On this page
Share this
Share this
Recursion in Hive - part 1
![]()
Recursion in Hive - part 1
Dec 16, 2015 12:00:00 AM
4
min read
Apache Beam: the Future of Data Processing?
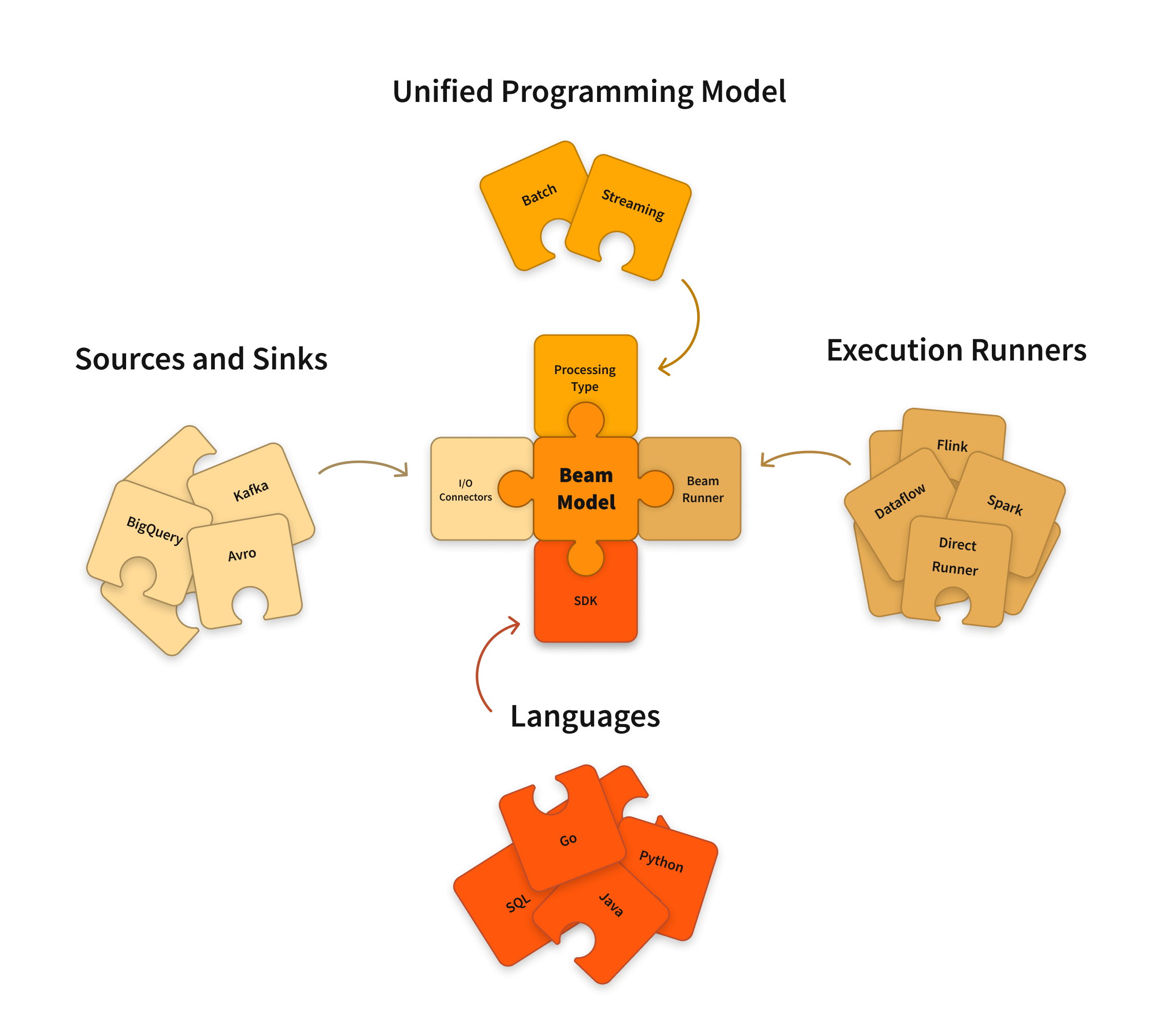
Apache Beam: the Future of Data Processing?
Aug 25, 2022 12:00:00 AM
9
min read
Near Real-Time Data Processing for BigQuery: Part Two
![]()
Near Real-Time Data Processing for BigQuery: Part Two
May 4, 2021 12:00:00 AM
7
min read