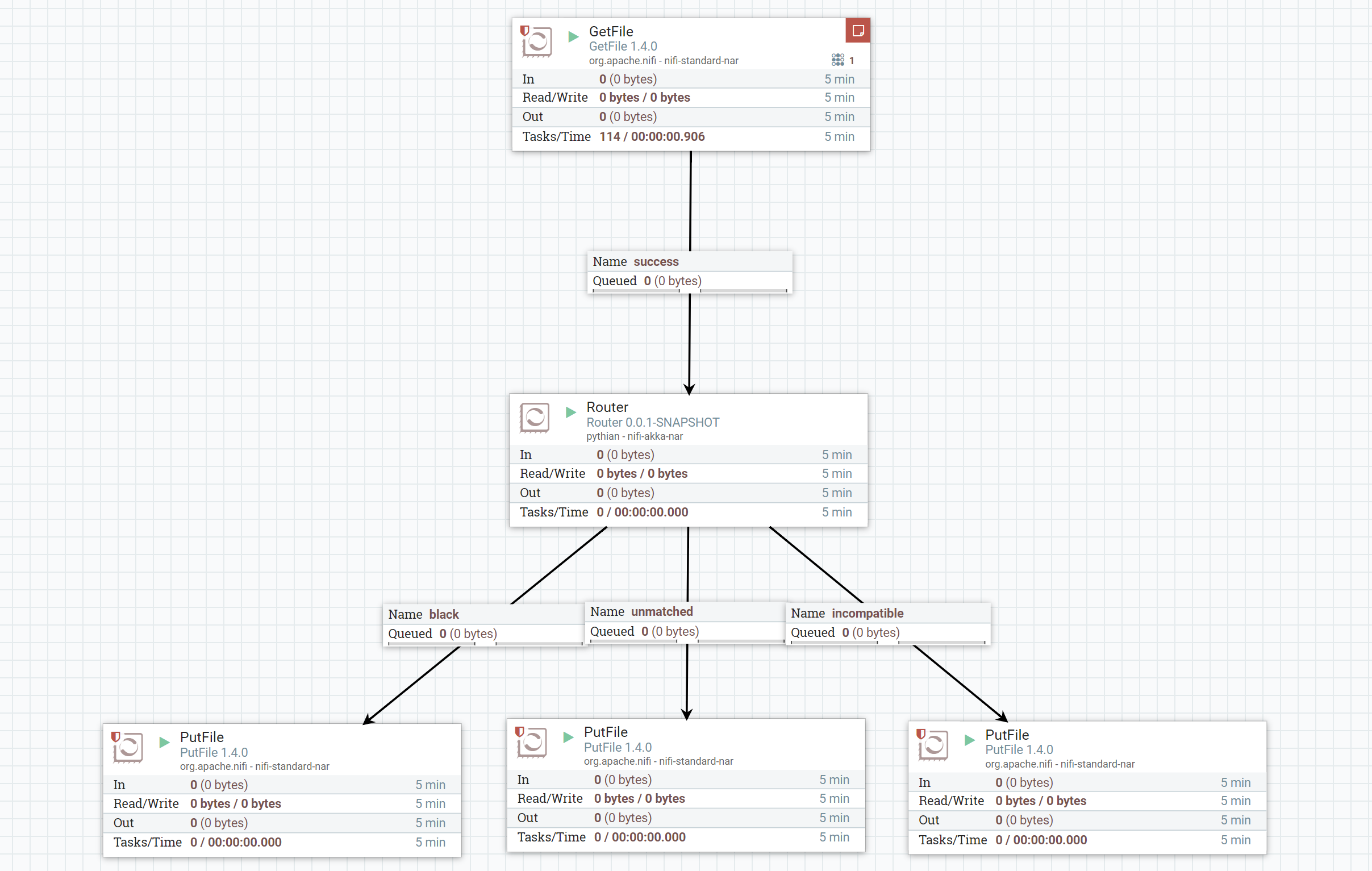
Building a custom routing NiFi processor with Scala
Jan 4, 2018 12:00:00 AM
4
min read
Creating dynamic tasks using Apache Airflow
![]()
Creating dynamic tasks using Apache Airflow
Apr 24, 2018 12:00:00 AM
7
min read