On this page
Share this
Share this
Watch Out When Running Out of Disk Space With InnoDB Group Replication Cluster
![]()
Watch Out When Running Out of Disk Space With InnoDB Group Replication Cluster
Feb 9, 2021 12:00:00 AM
4
min read
Asynchronous replication from MySQL cluster
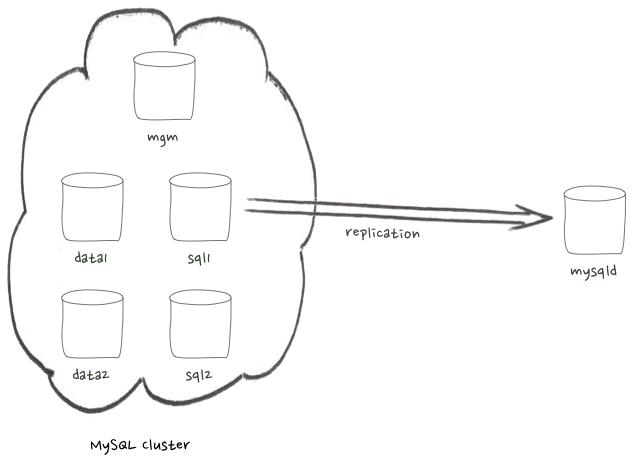
Asynchronous replication from MySQL cluster
Mar 20, 2017 12:00:00 AM
6
min read
Syncing inconsistent MySQL slaves
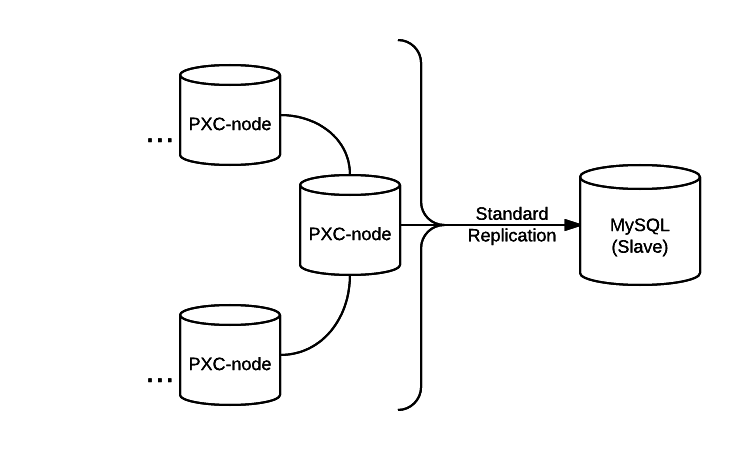
Syncing inconsistent MySQL slaves
Dec 2, 2015 12:00:00 AM
4
min read