More and more companies are adopting the Always On Availability Groups as their HA/DR architecture for the SQL Server databases. While this comes with a lot of advantages—less downtime, use of the secondary replica to offload your read-only queries (depending on your licensing model)—it still comes with challenges: network and connectivity between nodes.
“Common” unexpected failure events
Most of the unexpected failover events which we had recently investigated could have been avoided by small changes to the cluster/AG role properties.
In the below example, the downtime was just two seconds, but it closed all application connections and led the running SQL agent jobs to fail (extract from the SQL errorlog file):
2021-05-25 04:47:52.93 Server The state of the local availability replica in availability group 'AG' has changed from 'PRIMARY_NORMAL' to 'RESOLVING_NORMAL'. The replica state changed because of either a startup, a failover, a communication issue, or a cluster error. 2021-05-25 04:47:54.91 spid52 The state of the local availability replica in availability group 'AG' has changed from 'RESOLVING_NORMAL' to 'PRIMARY_PENDING'. The replica state changed because of either a startup, a failover, a communication issue, or a cluster error. 2021-05-25 04:47:54.92 Server The state of the local availability replica in availability group 'AG' has changed from 'PRIMARY_PENDING' to 'PRIMARY_NORMAL'. The replica state changed because of either a startup, a failover, a communication issue, or a cluster error.
Here, we see the classic lease timeout event (extract from the errorlog file):
2021-06-21 04:11:15.42 Server Error: 19419, Severity: 16, State: 1. Windows Server Failover Cluster did not receive a process event signal from SQL Server hosting availability group 'AG' within the lease timeout period. 2021-06-21 04:11:15.53 Server Error: 19407, Severity: 16, State: 1. The lease between availability group 'AG' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
And in the failover cluster logs, you may see event sequences such as those below (you can extract the cluster logs using Get-ClusterLog powershell command):
DBG [NETFTEVM] FTI NetFT event handler got event: LocalEndpoint 10.0.1.10:~3343~ has missed two-fifth consecutive heartbeats from 10.0.1.11:~3343~ DBG [NETFTEVM] FTI NetFT event handler got event: LocalEndpoint 192.168.1.10:~3343~ has missed two-fifth consecutive heartbeats from 192.168.1.11:~3343~
or
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel WARN [RHS] Resource AG IsAlive has indicated failure. INFO [RCM] rcm::RcmGroup::UpdateStateIfChanged: (AG, Online --> Pending)
Always On health detection relies on a few mechanisms:
- Resource DLL (RHS), which determines the IsAlive value at the cluster heartbeat interval, and is controlled by CrossSubnetDelay and SameSubnetDelay cluster properties
- sp_server_diagnostics, which reports the component health on an interval controlled by the HealthCheckTimeout property
- Lease mechanism, which is used as a Looks-Alive between the cluster resource host and the SQL processes
- Session Timeout, which detected the “soft” errors / small timeouts or insufficient resources
- This also affects the automatic seeding timeout
The mechanisms above are controlled by properties that can be adjusted at the cluster level and/or the AG level:

Getting cluster properties values
To view the current cluster values, open an elevated Powershell terminal and run the following:
#display current cluster properties Get-Cluster | fl CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay , SameSubnetThreshold #display current AG role properties Get-ClusterResource <yourAG>| Get-ClusterParameter HealthCheckTimeout, LeaseTimeout


To view the current AG role properties, execute the below SQL statement in SSMS or any SQL IDE:
select ag.name, arcn.replica_server_name, arcn.node_name, ars.role, ars.role_desc, ars.connected_state_desc, ars.synchronization_health_desc, ar.availability_mode_desc, ag.failure_condition_level,ar.failover_mode_desc, ar.session_timeout from sys.availability_replicas ar with (nolock) inner join sys.dm_hadr_availability_replica_states ars with (nolock) on ars.replica_id=ar.replica_id and ars.group_id=ar.group_id inner join sys.availability_groups ag with (nolock) on ag.group_id=ar.group_id inner join sys.dm_hadr_availability_replica_cluster_nodes arcn with (nolock) on arcn.group_name=ag.name and arcn.replica_server_name=ar.replica_server_name

Making the cluster / AG more resilient
The default/maximum network downtime that AG can absorb without being impacted is 10 seconds (1/2 of LeaseTimeout and 1/3 of HealthCheckTimeout).
In order to make the cluster/AG roles more resilient and able to absorb more network downtime without a failover, you can increase the cluster and AG properties, taking into account the relationship between the properties’ values:
For example, to increase the supported network downtime from 10 to 20 seconds:
- LeaseTimeout – change from 20000 to 40000 (40 seconds)
- HealthCheckTimeout – change from 30000 to 60000 (60 seconds)
- SameSubnetThreshold – change from 10 to 20
- Session Timeout – change from 10 to 20 seconds
You may use the below Powershell script to change the cluster level properties:
$crossSubnetDelayOptimal = 1000;
$crossSubnetThresholdOptimal = 20
$sameSubnetDelayOptimal = 1000
$sameSubnetThresholdOptimal = 20
$healthCheckTimeoutOptimal = 60000
$leaseTimeoutOptimal = 40000
Write-Host "Check cluster heartbeat timeouts"
$cluster = get-cluster
$crossSubnetDelay = $cluster.CrossSubnetDelay
$crossSubnetThreshold = $cluster.CrossSubnetThreshold
$sameSubnetDelay = $cluster.SameSubnetDelay
$sameSubnetThreshold = $cluster.SameSubnetThreshold
if($crossSubnetDelay -ne $crossSubnetDelayOptimal)
{
Write-Host "Cluster option CrossSubnetDelay changed from $crossSubnetDelay to $crossSubnetDelayOptimal"
$cluster.CrossSubnetDelay = $crossSubnetDelayOptimal
}
if($crossSubnetThreshold -ne $crossSubnetThresholdOptimal)
{
Write-Host "Cluster option CrossSubnetThreshold changed from $crossSubnetThreshold to $crossSubnetThresholdOptimal"
$cluster.CrossSubnetThreshold = $crossSubnetThresholdOptimal
}
if($sameSubnetDelay -ne $sameSubnetDelayOptimal)
{
Write-Host "Cluster option SameSubnetDelay changed from $sameSubnetDelay to $sameSubnetDelayOptimal"
$cluster.SameSubnetDelay = $sameSubnetDelayOptimal
}
if($sameSubnetThreshold -ne $sameSubnetThresholdOptimal)
{
Write-Host "Cluster option SameSubnetThreshold changed from $sameSubnetThreshold to $sameSubnetThresholdOptimal"
$cluster.SameSubnetThreshold = $sameSubnetThresholdOptimal
}
Write-Host "Check cluster resource properties"
$resources = Get-ClusterResource
ForEach($resource in $resources)
{
if($resource.ResourceType -eq "SQL Server Availability Group")
{
$name = $resource.Name
$healthCheckTimeout = (Get-ClusterParameter -Name HealthCheckTimeout -InputObject $resource).Value
$leaseTimeout = (Get-ClusterParameter -Name LeaseTimeout -InputObject $resource).Value
if($healthCheckTimeout -ne $healthCheckTimeoutOptimal)
{
Write-Host "$name - HealthCheckTimeout - Changed from $healthCheckTimeout to $healthCheckTimeoutOptimal"
Set-ClusterParameter -Name HealthCheckTimeout -InputObject $resource -Value $healthCheckTimeoutOptimal
}
if($leaseTimeout -ne $leaseTimeoutOptimal)
{
Write-Host "$name - LeaseTimeout - Changed from $leaseTimeout to $leaseTimeoutOptimal"
Set-ClusterParameter -Name LeaseTimeout -InputObject $resource -Value $leaseTimeoutOptimal
}
}
}
To change the Session Timeout value, connect to the SQL instance and execute the below statement on all the AG replicas:
ALTER AVAILABILITY GROUP <AG name> MODIFY REPLICA ON '<replica name>' WITH (SESSION_TIMEOUT = 20);
Microsoft guidelines
Microsoft compiled guidelines for timeout values, their root causes and outcomes.
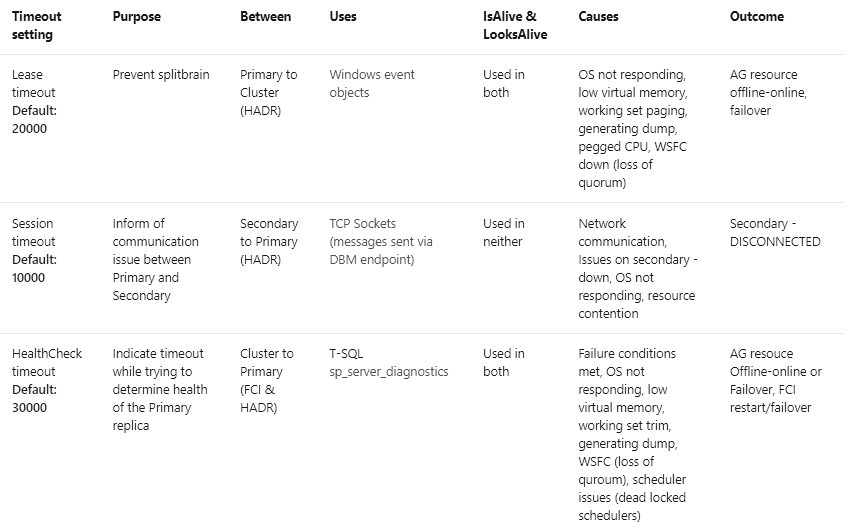
Special note on Resource Monitor (RHS)
Worth mentioning that by default, only one Resource Monitor (RHS/resource DLL) process is defined for all the AGs on the cluster node. Consider a scenario where multiple AGs are defined on the same cluster and one of the AGs/roles is experiencing errors (based on the HealthCheckTimeout, LeaseTimeout or FailoverConditionLevel) or the RHS process is failing. In this scenario, all the AGs on the cluster may experience transition state/failovers.
You can change this behavior by allowing each AG/cluster role to run on a separate Resource Monitor.

Final notes
Increasing the timeout values makes the AG role more resilient as it will not be affected by short network disruptions; however, a real cluster failure detection will take longer. The values can and should be adjusted to serve the Availability Group’s main purpose: being Always On with ideally no downtime.
Thank you for reading my post. Please leave comments for me below.
Resources:
SQL Server Database Consulting Services
Ready to future-proof your SQL Server investment?