Context
If you’ve used Google Maps for directions or “friended” someone on Facebook, you’ve experienced graph theory. Graph theory is all about connectedness, how things in the world relate to other things, and how those interactions affect the objects around them.
Graph theory exposes insights from data differently than traditional analytical methods. Imagine a retailer initiates a marketing campaign and wishes to monitor the effectiveness of the campaign using online tracking tools and analytics. Suppose Person-A sees the ad but does not purchase the product, rather Person-A tells Person-B about the product who did not see the ad but buys the product. Traditional analytics would determine that the ad campaign had nothing to do with the subsequent purchase. Graph technology on the other hand can leverage the connectedness of people, places and things and the relationships between them to provide hidden information which may correlate the connections to the ad campaign and subsequent sale.
Graph theory actually dates back to the mid eighteenth century when mathematician Leonhard Euler set out to solve the Seven Bridges of Konigsberg math puzzle which described several islands and a land mass divided by two rivers and connected by seven bridges. The problem required one to find a route to every land mass by only crossing each bridge once. Short answer is you can’t; you need an even number of bridges. (You can learn more about this particular problem here).

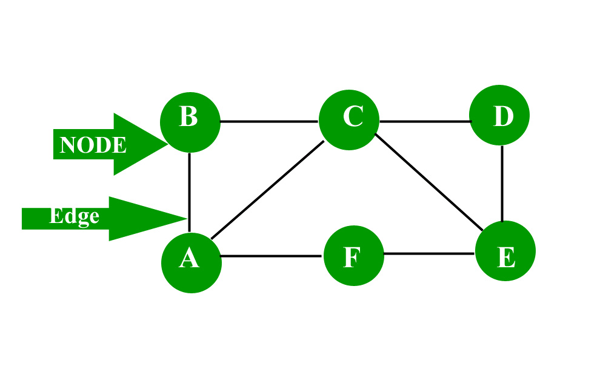
The fundamental precepts of graph theory are nodes and edges. Nodes represent things, and edges represent the relationship between the edges.
Properties
The edges can have properties of directionality or transitivity. Directionality means that a relationship is either bi-directional or one way. Transitivity is a type of hierarchical inheritance or equivalence. Directionality is helpful for node traversal, say in a shortest-path problem where one wants to find the shortest path between nodes A and D. Transitivity provides for the equation B = C, C = D therefore B = D. Transitivity is helpful in hierarchical scenarios.
Graphs can be cyclic or acyclic. In acyclic graphs, the traversal of the graph starts at some node and ends at another node, never traversing the same node twice. In cyclic graphs, the traversal can traverse the same nodes repetitively. Graphs can also be directional or non-directional meaning that traversal of the graph is only in one direction (directional) or is bi-directional (non-directional).
Anyone who is familiar with DevOps orchestration will be familiar with DAGS or directed acyclic graphs. DAGS describes a workflow which traverses n number of nodes to a terminus in order to complete a task.
Basic graph algorithms include “shortest path” which is a simple way to find the shortest route between two nodes, and “least cost” which assigns a cost to each edge. As the name implies, it finds a least-cost path between nodes. Least cost is widely used in network routing protocols. Least cost algorithms are effective at rerouting due to failures or blockages such as a traffic jam on a mapping program. You can refactor costs at any point to manipulate the routing function.
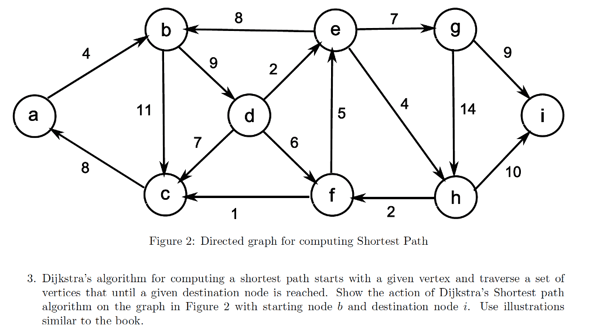
In the 1990’s a large Yellow Pages advertiser contracted my company to develop a web-based “dealer locator” application. The company was early in exploiting the nascent World Wide Web at the time. They wanted to upsell their Yellow Pages advertisers a web presence and allow retailers’ customers to find a store near them online. We take this for granted today, but in 1997 it did not exist.
We used a new option in the Oracle database called Spatial Data Option, which allowed us to do multi-dimensional queries based on geographic location and perform shortest path queries in SQL. To access the latitude and longitude of every zip code in the country, we purchased a list of zip code centroids from the US Post Office. We then joined the centroid zip with a store’s zip which gave us an approximate cartesian coordinate for the store.
The first customer to purchase this product was a national muffler company. We POC’d (proof of concept) it initially in the NYC area. The first problem we encountered was that the shortest distance between point A and point B wasn’t necessarily the right answer. For example, to a person living on the north shore of Long Island the nearest shop, as the crow flies, was in Connecticut, across the Long Island Sound. Unless they had a boat, this was definitely not their closest shop. Obviously we needed to introduce cost functions into our algorithms. A high cost across the sound resolved the issue.
“Centrality” algorithms focus on finding clusters of nodes, or nodes with many connections relative to their neighbors. An example of centrality is in web page ranking calculations. These measure the number of links to the page from other pages vs the number of links referenced, to serve as a measure of the popularity of the page.

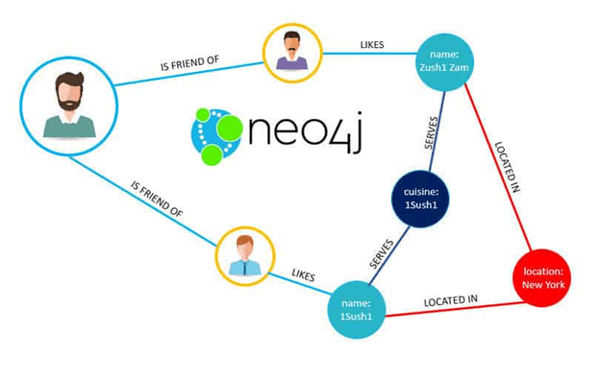
Neo4J is an open source graph platform which includes a query language called Cypher to exploit the various graph algorithms. Neo4J is just one of several different graph platforms, others include RedisGraph, DataStax and Oracle RDFGraph. (To learn more about Neo4J, please visit the Neo4J documentation).
While Neo4J and other query platforms are popular today, their predecessors date back a decade and a half to a W3C (World Wide Web Consortium) effort in the mid 2000’s.
Implementation
While working at a major database vendor I was leading a development effort in the support organization. My team developed tools for their support portal, and one such project was a comprehensive “certification matrix” of all the company’s products. The company had acquired dozens of companies and thousands of products during that time. It was impossible to seamlessly trace the certification of one product with any other. There were only islands of certification information.
The scope of the problem was considerable when you understood the company’s product hierarchy starting at the lowest level with servers, up through operating systems, relational databases, middleware, application suites and literally thousands of software options that were integrated into all aspects of their product line. Using “semantic” data we were able to “infer” certifications between islands of certification and provide a seamless relationship between any two products.
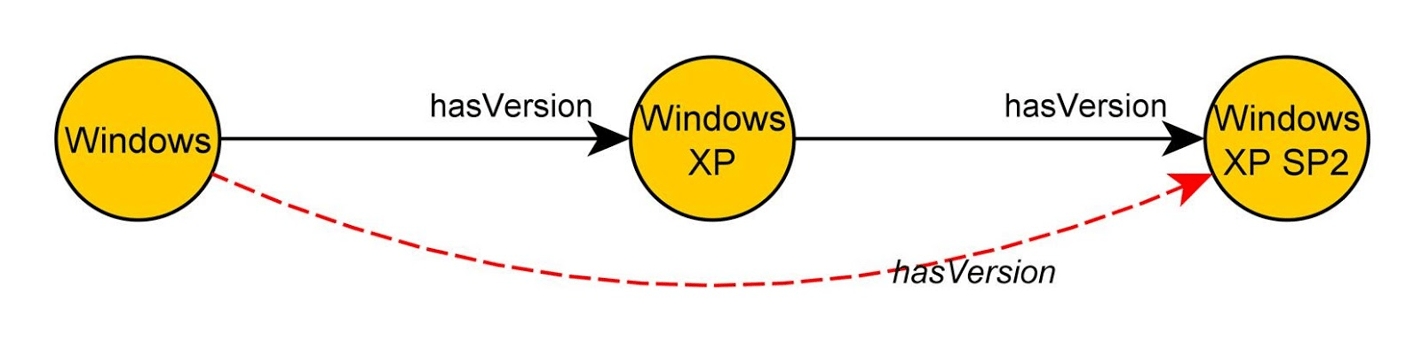
My research led me to a Tim Berners Lee project called the Semantic Web. From Wikipedia: “The goal of the Semantic Web is to make Internet data machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata.”
RDF is structured as “triples” consisting of a “subject” node, a “predicate” edge and an “object” node.

The RDF relationship between subjects and objects is described by the predicate, e.g. Tom? hasFriend? Bob. Subjects and objects can describe “things” and are the basis for ontologies. Similarly to taxonomies, which are purely hierarchical, e.g. animals -> mammals -> dogs -> beagles, ontologies convey the relationship between “things.” The object of one subject can be the subject of another object; in other words an entity can be both a subject and an object at the same time. Sometimes an entity is the subject and object to itself.
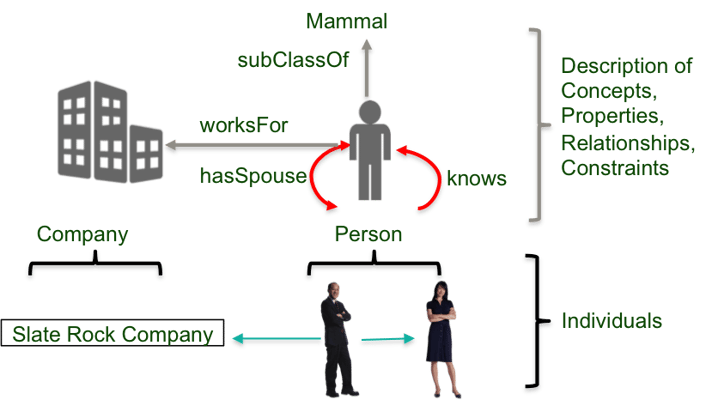
RDF has similar concepts as object-oriented models where one defines classes of entities, and the instantiation of a class is an object, e.g. Bob is an instantiation of a person class, which is a sub-class of mammal.
One defines the relationships (predicates) between classes. Instantiated classes (subjects and objects) are then interpreted by a “reasoner” to make inferences. Note the difference between objects, as a classic object-oriented term, and objects, as an RDF representation.
RDF has a schema specification called RDFS and is based on XMLS. OWL is an extension of RDF which provides an inferencing vocabulary.
Modern day analytics and machine learning models focus on “prediction” or “classification.” Most predictive analytics are based on statistical regressions and aim to predict a future value based on a given input to a model trained on historical data. Neural nets are based on weighted inputs in order to discern patterns. Relational databases can only query explicitly structured data and are limited to returning previously known data and relationships.
RDF and OWL derive meaning from a dataset to “infer” new information based on limited known information.
The OWL specification provides “predicate” properties which allow OWL “reasoners” to make inferences. Below we can infer that John Smith lives in England. There is no database entry that explicitly says that John lives in England, and unless that relationship is structured into the schema and query with forethought, that result could never be returned by a SQL query. Inference is all about discovery.

Properties are assigned to predicates and describe the relationship between subjects and objects. A predicate can be any phrase or description which makes sense. Properties, on the other hand, are defined in the RDF and OWL specifications.
Importance
Reasoners are software engines that will look at an entire ontology, and infer information based on the existing dataset. Unlike AI/ML models, reasoners do not predict a future outcome; they uncover hidden relationships that were never defined to begin with. Inference is extremely powerful when you have datasets that contain many thousands or millions of nodes, and thousands of different predicates describing relationships between things. A good example is in biology and life sciences when looking at the interactions between proteins.
The most basic of the properties are “transitive” properties. Referring back to my product certification project we used the transitive property on the predicate isCertifiedWith to infer the gaps between certification groups. We were also able to reconcile multiple product databases that would refer to the same product with different names, e.g. database A. referred to Oracle 10g, another would refer to the same product as RDBMS 8.1.2.4. By using the sameAs property we could infer that a product certified with Oracle 10g was also certified with RDBMS 8.1.2.4 despite the fact that that relationship did not exist in the latter.
The RDF and OWL vocabularies are quite complex and can be difficult to wrap one’s head around. I personally spent two years designing OWL ontologies and only scratched the surface. The complexity was one of the reasons for the lack of widespread adoption of OWL by end users. The concepts lived on however, and were the basis for “friends-of-friends” (FOF) algorithms. These algorithms provided the genesis of today’s social media platforms. They’re also widely used in physics particle simulations.
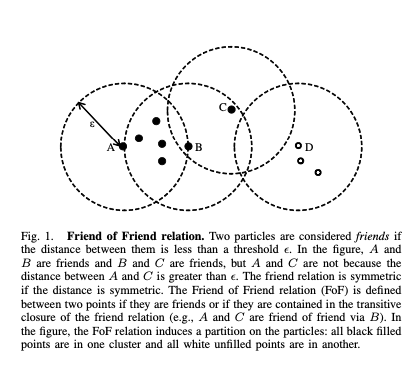
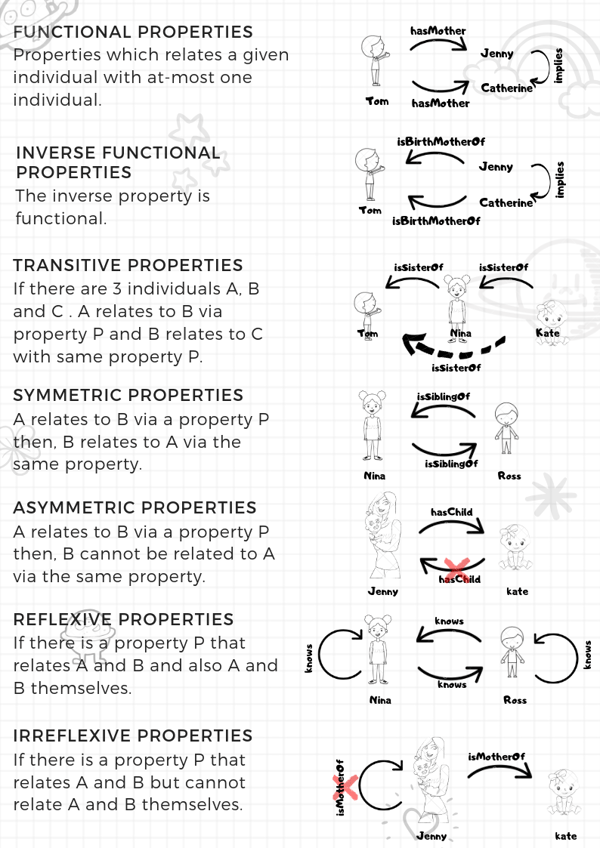
In the above examples we can infer the following:
- Jenny is the same person as Catherine.
- Kate is Tom’s sister.
Additionally we could have added a person, Robert, and defined the functional property isMarriedTo between Catherine and Robert. Using an asymmetric property isBirthFatherOf we could infer that Robert is Kate, Tom’s and Nina’s father through his relationship with Catherine, and additionally that Robert is married to Jenny.
The magic of inference is that the data relating Robert to his kids was not entered in any way in the dataset. In effect, the original schema has been automatically augmented by the new inferred information. One could never do this with relational databases or normal graph databases because they can only recover what was already known. Inference becomes invaluable in life sciences when exploring molecular biology pathways in proteins and genetic research. Where ML/AI models predict the future based on current data, inference looks at the entire dataset and infers what was never explicitly articulated.
Conclusion
The Spatial Data and RDF options have been merged in the 19c version of the Oracle database. A quick Google search highlights a few open source projects that provide RDF and OWL capabilities in Neo4J and NoSQL databases. It bears saying again that RDF and OWL never quite found widespread acceptance except in the national security, life sciences and physics communities. The reasoners of the day were very compute intensive and it was extremely difficult for most data practitioners to fully grasp the concepts. Many ontology categorization projects ended up going down rabbit holes since it is difficult to determine where to start and end an ontology.
I hope you’ve enjoyed these thoughts on graph theory. If you have any questions, or anything to add, please feel free to do so in the comments.
SQL Server Database Consulting Services
Ready to optimize your SQL Server Database for the future?
Share this
Share this
How to Install a Clustered SQL Server 2012 Instance – Part 4