Having attended Serverlessconf NYC a few weeks ago, and given my undying excitement around all things serverless, lately, I’ve been quite entrenched in the numerous possibilities of serverless architectures. Also, I’ve been itching to build something, as I haven’t had the chance to do so in quite a while, so I figured why not create a small mini-project that is fully based on serverless services.
The other day I was having a chat with a friend, and she was complaining about how part of her job was listening to endless hours of recordings and having to transcribe them. While there are so many solutions out there that do just that, and some do it really well, the light bulb went off in my mind. How about a fully serverless pipeline that can transcribe audio recordings on-demand.
As this idea peaked my interest, and since Google has been releasing some great ML-based API’s around natural language processing, I quickly looked up Google’s Cloud Speech API and its documentation.
I figured that this shouldn’t be too difficult (and kinda cool — as is everything serverless) to put something together. In doing so I quickly whipped up the code that’s required to call Cloud Speech API and have it transcribe speech from an audio file. I tested it and it worked pretty well!
Taking things one step further I wanted this to be a little more hands-off (and something worth actually writing about), a little more automated and a little more “intelligent”. So the code got a little smarter and more modular (as does all my code eventually) in order to run in a less controlled environment. Thinking of all things serverless, and thinking of scale, I would need to parallelize this pipeline but get rid of the bottleneck, i.e. Me!
In came serverless compute to the rescue. And as I was working primarily on GCP, I decided to adapt my function into a Cloud Function that would be triggered as soon as an object is uploaded into a pre-specified Cloud Storage bucket so the upload of an audio file would be the trigger event, and the API call would happen auto-magically. The only thing left was to instruct the Cloud Function on where to store the transcribed text that it received from the Cloud Speech API, and so I had to create a(nother) landing bucket.
With all that talk, let’s get to the good stuff, where we can see things actually working.
N.B. Deploying Cloud Storage-triggered Cloud Functions applies the trigger to the entire bucket, and so I couldn’t use “subfolders” for this since buckets are flat namespaces and so subfolders are an extension to an object’s key name and not actual sub-containers of objects.A Serverless Processing Pipeline
The pipeline is built primarily on three serverless components of the Google Cloud Platform:
- Google Cloud Storage
- Google Cloud Functions
- Google Cloud Speech API
While all you have to do is upload an audio file to a Cloud Storage bucket, the workflow under the hood is mildly more complex:
The workflow is as follows:
- Upload an audio file you want to be transcribed to the monitored Cloud Storage bucket
- The upload of an object triggers an object change notification, which triggers a Cloud Function
- The Cloud Function reads the uploaded file, constructs, and issues an API call to the Cloud Speech API, referencing the audio file in the Cloud Storage bucket
- Once finished processing, the Cloud Speech API returns a text file to the Cloud Function
- The Cloud Function then writes the text file to another bucket (that isn’t being monitored by the Cloud Function trigger… otherwise you’d enter an endless loop!)
Pipeline Architecture
[caption id="attachment_102789" align="aligncenter" width="677"]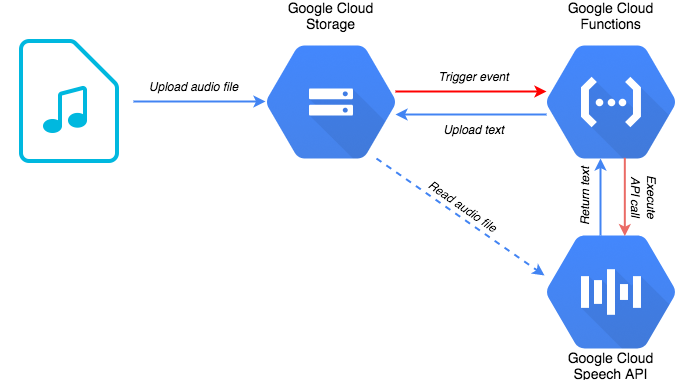 Fig. 1: Serverless audio transcription pipeline[/caption] You can find the corresponding code on Github,
here.
Fig. 1: Serverless audio transcription pipeline[/caption] You can find the corresponding code on Github,
here.
Finally, I gave some thought to possible optimizations to enhance this pipeline and the user experience (and practicality of the entire solution). In the spirit of keeping things serverless and to maintain the elegance of this architecture, here are some possibilities:
- Develop a static (HTML/CSS/JS) web UI, which would be stored and served from a GCS bucket; just as you would do with a static website. This will serve the purpose of a UI and a user-friendly manner of uploading audio files to GCS. Since this is being served from GCS, then there is no server backend needed.
- Add some logic to a (new) Cloud Function that can execute some preprocessing, such as input validation, to ensure that the file being uploaded is indeed an audio file.
- Once validated, some more pre-processing can take place to prepare the audio file into an “optimal” format. This may include leveraging something like FFMPEG to carry out some transcoding (or maybe Google can develop a Cloud Media API that does that out of the box)
- Add some post-processing logic to deliver the transcribed text back to the user, possibly as a download.
What interesting projects have you implemented recently that relied fully on serverless services?
Feel free to share in the comments section below.
Share this
Share this
Secure the Connection to Your VPC Network from Serverless Environments in Google Cloud

How to migrate from Teradata to Google BigQuery