Cassandra storage is generally described as a log-structured merge tree (LSM). In general, LSM storage provides great speed in performing writes, updates and deletes over reads. As a general rule, a write in Cassandra is an order of magnitude faster than a read. Not that reads are necessarily slow, but rather that the entire design of the server is to do writes very quickly and efficiently. To manage data written to LSM storage, the files created by the fast writes need to be re-organized to help read efficacy and manage storage space. The process to perform this reorganization is called "compaction." There are currently three generally available compaction strategies, each designed to optimize certain workloads. Unfortunately, there are many workloads which don’t necessarily fit well into any of the current compaction strategies. What I hope to do here is present a convincing argument for a fourth compaction strategy which I think will fit the needs of many use cases which today are left out in the cold. I am calling my proposed compaction strategy: Cluster Key Compaction Strategy (CKCS)
Find out how Pythian can help you with Cassandra services.
Existing strategies
Size tiered
Size Tiered Compaction Strategy (STCS) is the default compaction strategy and it has worked for many workloads through the years Cassandra has been in existence. It is recognized as having a relatively low write amplification level and it can generally keep the total number of SSTable files reasonably low, limiting the number of SSTable files that need to be referenced to find all the parts of a partition required by a read. One of its largest drawbacks is the amount of disk space required for a compaction.
Leveled compaction
Leveled Compaction Strategy (LCS) attempts to address the large amount of disk space required for compaction, and at the same time it also works to drastically limit the number of SSTable files required to fulfill a read from a partition to just one or two SSTable files. Its main drawback is the dramatic increase in write amplification for all data stored in LCS. With LCS, SSTable files are allowed to grow only to a predefined fixed size with the requirement that all columns of a specific partition exist in only one SSTable file at each level. When compacting from one level to the next, many SSTable files are both merged and distributed to many SSTable files.
Time window
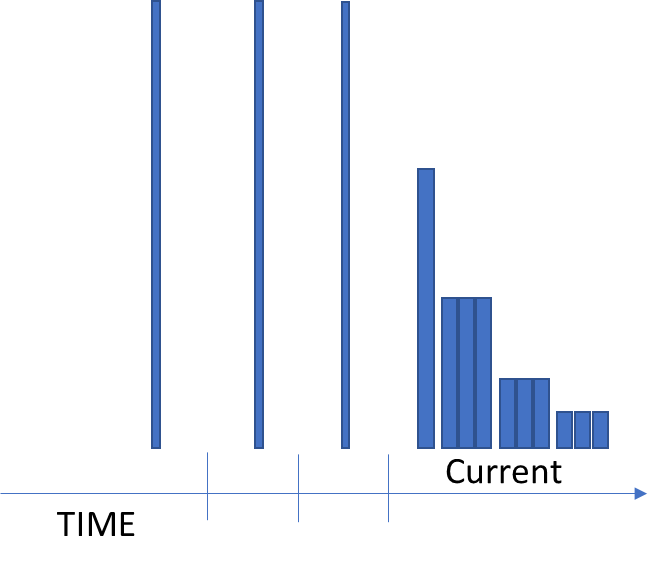
Time Window Compaction Strategy (TWCS) uses STCS inside of a set of predefined windows or buckets based on time to store data. It deliberately keeps partitions spread across many SSTable files. By the use of windows, the space required to perform a compaction can be reduced by up to the number of windows. For example, if the number of windows is 20, then the space required for any TWCS compaction will be no more than 1/20 of the space consumed by the table. It also results in the lowest write amplification of any of the compaction strategies. While this is not enforced, it is strongly recommended that TWCS be used only with data that is known to have a limited lifetime, preferably through the Time To Live (TTL) feature of Cassandra. TWCS was designed to store time series data where the data coming in is dividable into well-defined time chunks. TWCS does not play well with hinted handoffs, read repairs or regular repairs, all of which can end up putting data which might belong in one window into a different window. This is not usually a problem if the data is short-lived or not of a critical nature. But that is not always the case in the real world.
Limits to existing strategies
As discussed above, each strategy has its strengths and weaknesses. Each needs to be carefully evaluated to decide which is best for your application. STCS requires a large amount of space to perform compactions and may need many SSTable files read to find all parts of a specific row for a given partition, but it has fairly low write amplification. LCS dramatically reduces the amount of space required for a compaction and greatly improves the likelihood that all the rows of a partition will be in the same place, but it can produce a huge number of SSTable files and it results in a massive increase in write amplification. It's best used with workloads where reads are 90% or better of the workload. TWCS is designed to work with time series data only. It is based on server time, having nothing at all to do with anything stored in the data itself. Like LCS, it greatly reduces the space required for compaction and it also has even better write amplification than STCS. It does not work well with Cassandra’s current anti-entropy mechanisms which makes it unsuitable for some kinds of data which might otherwise fitWhy a new strategy
In the last four years I have spent time consulting for different organizations which are using or planning to use Cassandra, and I keep finding workloads which would benefit from a compaction strategy that has features of both LCS and TWCS, and yet is still distinct from either one. In fact, there are really two distinct use cases one could argue belong to separate strategies, but I think a single strategy could be created to fit both. I would like to propose Cluster Key Compaction Strategy (CKCS). In the CKCS, SSTable files will be grouped together based on its cluster key values. Either on a set of moving windows, much like TWCS uses where a specific number of windows contain data expected to expire over time to limit the total number of windows, or based on a predefined set of set of partitions for the entire key range. By basing the window selection on cluster key values, the windows become defined outside of current server time, allowing Cassandra anti-entropy tools to work, although this will increase write amplification and SSTable file counts over traditional TWCS. It will also allow data sets which are not time-based to benefit from the compaction space and partition spread out that is in the nature of the current TWCS strategy.Proposed CKCS details
The proposed CKCS will use the first column of the cluster key to define buckets which will be used to designate groups of SSTable file sets used to store data. In order to make the definition simple, the data type of that first column will need to be fixed in width and the possible key values well understood. Small integer, integer, large integer and timestamps would be the simplest to use and not, in my opinion, an unnecessarily restricted list.How the CKCS would work
When a table is created with CKCS one of two bucket definition parameter types will be used.- Moving window variation. Two parameters are used: one defines the unit size much like TWCS and should be caused unit. A unit can be a timeframe (seconds, minutes, hours, days) or it can be a number scale (ones, tens, hundreds, thousands, millions). The second parameter is the window size in units. With the moving window variation, it is assumed that all data written to the table will eventually expire and the number of windows will therefore be limited based on the lifetime of data stored in the table.
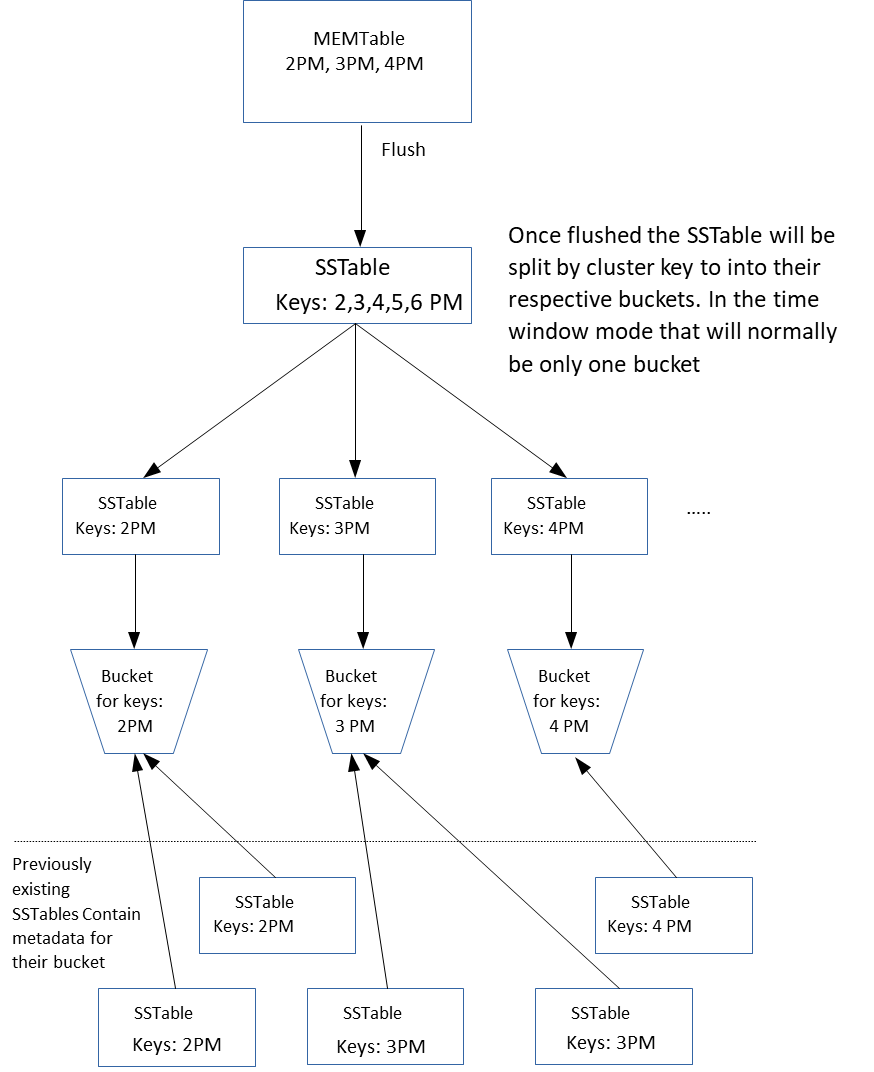
- Static window variation. One parameter is used: The static window variation assumes long-lived data which is to be spread into multiple windows, or buckets based on the value of the entire contents of the cluster key column. With this variation, the window size is not specified by the user. Instead, the number of windows or buckets is specified. Cassandra will compute the “size” by taking the maximum absolute value range of the column and dividing by the number of desired windows or buckets.
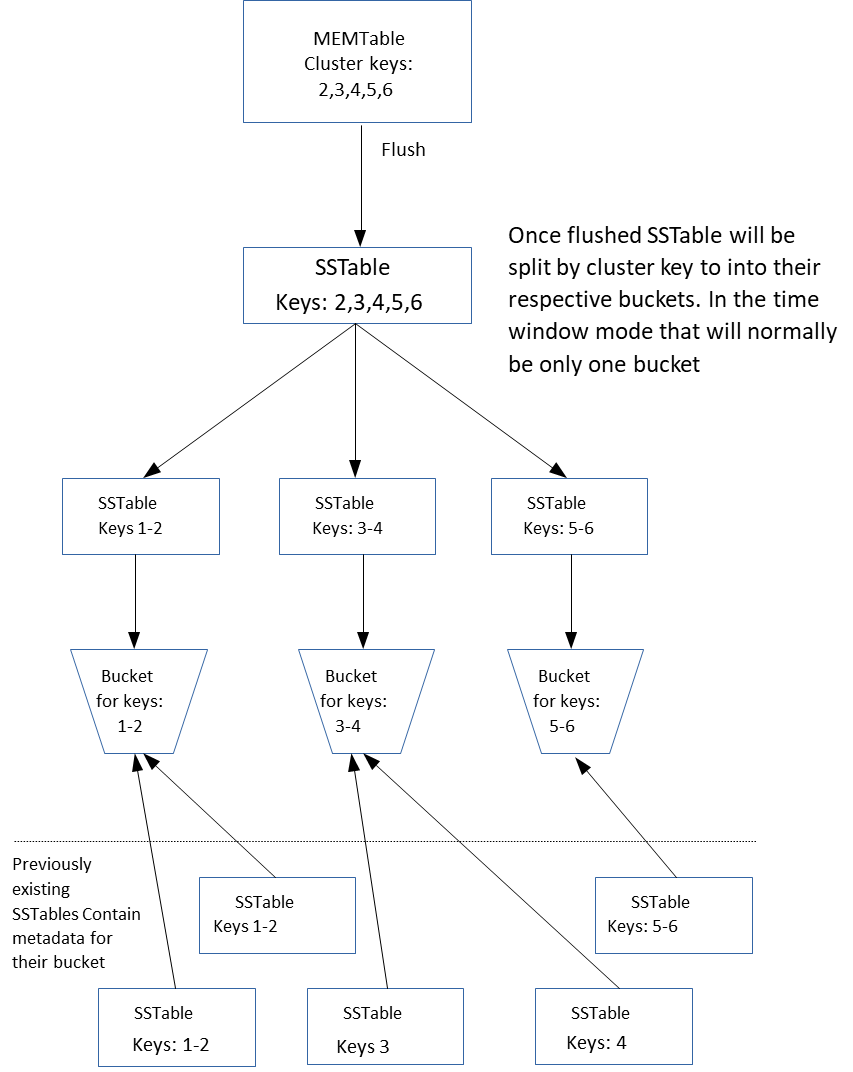
Benefits
This new compaction strategy will have benefits over TWCS and might likely succeed it as the primary time series compaction strategy, as it avoids many of the current issues with TWCS or its predecessor DTCS. In addition, this new strategy will bring some of the benefits of TWCS to database workloads which are not time series in nature.Large partitions
Large partitions under both STCS and LCS cause significant extra work during compaction. By spreading the partition data out over a number of windows or buckets, partitions can become significantly larger before having the heap and CPU impact on Cassandra during compaction that large partitions do today.Dealing with anti-entropy
Currently, Cassandra anti-entropy mechanisms tend to work counter-purpose to both TWCS and DTCS and often make it necessary to turn them off to avoid pushing data into the wrong windows. It is also impossible to reload existing data or add a new DC or even a new host without disrupting the windowing. CKCS will ensure data gets put into the correct windows even with anti-entropy running. It will also allow maintenance activities, including data reloads, adding a new DC or a new host to an existing DC storing data into the correct window. What CKCS won’t be able to do is ensure a final window compaction since there is never a certain final point in time for a given window. A “final” compaction is still likely to be a good idea; it just won't ensure that all data will be in a single SSTable file for the window.Compaction space savings
For both modes, moving window and static window, the compaction space savings will be comparable to what can be accomplished with TWCS or DTCS.Write amplification
Write amplification benefits should be similar to TWCS for the moving window mode as long as writes take place during the actual time windows and anti-entropy is not generating significant out of window writes. In Static window mode, write amplification should be similar to standard STCS but the number of compactions increases while the sizes will decrease making for the overall I/O workload somewhat less spiky.Find out how Pythian can help you with Cassandra services.
On this page
Share this
Share this
Making a business case for Machine Learning
![]()
Making a business case for Machine Learning
Aug 13, 2019 12:00:00 AM
2
min read
Advanced compression option caveat in Oracle 12c
![]()
Advanced compression option caveat in Oracle 12c
Nov 24, 2015 12:00:00 AM
2
min read
Customizing pt-stalk to capture the diagnostics data you really need

Customizing pt-stalk to capture the diagnostics data you really need
Feb 7, 2017 12:00:00 AM
4
min read