Azure Data Factory – Self Hosted IR (Scaling, Best Practices and Disaster Recovery Solutions) | Official Pythian®® Blog
7:08
We are going to explore following about Self Hosted Integration runtime for Azure Data Factory
When and How to scale Self Hosted IR for Data Factory?
Some best practices you should consider for Self Hosted IR
Disaster Recovery Solutions for Self Hosted IR
Scaling of self hosted IR
Identifying self hosted IR bottlenecks
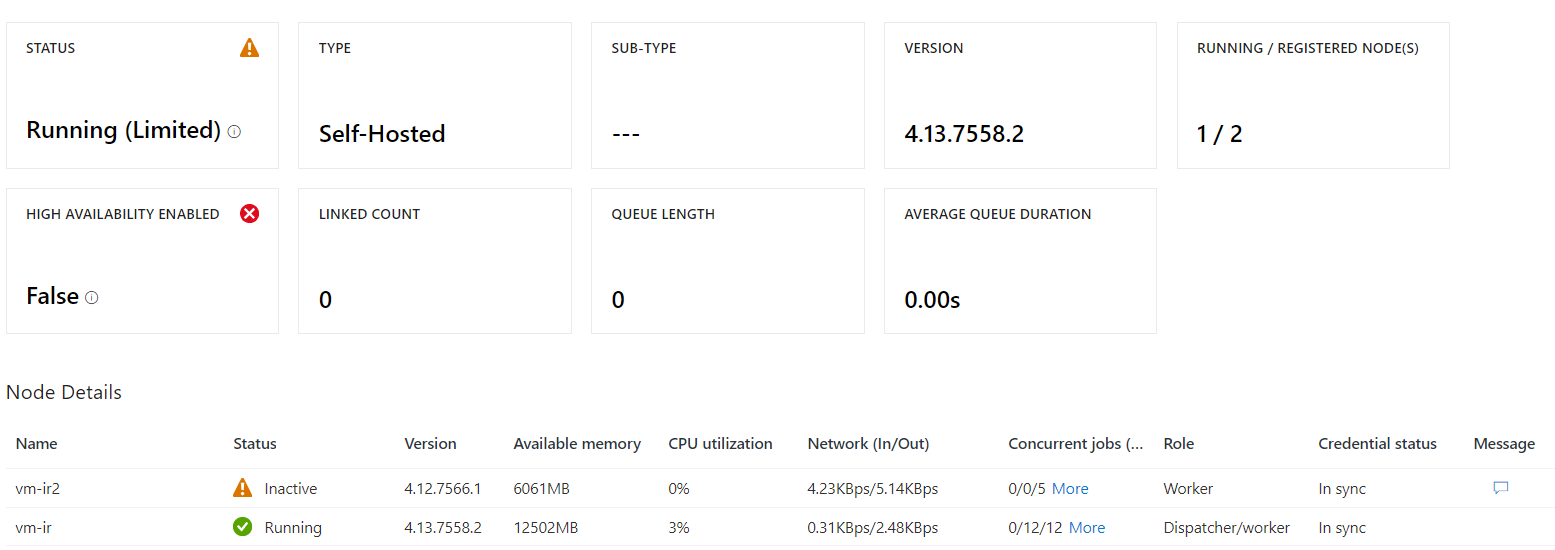
How do we know if there are some bottlenecks with Self Hosted Integration runtime? How do we know that we need to scale the nodes included in the runtime environment? There are 4 metrics that can help you measure the performance or your hosted IRs.
Average Integration runtime CPU utilization – Average CPU utilization of nodes in IR. A threshold continuous breaching 80% mark indicates a serious CPU bottleneck.
Average Integration runtime available memory. Average memory available on the nodes. A lower value indicates memory congestion.
Average Integration runtime queue length – Average number of pipelines or activity runs in a queue. A higher count indicates IR resource congestion\bottleneck.
Average Integration runtime queue duration – Average Amount of time the job waits in the job before it gets scheduled. Higher values indicate congestion.
You can easily look at these details under the details pane for your integration runtime.
These details are only current and to take proper action you will need to compare these metrics over a period of time. To understand the usage of these metrics over a period of time we need to set up a dashboard in Azure and explore these metrics over a period of time. Use the sample dashboard here and import it into your Azure Portal Dashboards to monitor all these metrics in one place using charts (for each of the listed metrics above). To get started, download the JSON file from GIT. Once downloaded, update the file for following placeholders using find and replace in the text editor. <<Subscription ID>> – Your Subscription ID. <<Resource Group Name>> – Resource Group Name for Data Factories. <<Data Factory Name>> – Name of Data Factory (Only 1 is supported per dashboard) Once the file is updated you can navigate to dashboards in Azure Portal.
and upload the json file you updated in the previous step.
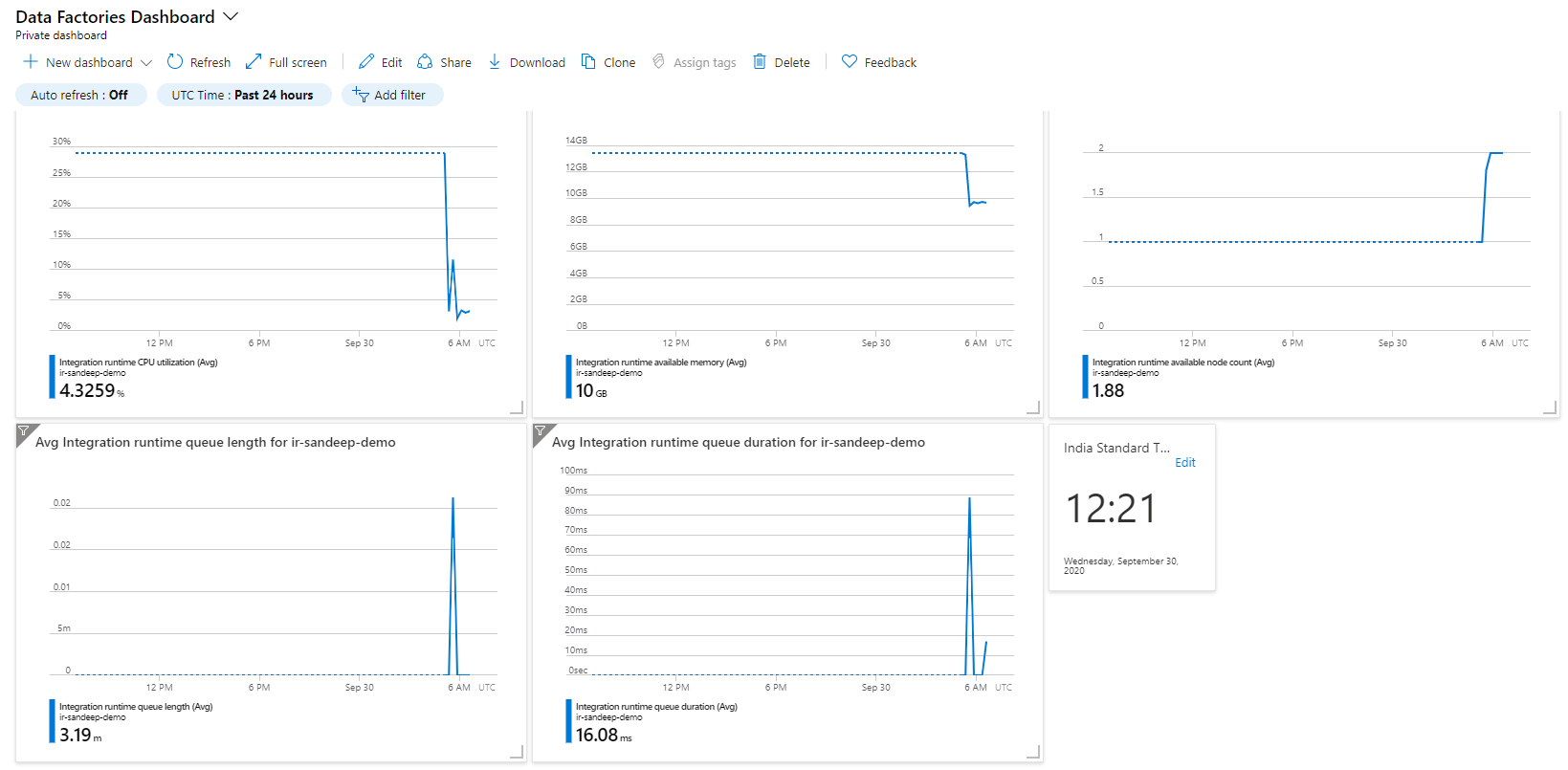
This should set up your ADF dashboard and you monitor the metrics based on duration. This dashboard will help you understand if there are any bottlenecks in your ADF. Following is what the dashboard looks like when imported successfully.
Note: For multiple data factories you will need to create multiple dashboards. The dashboards are named after Data Factory names for ease of identifying the factory.
When to scale out?
When processor usage is continuously hovering over the 80% mark, available memory is low on the self-hosted IR, and average queue length and duration indicates higher value count, add a new node to help scale out the load across machines. If activities fail because they time out or the self-hosted IR node is offline, it helps if you add a node to the gateway.
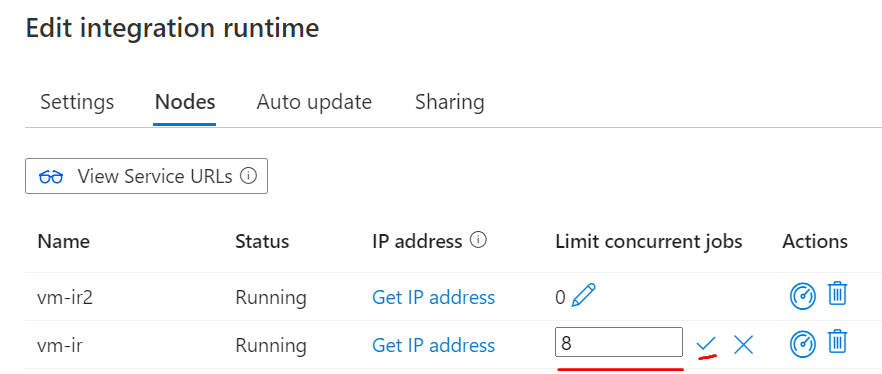
When to scale job capacity for nodes?
When the processor and available RAM aren’t well utilized, but the execution of concurrent jobs reaches a node’s limits, scale up by increasing the number of concurrent jobs that a node can run. You might also want to scale up job capacity when activities time out because the self-hosted IR is overloaded. As shown in the following image, you can increase the maximum capacity for a node:
When to scale up?
The maximum nodes you can add to Self Hosted IR for HA and Scalability is 4. Once you can’t scale and add more nodes consider increasing the CPU and RAM of the nodes
For Azure VM – Change the Node Size to larger size.
For On Prem Nodes – Move to a large machine with more RAM and CPU.
After scaling up, adjust the number of concurrent jobs that a node can run.
Best practices for self hosted IR
Configure a power plan on the host machine for the self-hosted integration runtime so that the machine doesn’t hibernate. If the host machine hibernates, the self-hosted integration runtime goes offline.
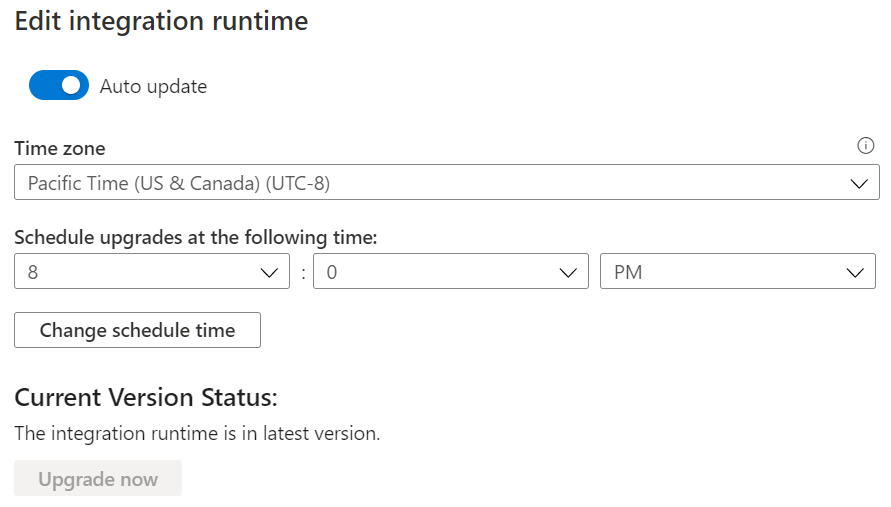
Ensure the Auto Update is set for Integration Runtime Environment and all nodes are up-to-date. A node which is not updated to the latest version will be offline and not be used for scheduling.
You can use a single self-hosted integration runtime for multiple on-premises data sources. You can also share it with another data factory within the same Azure Active Directory (Azure AD) tenant.
It is recommended that you install the self-hosted integration runtime on a machine that differs from the one that hosts the on-premises data source. When the self-hosted integration runtime and data source are on different machines, the self-hosted integration runtime doesn’t compete with the data source for resources.
If you have multiple nodes in Self hosted IR and they are underutilized or to ensure optimal utilization of resources you can consider reusing an existing self-hosted integration runtime infrastructure. This reuse lets you create a linked self-hosted integration runtime in a different data factory by referencing an existing shared self-hosted IR.
Details on shared self-hosted IR can be found here. Details on setting up a shared self-hosted IR can be found here.
Disaster recovery (or high availability)
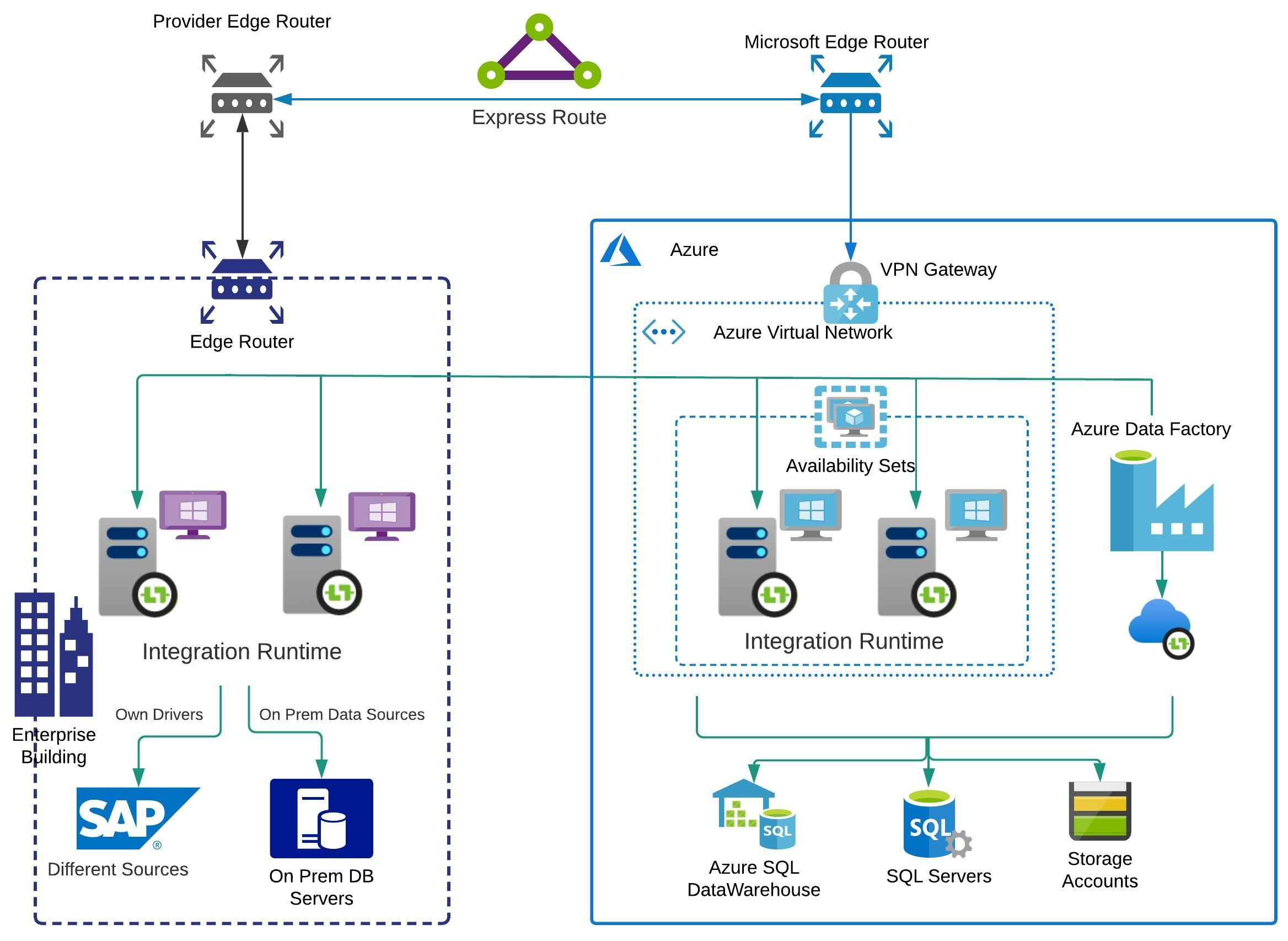
There is no out of the box disaster recovery feature available with Integration runtime currently. If service stops due to any error, you will have to manually restart the service. You should ideally set up multiple nodes for Integration Runtime. This avoids having a single point of failure and provides higher throughput, as all nodes are set up as active. Please refer to the below illustration for more detailed information on the setup.
We can have up-to 4 Nodes associated with a self-hosted integration runtime spread across on-premises and Azure. To ensure maximum availability for Azure nodes we can have the nodes configured with either Availability Sets or Availability Zones (if supported by region). To ensure maximum availability for on-premises nodes they should be created on separate racks\hardware. This availability helps ensure continuity when you use up to four nodes. This setup also offers scalability, improved performance and throughput during data movement between on-premises and cloud data stores. For more details, refer to the link here that points to the section on High Availability and Scalability, with details on setting up multiple nodes (up-to 4). Note: Before you add another node for high availability and scalability, ensure that the Remote access to intranet option is enabled on the first node. To do so, select Microsoft Integration Runtime Configuration Manager > Settings > Remote access to intranet. You will need to ensure that your network setup allows on-premises data sources to be accessible from Azure vnet and vice versa.