Machine learning (ML) workloads have some unique properties, characteristics and complexity that separate them from less advanced analytics. Developing an ML model requires data scientists to understand what kind of data their model will need, and to run a number of experiments to choose the most suitable algorithm. They then need to train a model by using a training data set to adjust model parameters in multiple iterations until model accuracy is within acceptable limits. Once they've trained a model, they need to validate it to ensure the model produces good results on data other than the training data set. Finally, the model can start serving results to its end users by accepting new data, applying calculations and producing results.
In many organizations, this is a complicated process with many manual steps. To make the machine learning process efficient requires four key ingredients: lots of data, a scalable computation environment, the ability to use a variety of tools, integrated experimentation and collaboration. A well-designed cloud data platform makes all of these possible and cost effective.
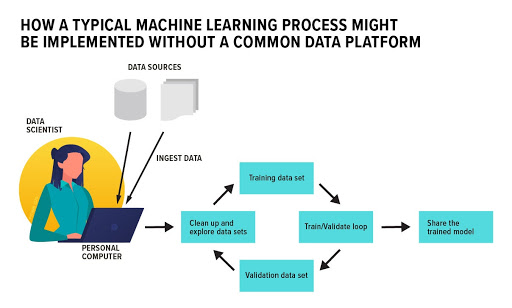 The first thing a data scientist does is try to ingest (copy) the data from the existing data sources into their own computer where they can run the rest of the ML process. Next, they almost always perform some data cleanup steps; converting data from multiple formats into a single format their tools of choice will understand. Then a data scientist will run some exploratory analysis on the data sets to understand what kind of data they contain; checking if there are any outliers in the data or any other properties that may impact the model training process. According to multiple studies, these first two steps in the ML lifecycle — ingesting and cleaning up data take up to 80 percent of all the time data scientists spend on the entire model development process. Next, data scientists perform the train / validate loop. To train a model they must split the data into two parts: a training data set and a validation data set. They then run the model training process on the training data set. The training process itself is iterative, meaning an ML model will need to read and process the training data set multiple times; gradually adjusting its parameters to produce results with a required accuracy. This process is computationally expensive, especially when dealing with large data sets. Running it on a single computer can take a long time.
Note: This is a deliberately simplified ML lifecycle for the sake of brevity. In reality there are many more details involved in the process, like labeling data sets for supervised learning, etc. Once the training process has finished, the data scientist must apply the model to the validation data sets to make sure the model produces accurate results on data other than training data. This helps data scientists avoid a problem called overfitting, where a model’s parameters fit the training data set very well, but produce inaccurate results on any other data. The way data is split into training and validation data sets plays a big role here, since the validation data set should be as representative as possible of data the model will need to deal with in production. Once the training process is complete, the data scientist will want to share the model with their peers or hand it over to the Operations team to actually deploy it into production. One of the challenges with this step is that often code developed on a personal computer doesn’t integrate very well (if at all) with the production environment. For example it may not have all the logging, error handling or monitoring features that an application in production requires to run. The fact that data scientists in this process are isolated from the actual production or testing environments may require the Operations or DevOps teams to make significant changes to the model before it can be deployed. Many time-consuming tasks, like data ingestion and cleanup can be significantly simplified when using a cloud data platform as a central place to develop ML models. The following diagram shows how a ML lifecycle might look on a cloud data platform:
The first thing a data scientist does is try to ingest (copy) the data from the existing data sources into their own computer where they can run the rest of the ML process. Next, they almost always perform some data cleanup steps; converting data from multiple formats into a single format their tools of choice will understand. Then a data scientist will run some exploratory analysis on the data sets to understand what kind of data they contain; checking if there are any outliers in the data or any other properties that may impact the model training process. According to multiple studies, these first two steps in the ML lifecycle — ingesting and cleaning up data take up to 80 percent of all the time data scientists spend on the entire model development process. Next, data scientists perform the train / validate loop. To train a model they must split the data into two parts: a training data set and a validation data set. They then run the model training process on the training data set. The training process itself is iterative, meaning an ML model will need to read and process the training data set multiple times; gradually adjusting its parameters to produce results with a required accuracy. This process is computationally expensive, especially when dealing with large data sets. Running it on a single computer can take a long time.
Note: This is a deliberately simplified ML lifecycle for the sake of brevity. In reality there are many more details involved in the process, like labeling data sets for supervised learning, etc. Once the training process has finished, the data scientist must apply the model to the validation data sets to make sure the model produces accurate results on data other than training data. This helps data scientists avoid a problem called overfitting, where a model’s parameters fit the training data set very well, but produce inaccurate results on any other data. The way data is split into training and validation data sets plays a big role here, since the validation data set should be as representative as possible of data the model will need to deal with in production. Once the training process is complete, the data scientist will want to share the model with their peers or hand it over to the Operations team to actually deploy it into production. One of the challenges with this step is that often code developed on a personal computer doesn’t integrate very well (if at all) with the production environment. For example it may not have all the logging, error handling or monitoring features that an application in production requires to run. The fact that data scientists in this process are isolated from the actual production or testing environments may require the Operations or DevOps teams to make significant changes to the model before it can be deployed. Many time-consuming tasks, like data ingestion and cleanup can be significantly simplified when using a cloud data platform as a central place to develop ML models. The following diagram shows how a ML lifecycle might look on a cloud data platform:
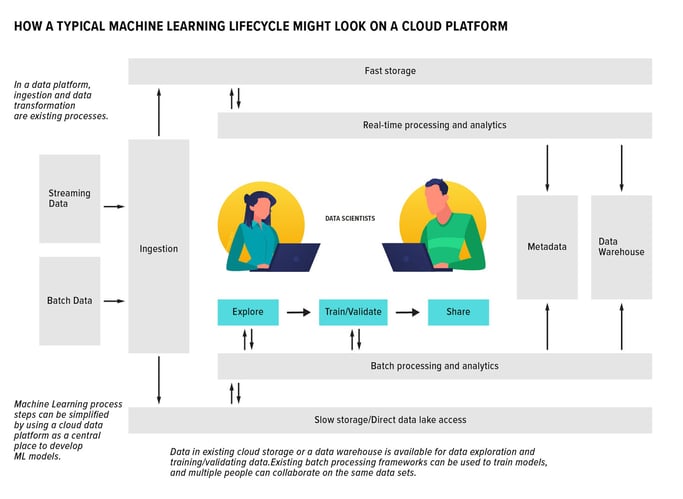 With a cloud data platform, a lot of the work not directly related to building and training ML models, like figuring out how to ingest data from a particular data source or converting to a common data format, is taken care of with the ingestion and common data transformation of all source data. Data scientists can use existing cloud storage or a data warehouse to browse and run exploratory analytics without having to bring data to their own computers. When it comes to the train / validate loop, data scientists can use existing archived data as large-scale training data sets, then use more recent incoming data as a validation data set. They can also choose to split data in some other way by creating a dedicated area on the cloud storage and copying required data sets there. Cloud storage is scalable and inexpensive, allowing data science teams to experiment and easily slice and dice data in any way they want. For the computationally expensive model training part of the process, scientists have a choice. They can either use existing batch processing frameworks like Apache Spark (which supports a number of ML models out of the box) to train their models in a scalable way, or use dedicated cloud virtual machines with large amounts of memory and GPUs. This processing is infinitely scalable and can scale up and down as needed, which is not only cost effective but also minimizes any performance impact on other users. In our data platform scenario, since every team member in the data science team is working on the same platform, it is now possible to not only share the final results of the work, but for multiple people to collaborate on the same data sets, and the same splits of test and validation data sets. This significantly shortens the feedback cycle and improves productivity. Being “close” to real data also makes it possible to test final models on real data volumes before publishing them into production. This testing reduces the number of issues locally developed models cause when they turn out to be “not-quite-ready” for production deployment.
With a cloud data platform, a lot of the work not directly related to building and training ML models, like figuring out how to ingest data from a particular data source or converting to a common data format, is taken care of with the ingestion and common data transformation of all source data. Data scientists can use existing cloud storage or a data warehouse to browse and run exploratory analytics without having to bring data to their own computers. When it comes to the train / validate loop, data scientists can use existing archived data as large-scale training data sets, then use more recent incoming data as a validation data set. They can also choose to split data in some other way by creating a dedicated area on the cloud storage and copying required data sets there. Cloud storage is scalable and inexpensive, allowing data science teams to experiment and easily slice and dice data in any way they want. For the computationally expensive model training part of the process, scientists have a choice. They can either use existing batch processing frameworks like Apache Spark (which supports a number of ML models out of the box) to train their models in a scalable way, or use dedicated cloud virtual machines with large amounts of memory and GPUs. This processing is infinitely scalable and can scale up and down as needed, which is not only cost effective but also minimizes any performance impact on other users. In our data platform scenario, since every team member in the data science team is working on the same platform, it is now possible to not only share the final results of the work, but for multiple people to collaborate on the same data sets, and the same splits of test and validation data sets. This significantly shortens the feedback cycle and improves productivity. Being “close” to real data also makes it possible to test final models on real data volumes before publishing them into production. This testing reduces the number of issues locally developed models cause when they turn out to be “not-quite-ready” for production deployment.
1. A cloud data platform can cost-effectively hold ALL THE DATA
While many cloud data platforms start out as a way to encourage more business access to data via reports and dashboards, if properly designed, they can store all the data available to your organization. This includes archives of historical data and access to both raw data that is ingested from the source systems as-is, and preprocessed data that has been cleaned up according to organizational standards. Access to raw and precleaned data is of huge value to data scientists who want to feed their models. And it's not just access to data; cloud vendors also have a variety of tools to make it easy to split data into training and validation data sets.2. A cloud data platform can make unlimited compute available when needed
Machine learning models need access to significant compute capacity to run the training process. This includes rerunning training steps hundreds or thousands of times. The data processing layer of the cloud data platform offers a scalable compute platform which data scientists can use to train models on much larger datasets than would be possible on a personal computer. Today all cloud vendors offer access to VMs with powerful Graphics Processing Units (GPUs) which can significantly speed up the ML model training process.3. A cloud data platform provides multiple and different ways to access data
A cloud data platform also provides multiple different ways to access the data: SQL, Apache Spark, direct files access, etc. This is important because it allows you to use the ML tools and libraries that may have different requirements for working with data. More choice means higher productivity to data scientists.4. A cloud data platform brings integrated experimentation and collaboration tools
Communication and collaboration between team members during the model development process is very important. If each data science team member experiments with data on their own computers it can be challenging to reconcile or share these results with other team members. Cloud vendors have realized the importance of a seamless collaboration for the model development process and offer a number of tools that allow data scientists to run, share and discuss the results of their experiments with other team members or stakeholders.Implementing machine learning on your cloud data platform
These requirements make a cloud data platform an ideal place for the machine learning workloads. Here’s how this might look in practice: A typical, if overly simplified, machine learning lifecycle has the following steps:- Ingest and prepare data sets
- Train / validate model loop
- Deploy the model to production to serve results to the end users
The first thing a data scientist does is try to ingest (copy) the data from the existing data sources into their own computer where they can run the rest of the ML process. Next, they almost always perform some data cleanup steps; converting data from multiple formats into a single format their tools of choice will understand. Then a data scientist will run some exploratory analysis on the data sets to understand what kind of data they contain; checking if there are any outliers in the data or any other properties that may impact the model training process. According to multiple studies, these first two steps in the ML lifecycle — ingesting and cleaning up data take up to 80 percent of all the time data scientists spend on the entire model development process. Next, data scientists perform the train / validate loop. To train a model they must split the data into two parts: a training data set and a validation data set. They then run the model training process on the training data set. The training process itself is iterative, meaning an ML model will need to read and process the training data set multiple times; gradually adjusting its parameters to produce results with a required accuracy. This process is computationally expensive, especially when dealing with large data sets. Running it on a single computer can take a long time.
Note: This is a deliberately simplified ML lifecycle for the sake of brevity. In reality there are many more details involved in the process, like labeling data sets for supervised learning, etc. Once the training process has finished, the data scientist must apply the model to the validation data sets to make sure the model produces accurate results on data other than training data. This helps data scientists avoid a problem called overfitting, where a model’s parameters fit the training data set very well, but produce inaccurate results on any other data. The way data is split into training and validation data sets plays a big role here, since the validation data set should be as representative as possible of data the model will need to deal with in production. Once the training process is complete, the data scientist will want to share the model with their peers or hand it over to the Operations team to actually deploy it into production. One of the challenges with this step is that often code developed on a personal computer doesn’t integrate very well (if at all) with the production environment. For example it may not have all the logging, error handling or monitoring features that an application in production requires to run. The fact that data scientists in this process are isolated from the actual production or testing environments may require the Operations or DevOps teams to make significant changes to the model before it can be deployed. Many time-consuming tasks, like data ingestion and cleanup can be significantly simplified when using a cloud data platform as a central place to develop ML models. The following diagram shows how a ML lifecycle might look on a cloud data platform:
With a cloud data platform, a lot of the work not directly related to building and training ML models, like figuring out how to ingest data from a particular data source or converting to a common data format, is taken care of with the ingestion and common data transformation of all source data. Data scientists can use existing cloud storage or a data warehouse to browse and run exploratory analytics without having to bring data to their own computers. When it comes to the train / validate loop, data scientists can use existing archived data as large-scale training data sets, then use more recent incoming data as a validation data set. They can also choose to split data in some other way by creating a dedicated area on the cloud storage and copying required data sets there. Cloud storage is scalable and inexpensive, allowing data science teams to experiment and easily slice and dice data in any way they want. For the computationally expensive model training part of the process, scientists have a choice. They can either use existing batch processing frameworks like Apache Spark (which supports a number of ML models out of the box) to train their models in a scalable way, or use dedicated cloud virtual machines with large amounts of memory and GPUs. This processing is infinitely scalable and can scale up and down as needed, which is not only cost effective but also minimizes any performance impact on other users. In our data platform scenario, since every team member in the data science team is working on the same platform, it is now possible to not only share the final results of the work, but for multiple people to collaborate on the same data sets, and the same splits of test and validation data sets. This significantly shortens the feedback cycle and improves productivity. Being “close” to real data also makes it possible to test final models on real data volumes before publishing them into production. This testing reduces the number of issues locally developed models cause when they turn out to be “not-quite-ready” for production deployment.
The Bottom Line
A well-architected modern data platform will make your ML journey easier and will enhance the productivity of all your teams. While it can be developed in parallel with an ML plan, it is a critical foundational element and should not be left too late in the process. It also has benefits that extend beyond ML as it can incorporate additional serving options such as data warehouses to extend the value of data beyond the ML team into the hands of business users. The more people using corporate data, the more the company will enjoy a return on their data investments. To learn more about ML and / or cloud data platforms please reach out to info@pythian.com.On this page
Share this
Share this
Oracle RMAN Restore to the Same Machine as the Original Database
![]()
Oracle RMAN Restore to the Same Machine as the Original Database
Apr 11, 2014 12:00:00 AM
6
min read
Oracle: Standby Automatic File Management
![]()
Oracle: Standby Automatic File Management
May 30, 2007 12:00:00 AM
2
min read
A Most Simple Cloud: Is Amazon RDS for Oracle Right for You?
![]()
A Most Simple Cloud: Is Amazon RDS for Oracle Right for You?
Jun 11, 2013 12:00:00 AM
5
min read