What is Apache Airflow?
- Airflow is a platform to programmatically author (designing pipelines, creating workflows), schedule, and monitor workflows. These functions are achieved with Directed Acyclic Graphs (DAG) of the tasks. It is open-source and still in the incubator stage. It was initialized in 2014 under the umbrella of Airbnb since then it got an excellent reputation with approximately 800 contributors on GitHub and 13000 stars. The main functions of Apache Airflow is to schedule workflow, monitor, and author.
The workflow (data-pipeline) management system known as Apache Airflow was developed by Airbnb. It is used by more than 200 companies, including Airbnb, Yahoo, PayPal, Intel, Stripe, and a host of others. - Everything in this is based on workflow objects that are implemented as directed acyclic networks (DAG). Such a workflow might for an instance combine data from many sources before running an analysis script. It orchestrates the systems involved and takes care of scheduling the tasks while respecting their internal dependencies.
What problems does Airflow solve?
- With cron, creating and maintaining a relationship between tasks is a nightmare, whereas using Airflow, it is as simple as writing a Python code.
- Cron needs external support to log, track, and manage tasks, Airflow has Airflow UI to track and monitor the workflow execution.
- Cron jobs are not reproducible unless externally configured where as Airflow keeps an audit trail of all tasks executed.
- Scalability is also one of the issue which can be resolved using Airflow.
Main components of Airflow:
- Scheduler: The scheduler monitors all DAGs and their associated tasks. It periodically checks active tasks to initiate.
- Web server: The web server is Airflow’s user interface. It shows the status of jobs and allows the user to interact with the databases and read log files from remote file stores, like Google Cloud Storage, Microsoft Azure blobs, etc.
- Database: The state of the DAGs and their associated tasks are saved in the database to ensure the schedule remembers metadata information. Airflow uses SQLAlchemy and Object Relational Mapping (ORM) to connect to the metadata database. The scheduler examines all the DAGs and stores pertinent information, like schedule intervals, statistics from each run, and task instances.
- Executor: There are different types of executors to use for different use cases.Examples of executors:
- Sequential Executor: This executor can run a single task at any given time, it cannot run tasks in parallel. It’s helpful in testing or debugging situations.
- LocalExecutor: This executor enables parallelism and hyper-threading and it’s great for running Airflow on a local machine or a single node.
- CeleryExecutor: This executor is the favoured way to run a distributed Airflow cluster.
- Kubernetes Executor: This executor calls the Kubernetes API to make temporary pods for each of the task instances to run.
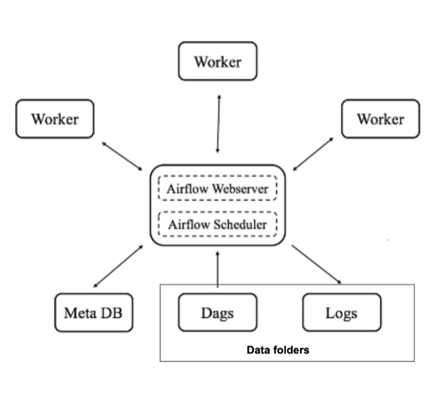
How does Airflow work?
Airflow examines all the DAGs in the background for a certain period. This period is set using the processor_poll_interval config and is equal to one second. Task instances are instantiated for tasks that need to be performed, and their status is set to SCHEDULED in the metadata database.
The schedule queries the database, retrieves tasks in the SCHEDULED state, and distributes them to the executors. Then, the state of the task changes to QUEUED. Those queued tasks are drawn from the queue by workers who execute them. When this happens, the task status changes to RUNNING.
When a task is completed, the worker will mark it as failed or finished, and then the scheduler updates the final status in the metadata database.
Features:
- Easy to Use: Having good knowledge in python helps to understand the deployment in Airflow.
- Open Source: It is free and open-source with a lot of active users.
- Robust Integrations: It will give you ready to use operators so that you can work with Google Cloud Platform, Amazon AWS, Microsoft Azure, etc.
- Use Standard Python to code: You can use python to create simple to complex workflows with complete flexibility.
- User Interface: You can monitor and manage your workflows. It will allow you to check the status of completed and ongoing tasks.
Principles:
- Dynamic: Airflow pipelines are configuration as code (Python), allowing for dynamic pipeline generation. This allows for writing code that instantiates pipelines dynamically.
- Extensible: Can easily define your own operators, executors and extend the library so that it fits the level of abstraction that suits your environment.
- Elegant: Airflow pipelines are lean and explicit.
- Scalable: It has a modular architecture and uses a message queue to orchestrate an arbitrary number of workers. Airflow is ready to scale to infinity.
Use Case:
DAG Monitoring
Software Requirements:
- Programming Language: Python 3.8 and above.
- Airflow version: 2.2.5
- IDE: VS Code
Requirement:
- To create a DAG that monitors the other DAGs and performs the needful actions.
- Check for the long-running DAG’s and if they are running for more than the threshold, then stop them.
- Identify the Failed DAG’s.
Code Snippet:
-
Check for long running tasks and kill
import airflow
from airflow import settings
from airflow.models import clear_task_instances, DAG, TaskInstance, Variable
from airflow.operators.dummy_operator import DummyOperator
from airflow.operators.python_operator import PythonOperator
from airflow.utils.state import State
from datetime import datetime, timezone
import logging
# Seconds in an hour
HOUR = 3600
def search_and_stop_long_tasks():
"""
This method search all running tasks and shutdown those that have been running for more than X hours (24 by default)
The TaskInstance class is used to search and shutdown since the documentation said:
"""
session = settings.Session()
max_running_hours = int(Variable.get("max_running_hours", default_var=24))
logging.info(f'max_running_hours: {max_running_hours}')
tis = []
for task in session.query(TaskInstance) \
.filter(TaskInstance.state == State.RUNNING) \
.all():
delta = datetime.now(timezone.utc) - task.start_date
if divmod(delta.total_seconds(), HOUR)[0] > max_running_hours:
logging.info(f'task_id: {task.task_id}, dag_id: {task.dag_id}, start_date: {task.start_date}, '
f'job_id: {task.job_id}, pid: {task.pid}, hostname: {task.hostname}, unixname: {task.unixname}')
tis.append(task)
if tis:
logging.info(f'Sending this tasks to shutdown: {[t.task_id for t in tis]}')
clear_task_instances(tis, session)
else:
logging.info('Nothing to clean')
#Task
long_running_dag = PythonOperator(
task_id='stop_long_running_tasks',
python_callable=search_and_stop_long_tasks,
dag=dag)
2. Identify the Failed DAG’s
import airflow
from airflow import settings
from airflow.models import clear_task_instances, DAG, TaskInstance, Variable
from airflow.operators.python_operator import PythonOperator
from airflow.utils.state import State
from datetime import datetime, timezone, timedelta, date
import logging
def get_failed_dag(state,**kwargs):
dag_ids = DagBag(include_examples=False).dag_ids
dag_runs = list()
for id in dag_ids:
state = state.lower() if state else None
for run in DagRun.find(id, state=state):
if run.end_date > (datetime.now(timezone.utc) - timedelta(minutes=last_interval)):
dag_runs.append({
'id': run.id,
'run_id': run.run_id,
'state': run.state,
'dag_id': run.dag_id,
'execution_date': run.execution_date.isoformat(),
'start_date': ((run.start_date or '') and
run.start_date.isoformat()),
'end_date': ((run.end_date or '') and
run.end_date.isoformat())
})
return dag_runs
#Task
failed_dag = PythonOperator(
task_id="failed_dag",
python_callable=get_failed_dag,
op_kwargs={'state': 'FAILED'},
dag=dag)
Tree Diagram of DAG Monitoring:

Log of task “get_failed_dag”:

Data Analytics Consulting Services
Ready to make smarter, data-driven decisions?