 In recent months, it seems that everyone in the IT industry has been talking about Generative AI and Large Language Models (LLMs) like OpenAI’s GPT or Google’s Bard. Technology news, Big Tech, and ISVs are all getting on this bandwagon promoting this new and exciting technology. Naturally, across various industries executives are starting to get interested as well, wondering how they can apply the technology to their challenges and use cases.
In recent months, it seems that everyone in the IT industry has been talking about Generative AI and Large Language Models (LLMs) like OpenAI’s GPT or Google’s Bard. Technology news, Big Tech, and ISVs are all getting on this bandwagon promoting this new and exciting technology. Naturally, across various industries executives are starting to get interested as well, wondering how they can apply the technology to their challenges and use cases.
While many have explored LLMs for prototypes and simple use cases, building a production-grade system that harnesses the full potential of these models presents its own set of challenges and opportunities. In this blog post, we will explore the architecture and best practices for developing robust, scalable, and ethical LLM systems, along with lessons learned from our previous experiences in building data systems in the public cloud.
Architectural Matters
1. Cloud or self-hosted
In our opinion, the first decision is whether you will use a cloud-hosted LLM service or self-host the LLM in your own infrastructure. Let’s look at these options in detail.
Cloud-Hosted LLM: Opting for a cloud-hosted LLM service, such as those provided by major cloud providers, offers convenience and scalability. You can leverage the cloud provider's infrastructure, ensuring that your LLM can handle high workloads without worrying about managing servers, GPU capacity, renewing hardware, etc.
These are the typical considerations of choosing cloud vs on-prem, however, we believe the cloud is even more attractive for hosting an LLM since the current state-of-the-art ones (like GPT 4) are not available to self-host, and even if it was, it requires a large amount of GPU power to run inference in a speed that would seem responsive to the average user.
Self-Hosting LLM: Self-hosting an LLM on your own infrastructure provides more control and security. You have full control over the environment, data, and access. However, it comes with the responsibility of managing infrastructure, security, and scalability. It also requires dedicated hardware like GPUs or TPUs that a lot of organizations are not familiar with procuring and operating. Finally, you would also be limited to deploying an “open-source” LLM like Meta’s LLama.
Unless there are very specific and compelling reasons to self-host, the cloud should be the first choice for most organizations. You would then start by deploying to a cloud region that is closest to where the bulk of your workload is coming from.
For the intent of this blog post, I will use Azure for the examples, however, the same architecture can be implemented across any of the major providers.
At this point, we know we will be doing cloud, and let’s assume that Azure East US is a good fit in terms of region proximity for us. We’re also doing an LLM so we have a few options:
- GPT 3.5 Turbo - 4K tokens
- GPT 3.5 Turbo - 16K tokens
- GPT 4 - 8K tokens
- GPT 4 - 32K tokens
Let’s assume we are building a corporate onboarding assistant and we don’t need a context larger than 4000 tokens, so we can deploy the GPT 3.5 Turbo 4K model.
Our initial architecture then simply starts with our subscription, a resource group, and the OpenAI service deployed in East US:
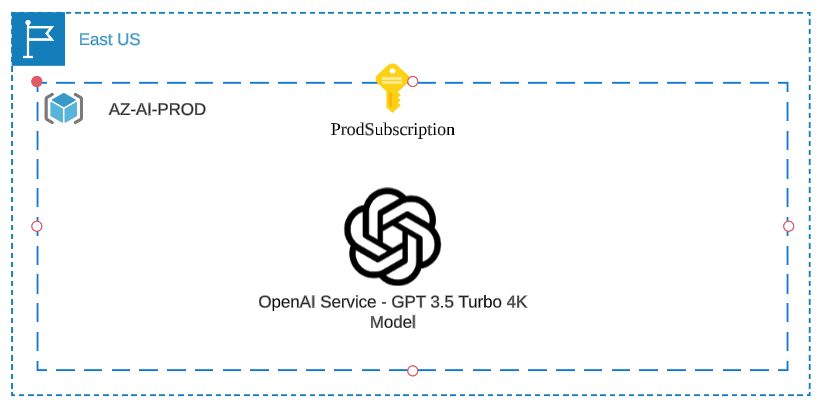
Let’s keep going!
2. Bringing your own Data
To realize the full untapped potential of LLMs it is not enough to simply deploy the foundational model created by one of the major AI players. The reason is that most of an enterprise's knowledge will be stored behind its own data and content systems and will not be part of the initial training dataset of the foundational model. Thus, we need to somehow inject this knowledge into the LLM to provide a deeper, contextual understanding of our organization for our users to interact with.
To implement this capability we have to consider incorporating a vector index or vector database. These databases enable you to add proprietary data and context to your LLM, making responses more relevant to your specific use case. There are some options already in the market with more emerging every day. We have some augmentations to classic database technology like PGVector on top of Postgresql, we have first-party cloud integrations like Google’s Vertex AI and Microsoft Azure’s OpenAI service, and we even have SaaS vector databases emerging like ActiveLoop or Pinecone.
Regardless of your final choice, we will need a process to index documents or data as vector embeddings and a process to retrieve and inject context into our LLM responses. Since we are building in Azure, I can generate the embeddings using another OpenAI model called “Ada” which is also available in Azure OpenAI service.
Let’s assume as well that you already have a data lake in the cloud with some of the data that you want to use for your LLM.
Let’s refresh our architecture:
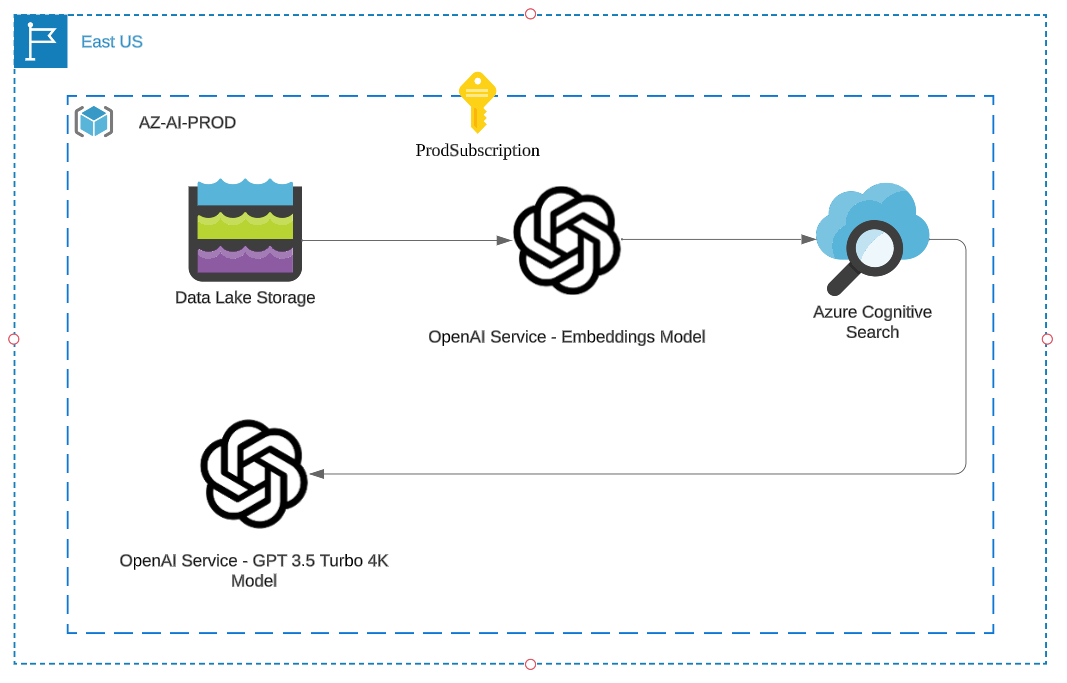
We also don’t want the LLM to simply work with static data, so, you will need to periodically refresh this data with some of it coming from on-premises. Now we need connectivity from on-prem as well as some process to bring that data in. We could use Azure Data Factory in this case as our data movement service and establish a VPN tunnel from on-prem.
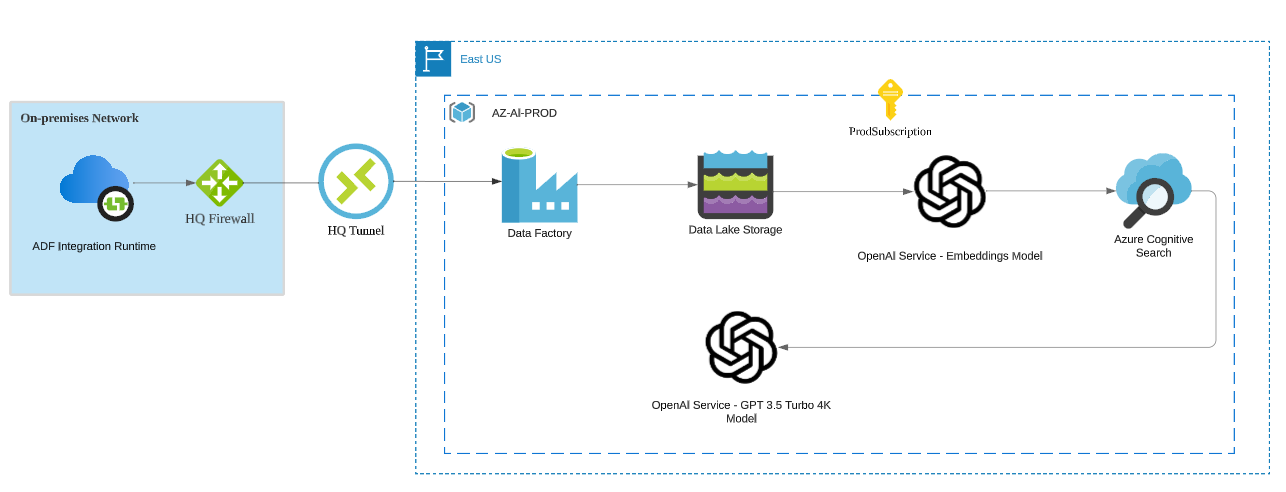
3. Controlled API Access
A solid foundation is essential. Instead of allowing a free-for-all into the LLM, it is best to control what the interaction can be between your external systems and the LLM by implementing a microservice with a standard API. The Azure service already offers an API of course, but this API allows you to do whatever the LLM can do and this will likely be too permissive for most enterprise use cases. Most likely there will be different use case-specific APIs developed that use the OpenAPI API behind the scenes.
This way you can use a serverless architecture to create smaller, independently scalable governed interactions. This allows you to handle concurrent requests efficiently and maintain system responsiveness. Scalability of the calls to the LLM itself is handled by the cloud service but we still need to account for the scalability of this new API layer we are putting in front.
In past projects, we found that a well-architected system has not only scaled effortlessly but also we were able to minimize operational overhead. In this case, we want to leverage components that will be charging us for active use so waste is minimized. So, we will be introducing Azure Functions in front of the LLM model for this functionality. We also want to manage and secure incoming requests through an API gateway. This gives us out-of-the-box capabilities for robust authentication and authorization mechanisms to control access as well.
Conclusion
Let’s update the architecture, I’m zooming on the cloud side since that’s where the change is happening:
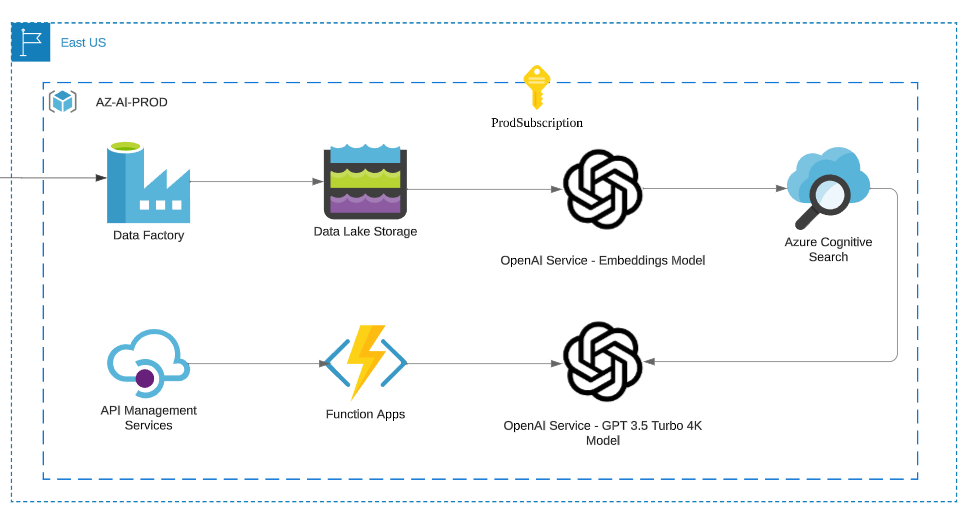
In Part 2, we'll cover Caching and Optimization, Continuous Integration and Delivery, Baseline Security, and more—stay tuned!
AI Consulting Services
Ready to start your AI journey?