On this page
Share this
Share this
Analytics with Limitless Scale on Microsoft Azure - Part 1
![]()
Analytics with Limitless Scale on Microsoft Azure - Part 1
Dec 17, 2019 12:00:00 AM
3
min read
How to fix SSIS deployment error "please create a master key"
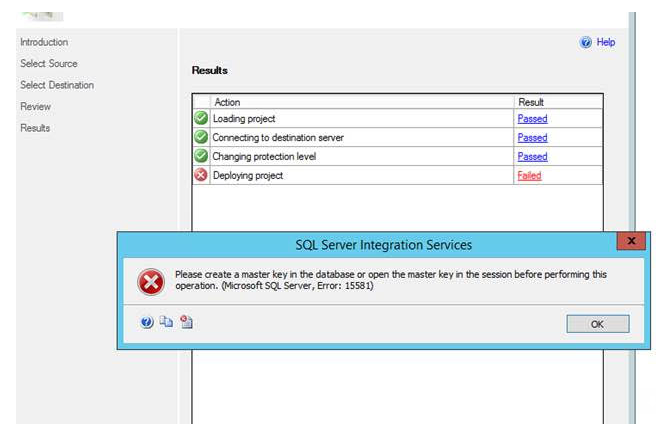
How to fix SSIS deployment error "please create a master key"
Apr 24, 2019 12:00:00 AM
2
min read
Leveraging Azure Synapse Analytics Service Integrations

Leveraging Azure Synapse Analytics Service Integrations
Jan 20, 2022 12:00:00 AM
6
min read