 If you haven't read part 4, please click here to get started.
If you haven't read part 4, please click here to get started.
Data Handling and Recovery
14. Backup and Data Recovery
Regularly back up data and implement data recovery procedures to ensure data integrity and system availability. In our scenario, the core state of our solution is the model itself, the Cognitive Search index and the source data in the Azure storage data lake. The LLM is hosted by Azure so we don’t have to worry about that. Then the Cognitive Search index can always be recomputed from the contents in the data lake.
So ultimately, what we need to keep safe most of all is the contents of the data lake and for this we just need to leverage the included capabilities of Azure storage itself. We can make sure to have the right permissions to the data lake, enable versioning of files and select at the very least zone-redundant storage.
15. High Availability and Disaster Recovery
We also want our solution to be resilient to failures and comply with our availability SLAs for high availability and disaster recovery. Let’s break these down.
In terms of high availability, we can let Azure do most of the work by making sure all the components are zone-redundant.
Things get a bit trickier when we start discussing disaster recovery. For DR we have to first decide how we’re going to manage the state of the DR environment. Usually we have 3 approaches:
- Hot DR: we would have all the components up and running in a separate region and data has to be replicated between components that persist any storage like databases or storage containers. This option will give you maximum speed to recover but you need to have more idle resources deployed and depending on your architecture, this might have a base fixed cost.
- Warm DR: we don’t deploy all the components of the architecture but we do have replication for all components that store data. In the event of a disaster your data is ready to go and you only need to deploy the stateless application resources. This is a half-way solution that strikes a balance between cost and speed of recovery.
- Cold DR: we only have an empty virtual network on the DR region and connectivity configured. In the event of a disaster we need to do full geo-recovery of any data and then deploy all other components. Cheapest option but takes longest to recover.
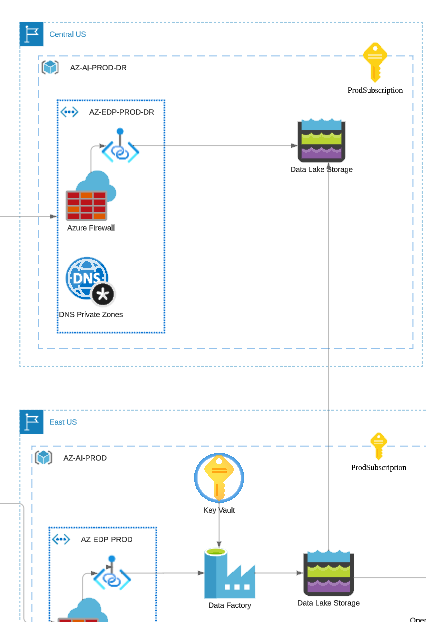
For our scenario we are going to go with a Warm DR, and as we mentioned previously, the source state of our LLM is the contents of the data lake storage. With that storage geo-replicated we could just recompute the Cognitive Search index and re-deploy all the other stateless components like the LLM model and the functions.
Updating the architecture, I will zoom in here on our new warm DR setup in Central US:
Thanks for reading! In my next blog, I'll cover model management and improve, and conclude the series.
Share this
Share this
