Those who work with Merge replication know replicating articles with identity columns need some planning, especially if the identity column is part of the primary key or if there are many subscribers. Merge replication provides automatic identity range management across replication nodes that can offset the overhead of managing them manually. This blog will briefly shed some light on identity range management and how it works. In
part 2, we will explore a specific case when batch inserts can affect the identity range management.
Why Identity Columns ? Identity columns are very popular (and even touted more by DBA's) to use as Primary Keys other than GUIDs for multiple reasons, including :
How Merge Replication Manages Identity Ranges: So you have a few articles with identity columns that you want to replicate between a publisher and few subscriptions in a merge replication setup so the subscribers will also be able to update data back. Each “node” in the replication topology should be assigned a range which the user processes will use and then replicate to other nodes. It is important, especially if identity column is part of primary key, that no duplicates happen. Let’s say we want to publish one article with identity column as a primary key to two subscribers. If we do not assign the correct ranges to each “node” here, then it’s possible that user processes will create same identity values. Once the merge agent tries to synchronize, it will insert duplicate values to the tables from other nodes and will fail if identity column is part of a primary key. If we designate that each “node” gets isolated range of identity values, then user application will write values that cannot be used elsewhere. This is simply what Automatic Identity range does! - On the publisher , the identity pool is used to assign values when adding new articles. There are two kinds of pools (ranges) Example: If we configure the publisher to have range from 1-1000, Subscriber 1 to have 1100-2100 and subscriber 2 to have range from 2200-3200, then merge replication should NOT insert any duplicate values at any nodes. Kindly note that Merge agent processes do NOT increase the identity values when synchronizing , they just insert the plain values, like the case when we use “set identity_insert ON”!
How the Ranges are Enforced Through the usage of constraints on the identity column. Starting with SQL server 2005, each node is assigned two ranges, primary and secondary. Both primary and secondary ranges are equal in size and once the primary range is exhausted, the secondary one is used and merge agent assigns a new range to subscriber (becoming the secondary range); this is when automatic range management is chosen when the article is added (please see @identityrangemanagementoption parameter of sp_addmergearticle). If you need more documentation, please refer to the following links:
https://blogs.msdn.com/b/suhde/archive/2010/03/21/inf-automatic-identity-range-management-with-merge-replication-in-microsoft-sql-server-2005-2008.aspx Now some hands on!
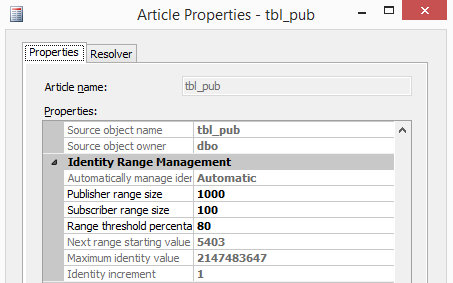
A Simple Tutorial Let us demonstrate a very simple merge replication topology with a publisher and two subscriptions. I am doing this on the same instance of my machine. The instance has to have SQL server agent to run job so STD, DEV or ENT edition is needed. Let’s create three user databases and one table under the database that will be published: [sourcecode language="sql"] Use Master GO Create database Pub; GO Create database sub1; GO Create database sub2; GO create table pub.dbo.tbl_pub (col1 int identity(1,1), col2 datetime) GO [/sourcecode] Enable distributor feature and create distribution database: [sourcecode language="sql"] use master GO Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_adddistributor @distributor = @instance, @password = N'' exec sp_adddistributiondb @database = N'distribution', @log_file_size = 2, @min_distretention = 0, @max_distretention = 72, @history_retention = 48, @security_mode = 1 exec sp_adddistpublisher @publisher = @instance , @distribution_db = N'distribution', @security_mode = 1,@trusted = N'false', @thirdparty_flag = 0, @publisher_type = N'MSSQLSERVER' GO [/sourcecode] Create publication and add article: [sourcecode language="sql"] use [Pub] exec sp_replicationdboption @dbname = N'Pub', @optname = N'merge publish', @value = N'true' GO -- Adding the merge publication use [Pub] exec sp_addmergepublication @publication = N'Pub1', @sync_mode = N'native', @retention = 14, @allow_push = N'true', @allow_pull = N'true', @allow_anonymous = N'false', @publication_compatibility_level = N'100RTM', @replicate_ddl = 1 GO exec sp_addpublication_snapshot @publication = N'Pub1', @frequency_type = 1, @frequency_interval = 0, @frequency_relative_interval = 0,@publisher_security_mode = 1 use [Pub] exec sp_addmergearticle @publication = N'Pub1', @article = N'tbl_pub', @source_owner = N'dbo', @source_object = N'tbl_pub', @type = N'table', @pre_creation_cmd = N'drop', @schema_option = 0x000000010C034FD1, @identityrangemanagementoption = N'auto', @pub_identity_range = 1000, @identity_range = 100, @threshold = 80, @destination_owner = N'dbo', @force_reinit_subscription = 1, @column_tracking = N'false', @allow_interactive_resolver = N'false' GO [/sourcecode] The important parameters here are @pub_identity_range = 1000, @identity_range = 100 @identity_range is what is allocated to the publisher and subscribers (i.e: this is the range that controls the values inserted on the publisher and subscribers as well).
Example: If we configure the publisher to have range from 1-1000, Subscriber 1 to have 1100-2100 and subscriber 2 to have range from 2200-3200, then merge replication should NOT insert any duplicate values at any nodes. Kindly note that Merge agent processes do NOT increase the identity values when synchronizing , they just insert the plain values, like the case when we use “set identity_insert ON”!
How the Ranges are Enforced Through the usage of constraints on the identity column. Starting with SQL server 2005, each node is assigned two ranges, primary and secondary. Both primary and secondary ranges are equal in size and once the primary range is exhausted, the secondary one is used and merge agent assigns a new range to subscriber (becoming the secondary range); this is when automatic range management is chosen when the article is added (please see @identityrangemanagementoption parameter of sp_addmergearticle). If you need more documentation, please refer to the following links:
https://blogs.msdn.com/b/suhde/archive/2010/03/21/inf-automatic-identity-range-management-with-merge-replication-in-microsoft-sql-server-2005-2008.aspx Now some hands on!
A Simple Tutorial Let us demonstrate a very simple merge replication topology with a publisher and two subscriptions. I am doing this on the same instance of my machine. The instance has to have SQL server agent to run job so STD, DEV or ENT edition is needed. Let’s create three user databases and one table under the database that will be published: [sourcecode language="sql"] Use Master GO Create database Pub; GO Create database sub1; GO Create database sub2; GO create table pub.dbo.tbl_pub (col1 int identity(1,1), col2 datetime) GO [/sourcecode] Enable distributor feature and create distribution database: [sourcecode language="sql"] use master GO Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_adddistributor @distributor = @instance, @password = N'' exec sp_adddistributiondb @database = N'distribution', @log_file_size = 2, @min_distretention = 0, @max_distretention = 72, @history_retention = 48, @security_mode = 1 exec sp_adddistpublisher @publisher = @instance , @distribution_db = N'distribution', @security_mode = 1,@trusted = N'false', @thirdparty_flag = 0, @publisher_type = N'MSSQLSERVER' GO [/sourcecode] Create publication and add article: [sourcecode language="sql"] use [Pub] exec sp_replicationdboption @dbname = N'Pub', @optname = N'merge publish', @value = N'true' GO -- Adding the merge publication use [Pub] exec sp_addmergepublication @publication = N'Pub1', @sync_mode = N'native', @retention = 14, @allow_push = N'true', @allow_pull = N'true', @allow_anonymous = N'false', @publication_compatibility_level = N'100RTM', @replicate_ddl = 1 GO exec sp_addpublication_snapshot @publication = N'Pub1', @frequency_type = 1, @frequency_interval = 0, @frequency_relative_interval = 0,@publisher_security_mode = 1 use [Pub] exec sp_addmergearticle @publication = N'Pub1', @article = N'tbl_pub', @source_owner = N'dbo', @source_object = N'tbl_pub', @type = N'table', @pre_creation_cmd = N'drop', @schema_option = 0x000000010C034FD1, @identityrangemanagementoption = N'auto', @pub_identity_range = 1000, @identity_range = 100, @threshold = 80, @destination_owner = N'dbo', @force_reinit_subscription = 1, @column_tracking = N'false', @allow_interactive_resolver = N'false' GO [/sourcecode] The important parameters here are @pub_identity_range = 1000, @identity_range = 100 @identity_range is what is allocated to the publisher and subscribers (i.e: this is the range that controls the values inserted on the publisher and subscribers as well).
Start Merge agent for each subscription to push initial snapshot: -- job_name = ---- [sourcecode language="sql"] Exec msdb..sp_start_job @job_name='MYINSTANCE-Pub-Pub1-MYINSTANCE-3'; GO Exec msdb..sp_start_job @job_name='MYINSTANCE-Pub-Pub1-MYINSTANCE-4'; GO Waitfor delay '00:00:15' -- Get output of the merge agent use [master] exec [distribution].sys.sp_replmonitorhelpmergesession @agent_name = N'MYINSTANCE-Pub-Pub1-MYINSTANCE-3', @hours = -1, @session_type = 1 GO [/sourcecode]
This is where Merge replication metadata tracks the history allocated ranges:
https://technet.microsoft.com/en-us/library/ms182607.aspx [sourcecode language="sql"] select publication, article, subscriber, subscriber_db, range_begin, range_end, is_pub_range, next_range_begin, next_range_end from Distribution..MSmerge_identity_range_allocations order by range_begin GO [/sourcecode]
is_pub_range=1 is reserved for the subscribers in case they will re-publish the data. Let's check the schema on each table of the replication nodes: [sourcecode language="sql"] select 'Publisher' [Node], name, definition from pub.sys.check_constraints where type = 'C' and parent_object_id = (select object_id from pub.sys.objects where name ='tbl_pub') union all select 'Sub1', name, definition from Sub1.sys.check_constraints where type = 'C' and parent_object_id = (select object_id from Sub1.sys.objects where name ='tbl_pub') union all select 'Sub2', name, definition from Sub2.sys.check_constraints where type = 'C' and parent_object_id = (select object_id from Sub2.sys.objects where name ='tbl_pub') GO [/sourcecode]
Here we can see that each node has a primary and secondary range enforced through the constrainers. Let’s add some data! [sourcecode language="sql"] Insert into pub.dbo.tbl_pub (col2) select getdate(); Go 25 Insert into sub1.dbo.tbl_pub (col2) select getdate(); Go 25 Insert into sub2.dbo.tbl_pub (col2) select getdate(); Go 25 [/sourcecode] Start sync: [sourcecode language="sql"] Exec msdb..sp_start_job @job_name='MYINSTANCE-Pub-Pub1-MYINSTANCE-3'; GO Exec msdb..sp_start_job @job_name='MYINSTANCE-Pub-Pub1-MYINSTANCE-4'; GO [/sourcecode] Count rows in each table, should be 75 (3 * 25 rows) select (select count(*) from pub.dbo.tbl_pub),(select count(*) from sub1.dbo.tbl_pub), (select count(*) from sub2.dbo.tbl_pub) 75 --- 75 --- 75 Now, let's see what will happen when we insert many rows that exceed the range. Let’s start with the publisher. We had inserted 25 rows and the primary + secondary ranges are 200. Insert into sub1.dbo.tbl_pub (col2) select getdate(); Go 177 Let’s see the new range:
How? Well , the largest range last allocated was 4601 (republishing range).
How "new range" was allocated Under each table , there are 3 triggers corresponding for Insert, Update & Delete. The insert trigger ***On Publisher*** has an extra part to check for the identity range and use secondary range if Primary range is exhausted. If both primary and secondary range are exhausted, a new range is allocated. Here’s what the trigger code looks here: [sourcecode language="sql"] ALTER trigger [dbo].[MSmerge_ins_21A0E50FD0F64E439FE1349C1210247F] on [Pub].[dbo].[tbl_pub] for insert as declare @is_mergeagent bit, @at_publisher bit, @retcode smallint set rowcount 0 set transaction isolation level read committed select @is_mergeagent = convert(bit, sessionproperty('replication_agent')) select @at_publisher = 0 if (select trigger_nestlevel()) = 1 and @is_mergeagent = 1 return if is_member('db_owner') = 1 begin -- select the range values from the MSmerge_identity_range table -- this can be hardcoded if performance is a problem declare @range_begin numeric(38,0) declare @range_end numeric(38,0) declare @next_range_begin numeric(38,0) declare @next_range_end numeric(38,0) select @range_begin = range_begin, @range_end = range_end, @next_range_begin = next_range_begin, @next_range_end = next_range_end from dbo.MSmerge_identity_range where artid='21A0E50F-D0F6-4E43-9FE1-349C1210247F' and subid='95208516-4B98-451D-B264-C1F27B20449A' and is_pub_range=0 if @range_begin is not null and @range_end is not NULL and @next_range_begin is not null and @next_range_end is not NULL begin if IDENT_CURRENT('[dbo].[tbl_pub]') = @range_end begin DBCC CHECKIDENT ('[dbo].[tbl_pub]', RESEED, @next_range_begin) with no_infomsgs end else if IDENT_CURRENT('[dbo].[tbl_pub]') >= @next_range_end begin exec sys.sp_MSrefresh_publisher_idrange '[dbo].[tbl_pub]', '95208516-4B98-451D-B264-C1F27B20449A', '21A0E50F-D0F6-4E43-9FE1-349C1210247F', 2, 1 if @@error<>0 or @retcode<>0 goto FAILURE end end end -- [/sourcecode] The important part is this: [sourcecode language="sql"] if @range_begin is not null and @range_end is not NULL and @next_range_begin is not null and @next_range_end is not NULL begin if IDENT_CURRENT('[dbo].[tbl_pub]') = @range_end begin DBCC CHECKIDENT ('[dbo].[tbl_pub]', RESEED, @next_range_begin) with no_infomsgs end else if IDENT_CURRENT('[dbo].[tbl_pub]') >= @next_range_end begin exec sys.sp_MSrefresh_publisher_idrange '[dbo].[tbl_pub]', '95208516-4B98-451D-B264-C1F27B20449A', '21A0E50F-D0F6-4E43-9FE1-349C1210247F', 2, 1 -- [/sourcecode] A very important note: Only members of Db_owner will be able to allocate a new range. This is a limitation because, in many instances, you want to limit the permissions of your connected users. If the user inserting the data is not a member of DB_OWNER, then merge agent has to run OR you need to manually allocate a new range using sp_adjustpublisheridentityrange
https://msdn.microsoft.com/en-us/library/ms181527.aspx What about subscribers? Should we expect a new range to be generated if we insert more rows than the allowed range? Let’s see [sourcecode language="sql"] Insert into sub2.dbo.tbl_pub (col2) select getdate(); Go 175 use sub2 GO Dbcc checkident (tbl_pub , noreseed) --Checking identity information: current identity value '401', current column value '426'. --We just reached the limit of the secondary range, any new insert will violate the constraint unless a new range is allocated Insert into sub2.dbo.tbl_pub (col2) select getdate(); GO [/sourcecode]
Msg 548, Level 16, State 2, Line 1 The insert failed. It conflicted with an identity range check constraint in database 'sub2', replicated table 'dbo.tbl_pub', column 'col1'. If the identity column is automatically managed by replication, update the range as follows: for the Publisher, execute sp_adjustpublisheridentityrange; for the Subscriber, run the Distribution Agent or the Merge Agent. Why wasn't this handled like the publisher? Simply put , it’s by design. New ranges are allocated for subscribers when they sync with the publisher. This is even reflected in the trigger code. The following part is missing from the trigger on the subscriber side:
Conclusion Here we learnt few points: - Merge replication can handle identity ranges automatically. - Starting with SQL 2005 , there are two range pools assigned to each publisher and subscriber. - A republishing subscriber will have a "republishing" range to use for its own subscribers. - The size of each pool can be configured. Some recommendations here as well:
Why Identity Columns ? Identity columns are very popular (and even touted more by DBA's) to use as Primary Keys other than GUIDs for multiple reasons, including :
- They are smaller in size ; GUIDs are four times larger than INT
- Indexes over GUIDs tend to be larger. If the GUID is clustered index then it will affected every NON-Clustered index as well. Check out those two excellent blogs about GuIDs as PK and as Clustered indexes. https://www.sqlskills.com/blogs/kimberly/category/guids/
- Because they are random, indexes fragmentation are common on indexes over GUIDs. You can reduce this by using NEWSEQUENTIALID() function but it has a security disadvantage https://technet.microsoft.com/en-us/library/ms189786.aspx
How Merge Replication Manages Identity Ranges: So you have a few articles with identity columns that you want to replicate between a publisher and few subscriptions in a merge replication setup so the subscribers will also be able to update data back. Each “node” in the replication topology should be assigned a range which the user processes will use and then replicate to other nodes. It is important, especially if identity column is part of primary key, that no duplicates happen. Let’s say we want to publish one article with identity column as a primary key to two subscribers. If we do not assign the correct ranges to each “node” here, then it’s possible that user processes will create same identity values. Once the merge agent tries to synchronize, it will insert duplicate values to the tables from other nodes and will fail if identity column is part of a primary key. If we designate that each “node” gets isolated range of identity values, then user application will write values that cannot be used elsewhere. This is simply what Automatic Identity range does! - On the publisher , the identity pool is used to assign values when adding new articles. There are two kinds of pools (ranges)
- Pool assigned to publisher and subscribers that will be used directly to insert data in these subscribers.This is controlled through @identity_range parameter of sp_addmergearticle
- If any of the subscribers are SERVER subscriptions , which can possibly republish data , they are assigned a pool (range) so that they can use their own subscribers. Usually this pool is larger than the pool in point one because it can serve multiple subscribers. This is controlled through @pub_identity_range parameter of sp_addmergearticle
 Example: If we configure the publisher to have range from 1-1000, Subscriber 1 to have 1100-2100 and subscriber 2 to have range from 2200-3200, then merge replication should NOT insert any duplicate values at any nodes. Kindly note that Merge agent processes do NOT increase the identity values when synchronizing , they just insert the plain values, like the case when we use “set identity_insert ON”!
How the Ranges are Enforced Through the usage of constraints on the identity column. Starting with SQL server 2005, each node is assigned two ranges, primary and secondary. Both primary and secondary ranges are equal in size and once the primary range is exhausted, the secondary one is used and merge agent assigns a new range to subscriber (becoming the secondary range); this is when automatic range management is chosen when the article is added (please see @identityrangemanagementoption parameter of sp_addmergearticle). If you need more documentation, please refer to the following links:
https://blogs.msdn.com/b/suhde/archive/2010/03/21/inf-automatic-identity-range-management-with-merge-replication-in-microsoft-sql-server-2005-2008.aspx Now some hands on!
A Simple Tutorial Let us demonstrate a very simple merge replication topology with a publisher and two subscriptions. I am doing this on the same instance of my machine. The instance has to have SQL server agent to run job so STD, DEV or ENT edition is needed. Let’s create three user databases and one table under the database that will be published: [sourcecode language="sql"] Use Master GO Create database Pub; GO Create database sub1; GO Create database sub2; GO create table pub.dbo.tbl_pub (col1 int identity(1,1), col2 datetime) GO [/sourcecode] Enable distributor feature and create distribution database: [sourcecode language="sql"] use master GO Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_adddistributor @distributor = @instance, @password = N'' exec sp_adddistributiondb @database = N'distribution', @log_file_size = 2, @min_distretention = 0, @max_distretention = 72, @history_retention = 48, @security_mode = 1 exec sp_adddistpublisher @publisher = @instance , @distribution_db = N'distribution', @security_mode = 1,@trusted = N'false', @thirdparty_flag = 0, @publisher_type = N'MSSQLSERVER' GO [/sourcecode] Create publication and add article: [sourcecode language="sql"] use [Pub] exec sp_replicationdboption @dbname = N'Pub', @optname = N'merge publish', @value = N'true' GO -- Adding the merge publication use [Pub] exec sp_addmergepublication @publication = N'Pub1', @sync_mode = N'native', @retention = 14, @allow_push = N'true', @allow_pull = N'true', @allow_anonymous = N'false', @publication_compatibility_level = N'100RTM', @replicate_ddl = 1 GO exec sp_addpublication_snapshot @publication = N'Pub1', @frequency_type = 1, @frequency_interval = 0, @frequency_relative_interval = 0,@publisher_security_mode = 1 use [Pub] exec sp_addmergearticle @publication = N'Pub1', @article = N'tbl_pub', @source_owner = N'dbo', @source_object = N'tbl_pub', @type = N'table', @pre_creation_cmd = N'drop', @schema_option = 0x000000010C034FD1, @identityrangemanagementoption = N'auto', @pub_identity_range = 1000, @identity_range = 100, @threshold = 80, @destination_owner = N'dbo', @force_reinit_subscription = 1, @column_tracking = N'false', @allow_interactive_resolver = N'false' GO [/sourcecode] The important parameters here are @pub_identity_range = 1000, @identity_range = 100 @identity_range is what is allocated to the publisher and subscribers (i.e: this is the range that controls the values inserted on the publisher and subscribers as well).
Example: If we configure the publisher to have range from 1-1000, Subscriber 1 to have 1100-2100 and subscriber 2 to have range from 2200-3200, then merge replication should NOT insert any duplicate values at any nodes. Kindly note that Merge agent processes do NOT increase the identity values when synchronizing , they just insert the plain values, like the case when we use “set identity_insert ON”!
How the Ranges are Enforced Through the usage of constraints on the identity column. Starting with SQL server 2005, each node is assigned two ranges, primary and secondary. Both primary and secondary ranges are equal in size and once the primary range is exhausted, the secondary one is used and merge agent assigns a new range to subscriber (becoming the secondary range); this is when automatic range management is chosen when the article is added (please see @identityrangemanagementoption parameter of sp_addmergearticle). If you need more documentation, please refer to the following links:
https://blogs.msdn.com/b/suhde/archive/2010/03/21/inf-automatic-identity-range-management-with-merge-replication-in-microsoft-sql-server-2005-2008.aspx Now some hands on!
A Simple Tutorial Let us demonstrate a very simple merge replication topology with a publisher and two subscriptions. I am doing this on the same instance of my machine. The instance has to have SQL server agent to run job so STD, DEV or ENT edition is needed. Let’s create three user databases and one table under the database that will be published: [sourcecode language="sql"] Use Master GO Create database Pub; GO Create database sub1; GO Create database sub2; GO create table pub.dbo.tbl_pub (col1 int identity(1,1), col2 datetime) GO [/sourcecode] Enable distributor feature and create distribution database: [sourcecode language="sql"] use master GO Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_adddistributor @distributor = @instance, @password = N'' exec sp_adddistributiondb @database = N'distribution', @log_file_size = 2, @min_distretention = 0, @max_distretention = 72, @history_retention = 48, @security_mode = 1 exec sp_adddistpublisher @publisher = @instance , @distribution_db = N'distribution', @security_mode = 1,@trusted = N'false', @thirdparty_flag = 0, @publisher_type = N'MSSQLSERVER' GO [/sourcecode] Create publication and add article: [sourcecode language="sql"] use [Pub] exec sp_replicationdboption @dbname = N'Pub', @optname = N'merge publish', @value = N'true' GO -- Adding the merge publication use [Pub] exec sp_addmergepublication @publication = N'Pub1', @sync_mode = N'native', @retention = 14, @allow_push = N'true', @allow_pull = N'true', @allow_anonymous = N'false', @publication_compatibility_level = N'100RTM', @replicate_ddl = 1 GO exec sp_addpublication_snapshot @publication = N'Pub1', @frequency_type = 1, @frequency_interval = 0, @frequency_relative_interval = 0,@publisher_security_mode = 1 use [Pub] exec sp_addmergearticle @publication = N'Pub1', @article = N'tbl_pub', @source_owner = N'dbo', @source_object = N'tbl_pub', @type = N'table', @pre_creation_cmd = N'drop', @schema_option = 0x000000010C034FD1, @identityrangemanagementoption = N'auto', @pub_identity_range = 1000, @identity_range = 100, @threshold = 80, @destination_owner = N'dbo', @force_reinit_subscription = 1, @column_tracking = N'false', @allow_interactive_resolver = N'false' GO [/sourcecode] The important parameters here are @pub_identity_range = 1000, @identity_range = 100 @identity_range is what is allocated to the publisher and subscribers (i.e: this is the range that controls the values inserted on the publisher and subscribers as well).
@pub_identity_range : has a role when the subscribers also re-publish data because those republishing subscribers will synchronize data with their own subscribers and eventually will synchronize with the original publisher. It’s not a common practice but can happen , we won’t talk about it here.Let’s create the subscriptions and run the snapshot: [sourcecode language="sql"] use [Pub] exec sp_addmergesubscription @publication = N'Pub1', @subscriber = N'MYINSTANCE', @subscriber_db = N'sub1', @subscription_type = N'Push', @sync_type = N'Automatic', @subscriber_type = N'Global', @subscription_priority = 75, @use_interactive_resolver = N'False' Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_addmergepushsubscription_agent @publication = N'Pub1', @subscriber =@instance, @subscriber_db = N'sub1', @subscriber_security_mode = 1, @publisher_security_mode = 1; GO exec sp_addmergesubscription @publication = N'Pub1', @subscriber = N'MYINSTANCE', @subscriber_db = N'sub2', @subscription_type = N'Push', @sync_type = N'Automatic', @subscriber_type = N'Global', @subscription_priority = 75, @use_interactive_resolver = N'False' Declare @instance nvarchar(1000) Set @instance = @@servername; exec sp_addmergepushsubscription_agent @publication = N'Pub1', @subscriber =@instance, @subscriber_db = N'sub2', @subscriber_security_mode = 1, @publisher_security_mode = 1; GO -- Start snapshot agent Exec pub..sp_startpublication_snapshot 'pub1' GO Waitfor delay '00:00:15' GO [/sourcecode] Get snapshot agent output: Exec sp_MSenum_replication_agents @type = 1 GO
| dbname | name | status | publisher | publisher_db | publication | start_time | time | duration | comments |
| distribution | MYINSTANCE-Pub-Pub1-2 | 2 | MYINSTANCE | Pub | Pub1 | 20140118 18:05:30.750 | 20140118 18:05:40.523 | 10 | [100%] A snapshot of 1 article(s) was generated. |
| Session_id | Status | StartTime | EndTime | Duration | UploadedCommands | DownloadedCommands | ErrorMessages | PercentageDone | LastMessage |
| 3 | 2 | 1/18/2014 18:14:42 | 1/18/2014 18:14:54 | 13 | 0 | 0 | 0 | 100 | Applied the snapshot and merged 0 data change(s) (0 insert(s),0 update(s), 0 delete(s), 0 conflict(s)). |
| publication | article | subscriber | subscriber_db | range_begin | range_end | is_pub_range | next_range_begin | next_range_end |
| Pub1 | tbl_pub | MYINSTANCE | Pub | 1 | 101 | 0 | 101 | 201 |
| Pub1 | tbl_pub | MYINSTANCE | sub2 | 201 | 301 | 0 | 301 | 401 |
| Pub1 | tbl_pub | MYINSTANCE | sub1 | 401 | 501 | 0 | 501 | 601 |
| Pub1 | tbl_pub | MYINSTANCE | sub2 | 601 | 1601 | 1 | 1601 | 2601 |
| Pub1 | tbl_pub | MYINSTANCE | sub1 | 2601 | 3601 | 1 | 3601 | 4601 |
| Node | name | definition |
| Publisher | repl_identity_range_21A0E50F_D0F6_4E43_9FE1_349C1210247F | ([col1]>=(1) AND [col1](101) AND [col1]<=(201)) |
| Sub1 | repl_identity_range_21A0E50F_D0F6_4E43_9FE1_349C1210247F | ([col1]>(401) AND [col1](501) AND [col1]<=(601)) |
| Sub2 | repl_identity_range_21A0E50F_D0F6_4E43_9FE1_349C1210247F | ([col1]>(201) AND [col1](301) AND [col1]<=(401)) |
| publication | article | subscriber | subscriber_db | range_begin | range_end | is_pub_range | next_range_begin | next_range_end |
| Pub1 | tbl_pub | MYINSTANCE | Pub | 4601 | 4701 | 0 | 4701 | 4801 |
exec sys.sp_MSrefresh_publisher_idrange '[dbo].[tbl_pub]', '95208516-4B98-451D-B264-C1F27B20449A', '21A0E50F-D0F6-4E43-9FE1-349C1210247F', 2, 1Some people complained about this, but, no dice! https://connect.microsoft.com/SQLServer/feedback/details/330476/identity-range-not-working-for-merge-replication-in-sql-server-2005
Conclusion Here we learnt few points: - Merge replication can handle identity ranges automatically. - Starting with SQL 2005 , there are two range pools assigned to each publisher and subscriber. - A republishing subscriber will have a "republishing" range to use for its own subscribers. - The size of each pool can be configured. Some recommendations here as well:
- You need to choose the datatype of your identity column carefully because you do not want the subscribers to run out of range. SMALLINT, for example, allows -2^15 (-32,768) to 2^15-1 (32,767) which is quite low for any production system while BIGINT is generous here with range of -2^63 (-9,223,372,036,854,775,808) to 2^63-1 (9,223,372,036,854,775,807), it consumes more storage though.
- When adding articles , choose a range that can cover your operations without the need to frequently assign new ones. If you choose a datatype like BIGINT then you can be a bit generous as a safe factor.
- Plan the subscribers sync before the subscribers consume all range values so that new ranges are assigned. You can monitor the ranges consumption and kick off sync manually.
- On publisher , if processes inserting data are not part of a db_owner, then you will need to run agent or manually run sp_adjustpublisheridentityrange

