I've already written about my experience with AWS
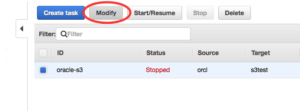
Database Migration Service (DMS) a couple of times. But the DMS team in Amazon was not sitting still and was working on the service, adding new features and targets for replication. Let me refresh your memory and briefly describe what DMS is and what the service does for you. The AWS DMS is a replication solution which can help you to migrate your data from one database to another and, in addition to that, can also keep the data in sync using logical replication between source and target. In other words it is a logical replication tool that allows you to sync data between different databases where one database can be a completely different type from another. You can sync MySQL database with a schema in Oracle or in RedShift on AWS. It provides enough options to setup a proper data flow between different data solutions. So, it is not only a migration, but also a replication and data integration solution. I started to work with the DMS as soon as it had became generally available more than a year ago. When I was working, I tried to stay in touch with the DMS team at Amazon sharing my experience and what I would like to see in the new versions. After some time I have to admit the team has done a pretty good job adding new features to the service, improving interface and adding new sources and targets for migration and replication. In this post, I will try to describe some of the new features I liked. One of the first and most important for me is the ability to modify the tasks. Now we can modify an existing task without dropping and recreating it from scratch. It may not look very important for those who don't use DMS for continuous replication. But if you do, you are going to appreciate the feature. For example, you can enable logging or change mapping by adding or deleting rules for your replication task. You can have a look at options in AWS CLI or just push the “modify” button in AWS console for DMS replication tasks. Here is what you see as options for the “modify” command for a dms task in AWS CLI:
 Add the transformation rule:
Add the transformation rule:
 Reload the table:
Reload the table:
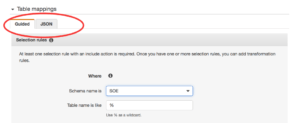
 We also have some improvements in the interface. When we modify or create mapping rules we can switch between a wizard with drop down menus and a pure json format tab where we can write our rules directly. It may be useful when you want just copy paste some rules from a prepared templates. Or you can prepare the rules using the wizard and copy paste to a json file for AWS CLI.
We also have some improvements in the interface. When we modify or create mapping rules we can switch between a wizard with drop down menus and a pure json format tab where we can write our rules directly. It may be useful when you want just copy paste some rules from a prepared templates. Or you can prepare the rules using the wizard and copy paste to a json file for AWS CLI.
 DMS has introduced new targets such as S3 or DynamoDB. S3 looks especially promising. Just think, you can stream your data in real time to S3 storage storing as csv files to use it later for MapR jobs, Athena database or just to keep an archive of all the changes. The initial data will be written as a csv file to a chosen S3 bucket with hierarchy of folders representing database name, schema name and table. The initial load has a name or names starting from "LOAD...". The changes to the table will have slightly different csv files and all change records are going to have a flag column with an operation type. It doesn't have a timestamp for each operation but you can reconstruct state or the data more or less accurately using the CDC files as boundaries between different times. The new files will have date and times in their names. Here is a listing of files for one table with initial load and following changes:
DMS has introduced new targets such as S3 or DynamoDB. S3 looks especially promising. Just think, you can stream your data in real time to S3 storage storing as csv files to use it later for MapR jobs, Athena database or just to keep an archive of all the changes. The initial data will be written as a csv file to a chosen S3 bucket with hierarchy of folders representing database name, schema name and table. The initial load has a name or names starting from "LOAD...". The changes to the table will have slightly different csv files and all change records are going to have a flag column with an operation type. It doesn't have a timestamp for each operation but you can reconstruct state or the data more or less accurately using the CDC files as boundaries between different times. The new files will have date and times in their names. Here is a listing of files for one table with initial load and following changes:
modify-replication-task
--replication-task-arn
[--replication-task-identifier ]
[--migration-type ]
[--table-mappings ]
[--replication-task-settings ]
[--cdc-start-time ]
[--cli-input-json ]
[--generate-cli-skeleton ]
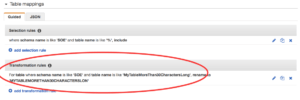
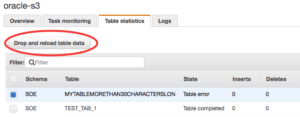
Another cool new feature is the ability to reload individual tables without impacting entire replication. It is a really useful addition. Here is an example: You have setup a replication from MySQL to an Oracle RDS instance 11gr2 or 12cr1 for entire Oracle schema. Everything works fine, but some time later a new release of software adds a new table on source MySQL schema with more than 30 characters in the name. It will break the replication for the table because you cannot have a table with 30+ characters in the name in Oracle 11g or 12cr1. But now we can create the new table on the target site, add a rename rule for the table and reload only one affected table. Modify the task:
Add the transformation rule:
Reload the table:
We also have some improvements in the interface. When we modify or create mapping rules we can switch between a wizard with drop down menus and a pure json format tab where we can write our rules directly. It may be useful when you want just copy paste some rules from a prepared templates. Or you can prepare the rules using the wizard and copy paste to a json file for AWS CLI.
DMS has introduced new targets such as S3 or DynamoDB. S3 looks especially promising. Just think, you can stream your data in real time to S3 storage storing as csv files to use it later for MapR jobs, Athena database or just to keep an archive of all the changes. The initial data will be written as a csv file to a chosen S3 bucket with hierarchy of folders representing database name, schema name and table. The initial load has a name or names starting from "LOAD...". The changes to the table will have slightly different csv files and all change records are going to have a flag column with an operation type. It doesn't have a timestamp for each operation but you can reconstruct state or the data more or less accurately using the CDC files as boundaries between different times. The new files will have date and times in their names. Here is a listing of files for one table with initial load and following changes:
-MacBook:~ $ aws s3 ls dms-test/orcl/SOE/TEST_TAB_1/
2017-07-05 12:21:22 61 20170705-1621214802.csv
2017-07-05 12:25:08 121 20170705-1625072299.csv
2017-07-05 12:27:14 145 20170705-1627134624.csv
2017-07-05 12:18:17 177 LOAD00000001.csv
-MacBook:~ $
It looks good but be careful, keep in mind that the load file doesn't have flag of operation at all. An insert and a delete have their "I" and "D" as the first column and an update puts the "U" to the second column. Here is how it looks. Load:
1.0000000000,FE0MYZFT,2017-07-04 19:13:50,UVO6BCPH,2017-07-04 19:13:50
Insert:
I,501.0000000000,FTCTUP89,2017-07-05 16:25:52,30TTQ3P6,2017-07-05 16:25:52
Delete:
D,502.0000000000,1YN1ZGB4,2017-07-05 15:10:24,VSWJB3QL,2017-07-05 15:10:24
Update:
501.0000000000,U,TEST 01,2017-07-05 16:25:52,30TTQ3P6,2017-07-05 16:25:52
A truncate is going to wipe out all the files related to the table from S3 bucket but a dropping the table will not do the same. Interesting that after a dropping your table on source you still have all the files. Of course, we still have some issues with the service. In my upcoming posts, I will share latest problems I had with the service and the workaround I used. As a short summary I can say that I've listed only few of new features and improvements in DMS, but it is clear that the service is moving in the right direction and getting better and better. Of course you still get some problems here and there but I think the DMS team does pretty good job and hope it will stay on that track.
On this page
Share this
Share this
Optimizing CPU cores and threads for Oracle on AWS
![]()
Optimizing CPU cores and threads for Oracle on AWS
Jul 18, 2018 12:00:00 AM
4
min read
Backup Oracle E-Business Suite Running on AWS EC2

Backup Oracle E-Business Suite Running on AWS EC2
Jun 21, 2023 12:00:00 AM
5
min read
An Introduction to Chrome Browser Management
![]()
An Introduction to Chrome Browser Management
Aug 9, 2020 12:00:00 AM
2
min read