On this page
Share this
Share this
Cassandra as a time series database
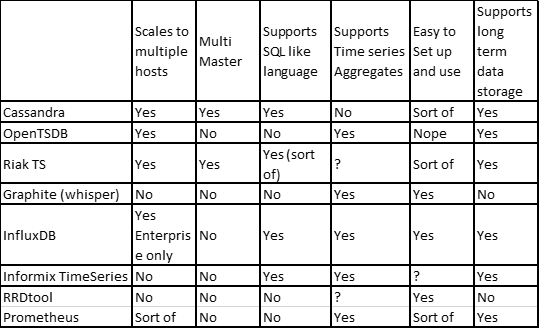
Cassandra as a time series database
Mar 23, 2018 12:00:00 AM
6
min read
Cassandra use cases: when to use and when not to use Cassandra
![]()
Cassandra use cases: when to use and when not to use Cassandra
Mar 21, 2018 12:00:00 AM
6
min read
Cassandra Vulnerability - CVE-2020-13946 - Apache Cassandra RMI Rebind Vulnerability
![]()
Cassandra Vulnerability - CVE-2020-13946 - Apache Cassandra RMI Rebind Vulnerability
Sep 2, 2020 12:00:00 AM
1
min read