This post shows how to use cloudspannerecosystem/scheduled-backups to configure scheduled backups for your cloud spanner database. The setup of the required resources (Cloud Scheduler, pub/sub and cloud function) will be done by using terraform in this tutorial.
The architecture is as follows:
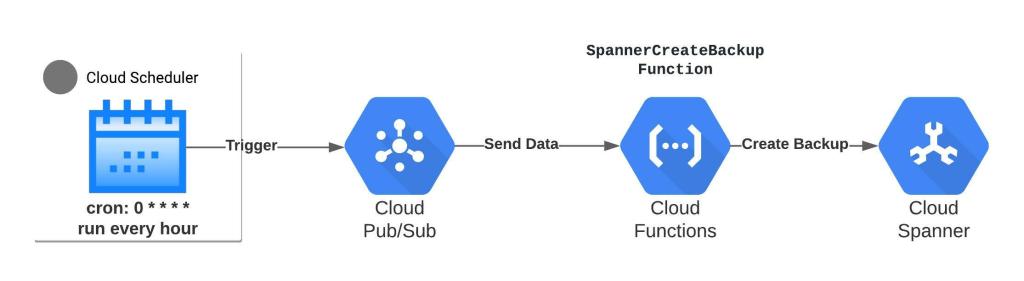
We’ll provision the following Google Cloud Platform (GCP) services using Terraform:
- Cloud Scheduler: trigger tasks with a cron-based schedule. You can modify this schedule in the terraform template
- Cloud Pub/Sub: a queue where Cloud Scheduler will publish a message to pub/sub to trigger the [SpannerCreateBackup] cloud function
- Cloud Function: function that will start an operation to create a Cloud Spanner database backup
- Service Account: service account that will grant Cloud function permissions to create a backup for spanner database
- Cloud Storage: Bucket where the backup function for cloud functions will be zipped and pushed. Later, the same zip file from this bucket will be referenced in cloud function.
Prerequisites
You’ll need following resources provisioned before proceeding:
- You must have Terraform installed and configured on your workstation/laptop. Alternatively, you can also use Cloud Shell to provision the resources using Terraform. I’ll use my local machine to call Terraform to create GCP resources
- You’ll need a Google Cloud Project.
- Make sure that API for Cloud Scheduler, Spanner, pub/sub and Cloud Functions are enabled.
- You’ll need Google Cloud SDK installed on your local machine.
- You will need a Spanner instance and database in the GCP project you intend to use. You can also check out the spanner terraform modules to create the spanner instance and database(s).
- Terraform will need a service account key file that will provision required resources. Use the following code block to create the service account and assign “Owner role” to the project and generate the key file. This key file will be used by terraform to provision required resources in your GCP Project
gcloud iam service-accounts create terraform --display-name terraform export sa_terraform=$(gcloud iam service-accounts list --filter="displayName:terraform" --format='value(email)') export PROJECT=$(gcloud info --format='value(config.project)') gcloud projects add-iam-policy-binding $PROJECT --role roles/owner --member serviceAccount:$sa_terraform gcloud iam service-accounts keys create ~/key.json --iam-account $sa_terraform
You can also use the GUI to create the service account and download the key file. Rename the <service-account>.json file to key.json file because that is what the provider will be expecting by default.
Backup Scheduler Module
The backup scheduler module consists of the following resources
- A Service Account name backup_sa that will have permissions to create a cloud spanner database backup. Cloud function will use this service account’s permissions to send instructions to the spanner to create database backup.
//Service Accounts
resource "google_service_account" "backup_sa" {
account_id = "backup-sa"
display_name = "Spanner Backup Function Service Account"
}
resource "google_project_iam_member" "backup_sa_spanner_iam" {
project = var.gcp_project_id
role = "roles/spanner.backupWriter"
member = "serviceAccount:${google_service_account.backup_sa.email}"
}
- A Pub/Sub topic with default name set in the variables.tf file to cloud-spanner-scheduled-backups. This is where Cloud Scheduler will publish the message to trigger the cloud function and create a spanner database backup:
// PubSub
resource "google_pubsub_topic" "backup_topic" {
project = var.gcp_project_id
name = var.pubsub_topic
}
- A Cloud Scheduler job named spanner-backup-job to publish a message to the pub/sub topic:
resource "google_cloud_scheduler_job" "backup_job" {
region = var.region
project = var.gcp_project_id
name = "spanner-backup-job"
description = "Backup job for main-instance"
schedule = var.schedule
time_zone = var.time_zone
pubsub_target {
topic_name = google_pubsub_topic.backup_topic.id
data = var.pubsub_data
}
depends_on = [google_pubsub_topic.backup_topic]
}
The message sent to pub/sub is as follows. This is passed from the main.tf when assigning a value to module variable – var.pubsub_data:
'{"database":"projects/[PROJECT_ID]/instances/[INSTANCE_ID]/databases/[DATABASE_ID]", "expire": "6h"}'
- A Cloud Function SpannerCreateBackup that will get the database id from pub/sub message and pass instructions to Cloud Spanner to create a database backup. The function source is located here and zipped and uploaded to a cloud storage bucket created as part of the Terraform module. You can expect to see a bucket with the name {“Your Project ID”}-gcp-ssb-source. The source files for the backup function have been taken from cloudspannerecosystem/scheduled-backup. The cloud function will use the pub/sub backup topic as trigger. The cloud function is configured to use the backup_sa service account:
resource "google_cloudfunctions_function" "spanner_backup_function" {
name = "SpannerCreateBackup"
project = var.gcp_project_id
region = var.region
available_memory_mb = "256"
entry_point = "SpannerCreateBackup"
runtime = "go113"
event_trigger {
event_type = "google.pubsub.topic.publish"
resource = google_pubsub_topic.backup_topic.id
}
source_archive_bucket = google_storage_bucket.bucket_gcf_source.name
source_archive_object = google_storage_bucket_object.gcs_functions_backup_source.name
service_account_email = google_service_account.backup_sa.email
depends_on = [google_pubsub_topic.backup_topic]
}
Implementation
The required module and template are available here.
a) Clone the repository to your local machine:
git clone https://github.com/sa-proj/proj-tf-gcp.git
b) Navigate to the the proj-tf-spanner-backups folder:
cd proj-tf-gcp/proj-tf-spanner-backups
c) Copy the key.json file generated for service account to this directory:
d) Update the terraform.tfvars file. You are expected to provide your GCP Project ID, spanner instance ID, database name that you wish to configure scheduled backups, the region where resources will be created and the backup cron job schedule:
//Enter your project ID gcp_project_id = "Your Project ID" //Enter Spanner Instance ID where you database is located that you want to backup spanner_instance_id = "spanner-1" //Enter Spanner Database name you want to backup spanner_database_id = "sample" //Enter the GCP region name region = "us-central1" //Enter the schedule on which you want to call the cloud scheudler job. The below is set to run every 1 hour schedule = "0 * * * *"
e) Initialize the working directory:
terraform init
f) Verify the execution plan:
terraform plan
e) Execute the actions proposed in the Terraform plan:
terraform apply --auto-approve
Testing the Solution
a) Navigate to the Cloud Scheduler Console and execute your job manually by clicking on RUN NOW:

b) Navigate to Spanner console and Backup/Restore tab you should see that a backup operation in progress:
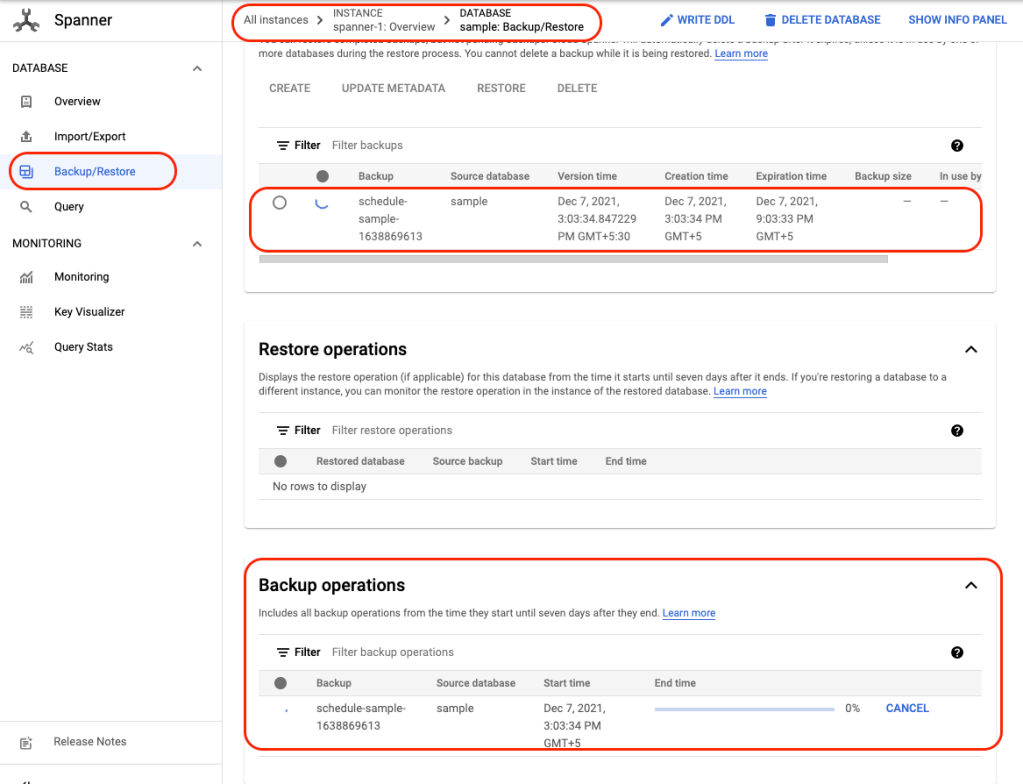
c) In case there are any errors, you can look at cloud function logs to find out what caused the backup failure:
Monitoring and Logging
In a future post, I’ll show you how to monitor spanner instances and spanner database automated backups. If you want to explore the spanner monitoring solution using Cloud Monitoring currently in development, you can do that by using and reviewing the code base here.
Cleaning Up
Once you’re done, you can use the Terraform Destroy command to clean up all the resources created by Terraform:
terraform destroy
Congratulations! You’ve just automated and scheduled a backup for spanner database(s) using Terraform.
Feel free to drop comments or questions in the comments and sign up for more updates here.
Google Cloud Consulting Services
Ready to optimize your use of Google Cloud's AI tools?
Share this
Share this
Viewing RMAN jobs status and output
Part 2: Oracle Cloud Backups to AWS S3
