
Introduction When we relate file share and databases, many people will turn up their noses - but today this is a reality that we can use even in production. Microsoft spent the last years working on improvements to the Server Message Block (SMB) which is much more reliable today, than ever before. In the past, we were allowed to store data and log files into the network by activating a trace flag 1807. However, this wasn't supported because of the risks of network errors compromising database integrity, and possible performance implications that may result from the use of network file shares to store databases. But the reality has changed - from SQL Server 2012, it is possible to store user and system databases on the network thanks to the SMB improvements. Even better, this applies to both SQL Server stand-alone and SQL Server WFCI! Yes, today you can create an entire cluster based on SMB File shares. Microsoft has introduced SMB 3.0 with Windows Server 2012, which brought several significant changes to add functionality and improve SMB performance. Notice that each Windows version brings a reviewed SMB and that this is transparent for SQL Server. Here are some of the most important changes on SMB since Windows Server 2008, which proves the preoccupation with improvements to the SMB:
- Windows Server 2008 (SMB 2.0) Durability, which helps recover from temporary network glitches.
- Windows Server 2008 R2 (SMB 2.1) Significant performance improvements, specifically for SQL OLTP style workloads.
- Windows Server 2012 (SMB 3.0) Support for transparent failover of file shares providing zero downtime.
- Windows Server 2012 R2 (SMB 3.02) MTU is turned on by default, which significantly enhances performance in large sequential transfers like SQL Server data warehouse and database backup or restore.
- \\\\ServerName\\ShareName\\
- \\\\ServerName\\ShareName
- Administrative shares as \\\\servername\\x$
- Other UNC path formats like \\\\?\x:\\
- Mapped network drives.
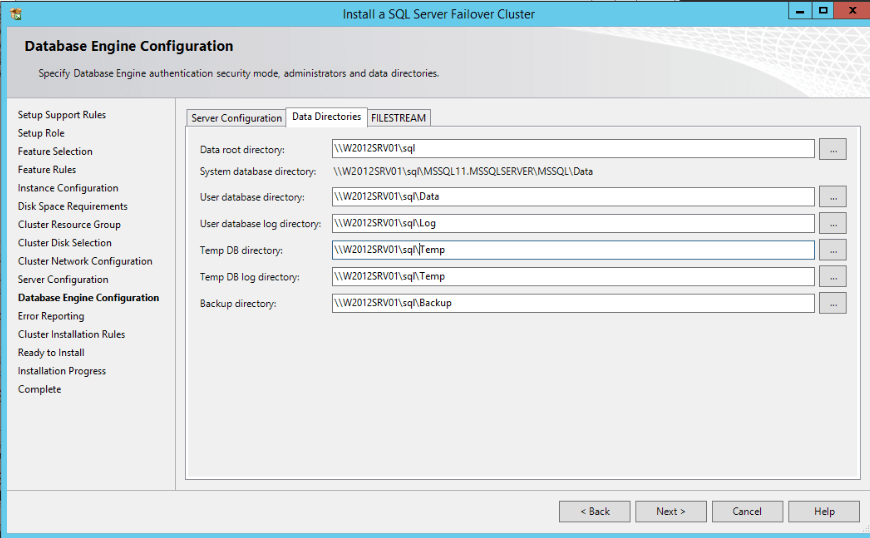
Another option is execute the "CREATE DATABASE" command pointing the data and log files to a UNC. Following is an example:
Notice that for cluster installations, the file share won't be a part of the SQL Server role, or controlled by the Cluster. So if you have any failures in the file share server, the behavior will be slightly different.CREATE DATABASE [SomeDatabase] ON PRIMARY ( name = N'networked', filename = N'\\W2012SRV01\DB\SomeDatabase.mdf', size = 3072kb, maxsize = unlimited, filegrowth = 1024kb ) log ON ( name = N'networked_log', filename = N'\\W2012SRV01\DB\SomeDatabase_log.ldf', size = 1024kb, maxsize = 2048gb, filegrowth = 10%)
go
Caution!
When we start using SMB file shares as storage option, the network performance starts to be more than critical. In a typical situation, we already have good traffic on our network. Not only client connections, but backups, our RDP connections, file transfers, etc. Based on this, consider using a dedicated and isolated network to access the share. This way we can avoid any network interference in both ways. Another word of caution is the monitoring. As we are using file shares to store our files, a different approach needs to be taken. We can use an analogy to prove it: Imagine that you have a SQL Server instance, based on a Windows virtual machine, and you receive a call from an angry client saying that the SQL Server is performing very slow. But you, as a good DBA, took all the necessary cares and the server is very well configured. You also checked the server and, in general, there is nothing wrong at first glance. But wait, this is a VM, so I'm possibly sharing the disk, CPU and memory with several other machines, with different behaviors and being used for different purposes. So, how can I know if the problem is at the VM Host level or at my single machine level? I need to have data about the VM Host performance, this way I can do a screening and understand from where the problem is coming. For exactly the same reason we need to monitor the File Share server, which can have several other file shares, used for an infinite number of purposes, and with different load characteristics. So, what is important to monitor in our case? Checking physical disk counters, Memory and the CPU load should be enough to solve problems. To finalize, what can this be used for? Before all, in a clustered environment use a SAN is the best option, as well as in a standalone server the use of a local disk is preferable. However, the use of a SMB file share to store databases could be very useful in the following circumstances:- Build low-cost clustered instances: Yes, this is an option. Today we can configure a Windows Failover Cluster based on file shares only. Attention: A failover cluster using SAN has many other advantages, so you need to think twice before deciding to use a low-cost failover cluster on production. Again, think twice!
- In non-productive or Disaster Recovery servers: For a QA that requires a cluster or a disaster recovery solution, this approach can be a very good option.
- Lightweight databases: A lightweight database is not only a small database, it can be a huge database with not many connections/operations. There are many cases, and a careful analysis should be done before take a decision for productive databases.
- Historical Data: A file share can be a cheap solution to store data files containing historical data. This kind of data have the characteristic to be read-only and not too much accessed, and a file share can cover all the need for this scenario.
- Emergency/Temporary storage: Imagine a situation that the storage is simply over, and you have a productive database stopped. Create a file (data or log) in a file share and your problem is half solved! This way the database can work while you wait for the definitive solution.
- Database migrations: This is a very particular case. If you already have a database stored in a fileshare, and you need to migrate this database to another instance, the process will be as simple as detach the database from the old instance and attach to the new one. Quicker migration ever. (of course you will need to migrate jobs and logins first :).


