This post is the continuation of the previous post, Cassandra 101: Understanding What Cassandra Is, in which I’ll highlight a series of topics related to Cassandra for beginners.
Replication factor
The replication factor in Cassandra can be defined as the number of copies of data present in the different nodes in the cluster. Cassandra is highly available because of replication and is set at the KEYSPACE level.
Example:
If we have a three-node Cassandra cluster with replication factor 3, then the data will be available in all the three nodes. So, in this case, we can get availability even if we lose two nodes. Hence the replication factor is the one that gives us high availability in Cassandra.
The data will be stored in the cluster based on the hash value of the partition key. If the data’s hash value falls under the particular token range, it will be sent to that particular node. This node behaves as the primary token range. The storage of remaining replicas of data among the nodes can be described by using “Replication Strategies”.
Replication strategies
There are two types of replication strategies. They are:
- SimpleStrategy
- NetworkTopologyStrategy
Simple strategy
This strategy stores the data on consecutive nodes starting with the node with the primary token range. In this case, it doesn’t place the data in a different rack or datacenter. Partitioners determine the node where the first replica will be placed. The remaining replicas are arranged in the ring clockwise according to the range of tokens. So, if we encounter an issue with that particular rack, we can’t access the data as all the replicas are in the same rack. Therefore, this strategy isn’t for production deployments.
Creating keyspace using SimpleStrategy
CREATE KEYSPACE <keyspace_name> WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: <no_of_replicas>};
Ex: CREATE KEYSPACE pythian WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: 3};
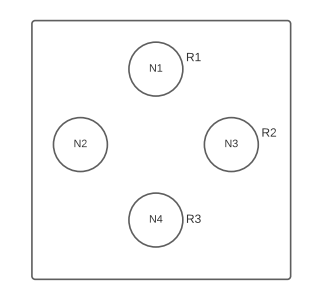
In the above example, we created a keyspace called Pythian using SimpleStrategy with replication factor 3. The data inserted in this keyspace will be replicated to the three nodes, in one datacenter and across different racks. If we lose a datacenter or a rack where the data is present, we lose the data. So, in the production deployment, using SimpleStrategy is risky.
Network topology strategy
This strategy allows us to have different replication factors for different datacenters. This strategy is datacenter-aware and ensures that replicas aren’t placed on the same rack. Each rack should have the same number of nodes in the datacenter in order to reduce differences in disk usage. So, any failure of a particular rack or the datacenter won’t affect the availability. Hence, for production deployments, NetworkTopologyStrategy is preferred.
Creating keyspace using NetworkTopologyStrategy
CREATE KEYSPACE <keyspace_name> WITH replication = {‘class’: ‘NetworkTopologyStrategy’, ‘<dc1_name>’: <no_of_replicas>, ‘<dc2_name>’: <no_of_replicas>….};
Ex: CREATE KEYSPACE pythian WITH replication = {‘class’: ‘NetworkTopologyStrategy’, ‘<dc1_name>’: 2, ‘<dc2_name>’: 2};
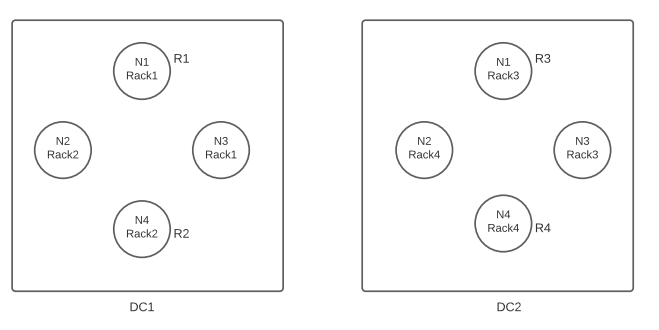
The above example shows how the data is distributed across the cluster using NetworkTopologyStrategy. Here, we created a keyspace called pythian which uses NetworkTopologyStrategy and has two datacenters, where the first has the replication of two and the second has two. The nodes are in different racks. Here, we can afford to lose a datacenter and also two racks. Therefore, our data will be available if we use this strategy, which is why it’s used in the production deployment.
I hope you find this post helpful. Feel free to drop any questions in the comments and don’t forget to sign up for the next post.
Cassandra Database Consulting
Ready to handle massive data volumes with zero downtime?