Apache Kafka and Apache Flink are popular platforms for data streaming applications. However, provisioning and managing your own clusters can be challenging and incur operational overhead. Amazon Web Services (AWS) provides a fully managed, highly available version of these platforms that integrate natively with other AWS services. In this blog post we will explore the capabilities and limitations of AWS’s offering by deploying a simple data streaming application.
This is part 2 of the blog post. This time we will cover the deployment of an Apache Flink streaming application that reads simulated book purchase events from an Apache Kafka cluster and computes bookstore sales per minute. Please take a look at part 1 to get more information about the setup of the Apache Kafka cluster and the Apache Kafka Connect connector that generates the simulated book purchase events.
Apache Flink on AWS
The managed Apache Flink service is called Amazon Kinesis Data Analytics or “Amazon KDA” for short. It was first introduced in November 2018. These are some of its main features:
Fully managed and scalable
You can run your Apache Flink applications continuously without managing servers. To begin with, you author your applications locally. When you are ready to run on the cloud, you don’t need to make any changes to the code. You only need to specify the application parameters through runtime properties and the desired level of parallelism. Amazon KDA will automatically scale up or down to match the throughput of your incoming data..
AWS service integrations
You can set up and integrate a data source or destination with minimal code. The Amazon KDA libraries allow you to easily integrate with S3, Amazon MSK, Amazon DynamoDB, Amazon Kinesis Data Streams, Amazon Kinesis Data Firehose, Amazon CloudWatch, and AWS Glue Schema Registry.
Pay-per-use pricing
You pay only for what you use. In other words, you are charged an hourly rate based on the number of Amazon Kinesis Processing Units (or KPUs) used to run your application. There are no upfront costs.
Use Cases
You can use Amazon KDA for many data streaming use cases, however the four most common ones are:
Streaming ETL
Clean, enrich, organize, and transform raw data prior to loading your data lake or data warehouse in real-time.
Continuous metric generation
Aggregate streaming data into critical information to serve your applications and users in real-time. The demo app in this blog post falls into this category.
Responsive real-time analytics
Send real-time alarms when certain metrics reach predefined thresholds, or when your application detects anomalies using machine learning algorithms.
Interactive analytics of data streams
Explore streaming data in real time with ad hoc queries to inspect how data looks like within those streams.
You can find more details about the features and capabilities of Amazon KDA in the documentation.
Streaming App
The overall architecture of the demo and the structure of the simulated book purchase events is described in part 1, so here we will describe only the structure and functionality of the streaming app “kda-demo-app”. The application uses Apache Flink’s DataStream API v1.13 to read simulated book purchase events from the “purchase” topic and aggregate the data by bookstore using a tumbling window of 60 seconds. In other words, the application will aggregate the events received each minute and emit the result at the end of each minute (no overlapping, as would happen with sliding windows). Before writing the results to the “sales” topic, the application enriches the aggregated data. It looks up the bookstore details associated with the purchase event from the “bookstore” topic.
The following diagram shows the flow of events and the transformations applied by the streaming app:
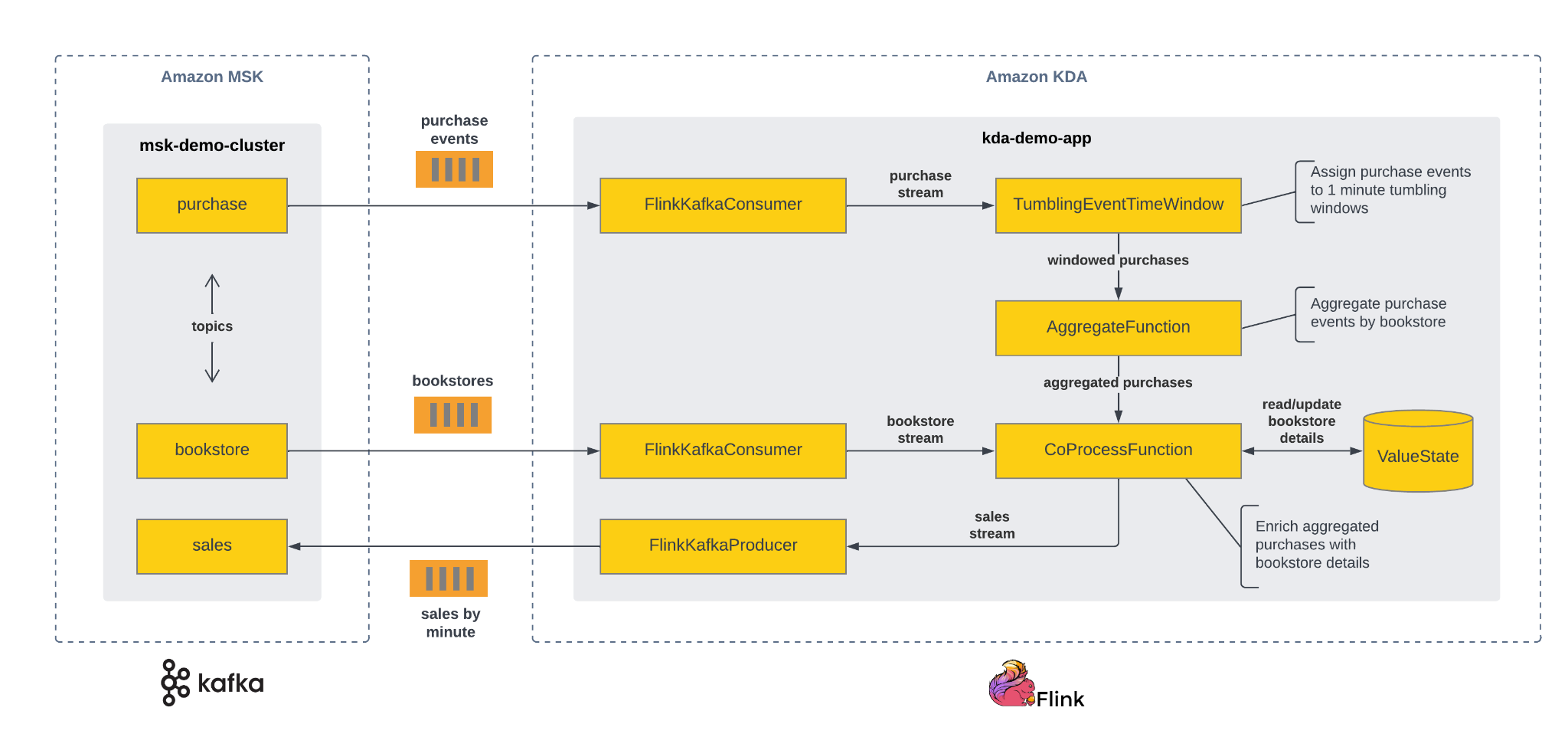
The snippet below shows an example of a sales event. The contents of “sales” come from an “AggregateFunction”, while the contents of “bookstore” come from a “CoProcessFunction”. Please note that the bookstore details are looked up from a “ValueState” store. This state store is updated on the fly as bookstore events arrive, and is part of the robust stateful processing capabilities of Apache Flink.
{
"sales": {
"bookstore_id": "6fa77aec-c327-4c67-a0c3-4b4f49cba7a4",
"books_sold": 18,
"sales_amount": 998,
"window_start": "2022-05-31 13:13:00.000",
"window_end": "2022-05-31 13:14:00.000"
},
"bookstore": {
"name": "Johnson-Donnelly",
"city": "Hirtheland",
"state": "Arizona",
"bookstore_id": "6fa77aec-c327-4c67-a0c3-4b4f49cba7a4"
}
}
Finally, the snippet below shows the body of the “StreamingJob” class. At the beginning the application determines if it is running locally or on Amazon KDA. When running locally, the application reads the parameters (bootstrap servers, group id, names of topics, etc.) from the command line. Conversely, when running on Amazon KDA, the application reads the parameters through the “KinesisAnalyticsRuntime” class. We will see later how those parameters can be configured during deployment. You can find the full code for this demo app in this repo.
public class StreamingJob {
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
ParameterTool parameters;
if (env instanceof LocalStreamEnvironment) {
// read the parameters specified from the command line
parameters = ParameterTool.fromArgs(args);
} else {
// read the parameters from the Kinesis Analytics environment
Map<String, Properties> applicationProperties = KinesisAnalyticsRuntime.getApplicationProperties();
Properties demoAppConfig = applicationProperties.get("DemoAppConfig");
if (demoAppConfig == null) {
throw new RuntimeException("Unable to load DemoAppConfig properties from the Kinesis Analytics " +
"Runtime.");
}
parameters = ParameterToolUtils.fromApplicationProperties(demoAppConfig);
}
// configuration for the consumers
Properties consumerConfig = new Properties();
consumerConfig.setProperty("bootstrap.servers", parameters.get("BootstrapServers"));
consumerConfig.setProperty("group.id", parameters.get("GroupId"));
consumerConfig.setProperty("auto.offset.reset", "earliest");
// create the bookstores stream
DataStream<Bookstore> bookstores = env.addSource(
new FlinkKafkaConsumer<Bookstore>(
parameters.get("BookstoresTopic"),
new BookstoreSchema(),
consumerConfig)
).name("bookstores");
// create the purchases stream
DataStream<Purchase> purchases = env.addSource(
new FlinkKafkaConsumer<Purchase>(
parameters.get("PurchasesTopic"),
new PurchaseSchema(),
consumerConfig)
).assignTimestampsAndWatermarks(
WatermarkStrategy.<Purchase>forMonotonousTimestamps()
.withIdleness(Duration.ofSeconds(10))
.withTimestampAssigner((purchase, timestamp) -> purchase.timestamp.getTime())
).name("purchases");
// calculate the number of books sold and the sales amount by bookstore for each window
DataStream<Sales> sales = purchases.keyBy(purchase -> purchase.bookstoreId)
.window(TumblingEventTimeWindows.of(Time.of(60, TimeUnit.SECONDS)))
.aggregate(new AggregateSales(), new CollectSales());
// enrich the aggregated totals with the bookstore info
DataStream<EnrichedSales> enrichedSales = sales.keyBy(s -> s.bookstoreId)
.connect(bookstores.keyBy(b -> b.bookstoreId))
.process(new EnrichSales());
// create a sink for the enriched bookstore sales
enrichedSales.addSink(
new FlinkKafkaProducer<EnrichedSales>(
parameters.get("BootstrapServers"),
parameters.get("SalesTopic"),
new EnrichedSalesSchema())
).name("sales");
// execute program
env.execute("kda-demo-app");
}
}
Deployment
We will not go in detail over all the steps needed to deploy an Apache Flink application on Amazon KDA. You can find detailed instructions in the Getting Started section of the documentation and in the Apache Flink on Amazon Kinesis Data Analytics workshop. Instead, we will do a quick overview of the steps we followed to deploy the “kda-demo-app”:
- Compile the application code and upload the JAR to an S3 bucket.
- Create an IAM role and IAM policy to give access to the resources required to run the application. Notably the S3 bucket, CloudWatch logs, VPC listing, ENI creation, etc.
- Create a Kinesis Data Application through the AWS console making sure to use the VPC, subnets, security groups and IAM role that will allow the application to connect to the S3 bucket mentioned above as well as the “msk-demo-cluster” deployed in part 1.
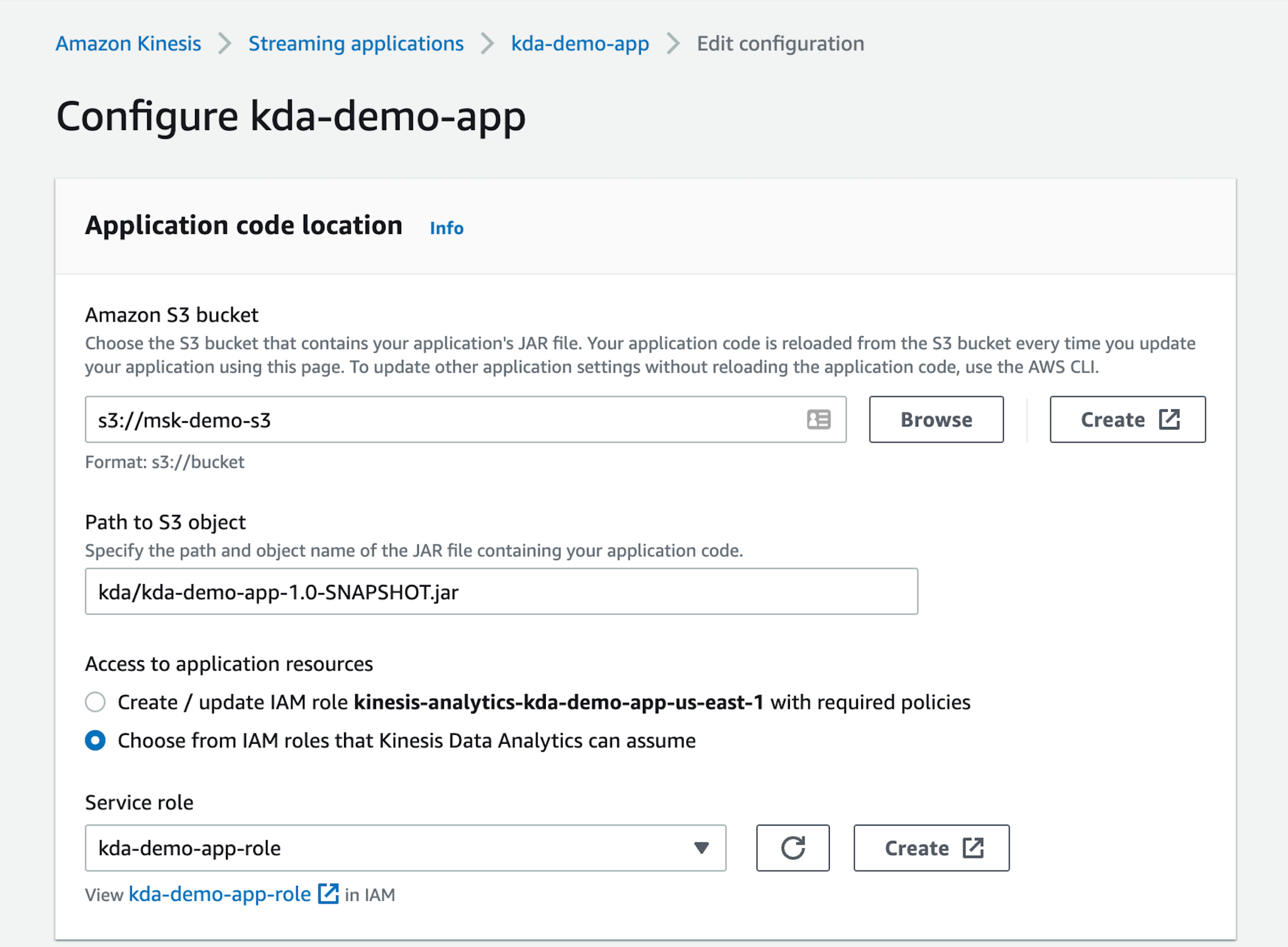
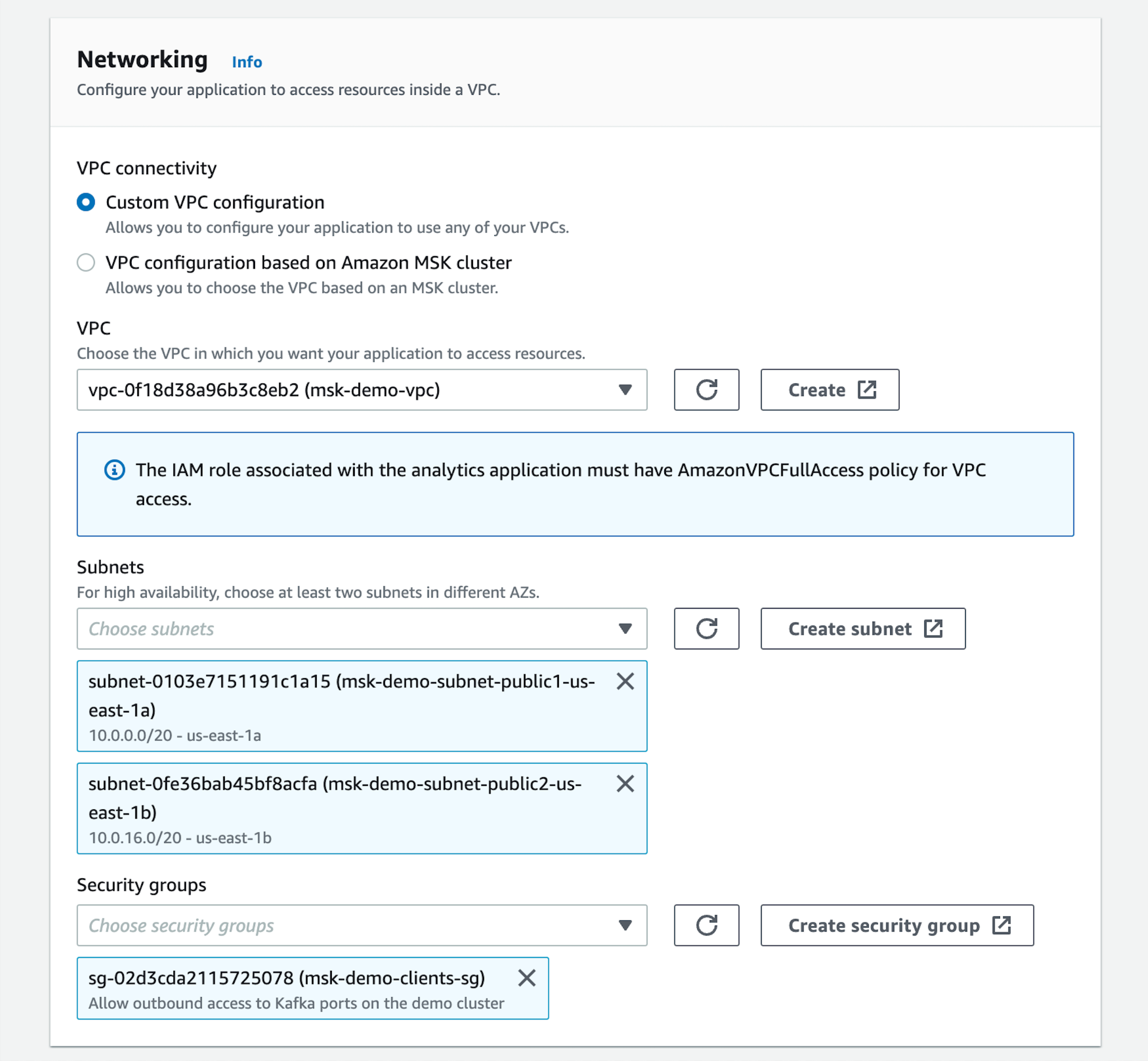
- Configure the runtime properties to specify the URL of the Apache Kafka bootstrap servers and the names of the topics. For this demo we specified a parallelism of 1 and a maximum of 1 tasks per KPU, but you can configure a higher parallelism based on the inbound traffic that you are expecting. If you enable automatic scaling, Amazon KDA will scale the parallelism to respond to spikes in throughput or processing activity.
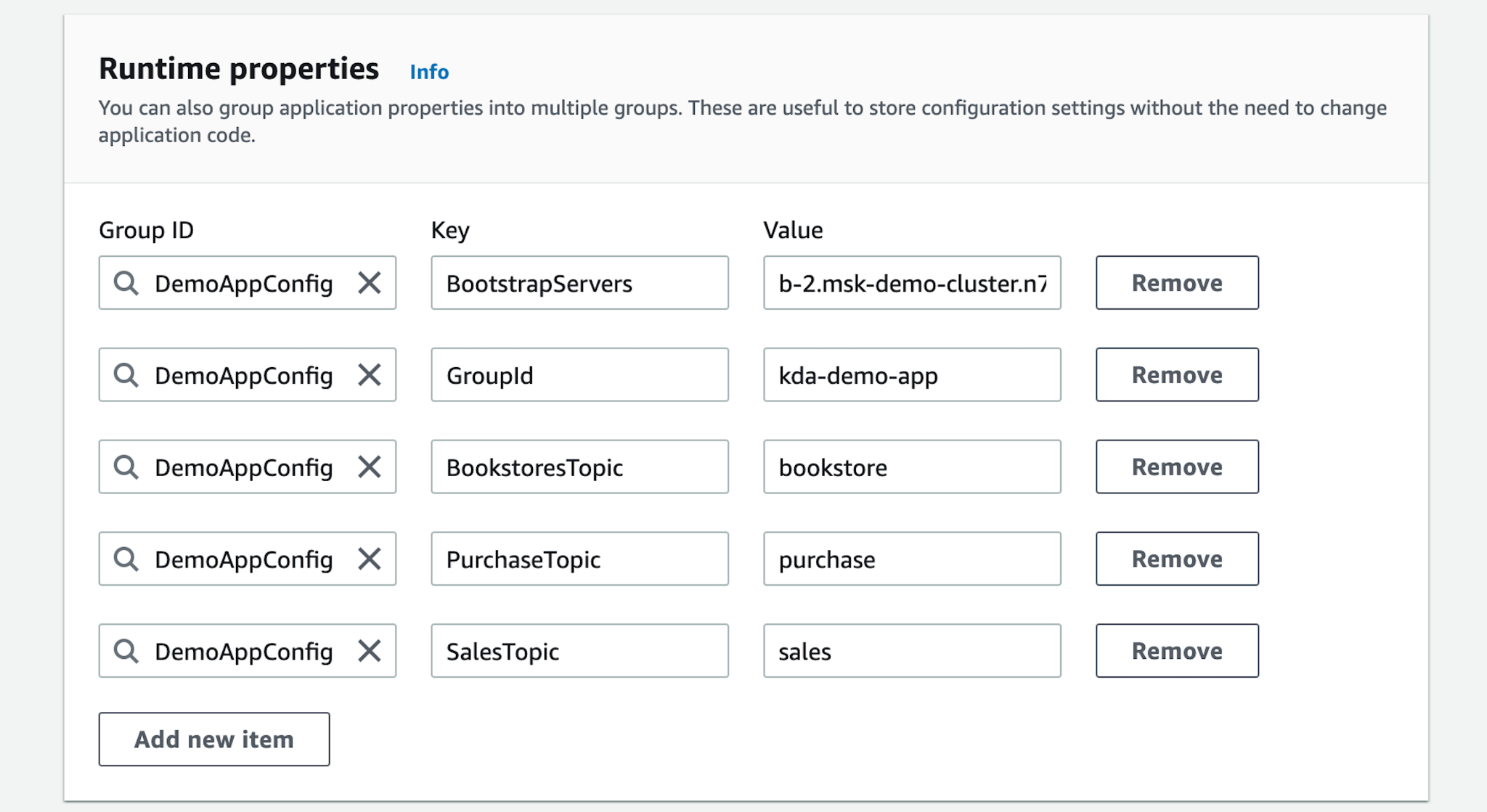
- Once the application has been created, start the application by pressing the “Run” button. Before doing that, we made sure that the “msk-demo-cluster” and the “msk-demo-datagen” were up and running so that simulated purchase events could be consumed.
Monitoring
Starting the application takes a few minutes, but once the application is up and running you have two options to monitor it and troubleshoot it. You can open the application page in the “Streaming applications” section to see the uptime metrics and consult the logs. Moreover, this page also allows you to also verify/change its configuration. Here’s a screenshot of the application page:
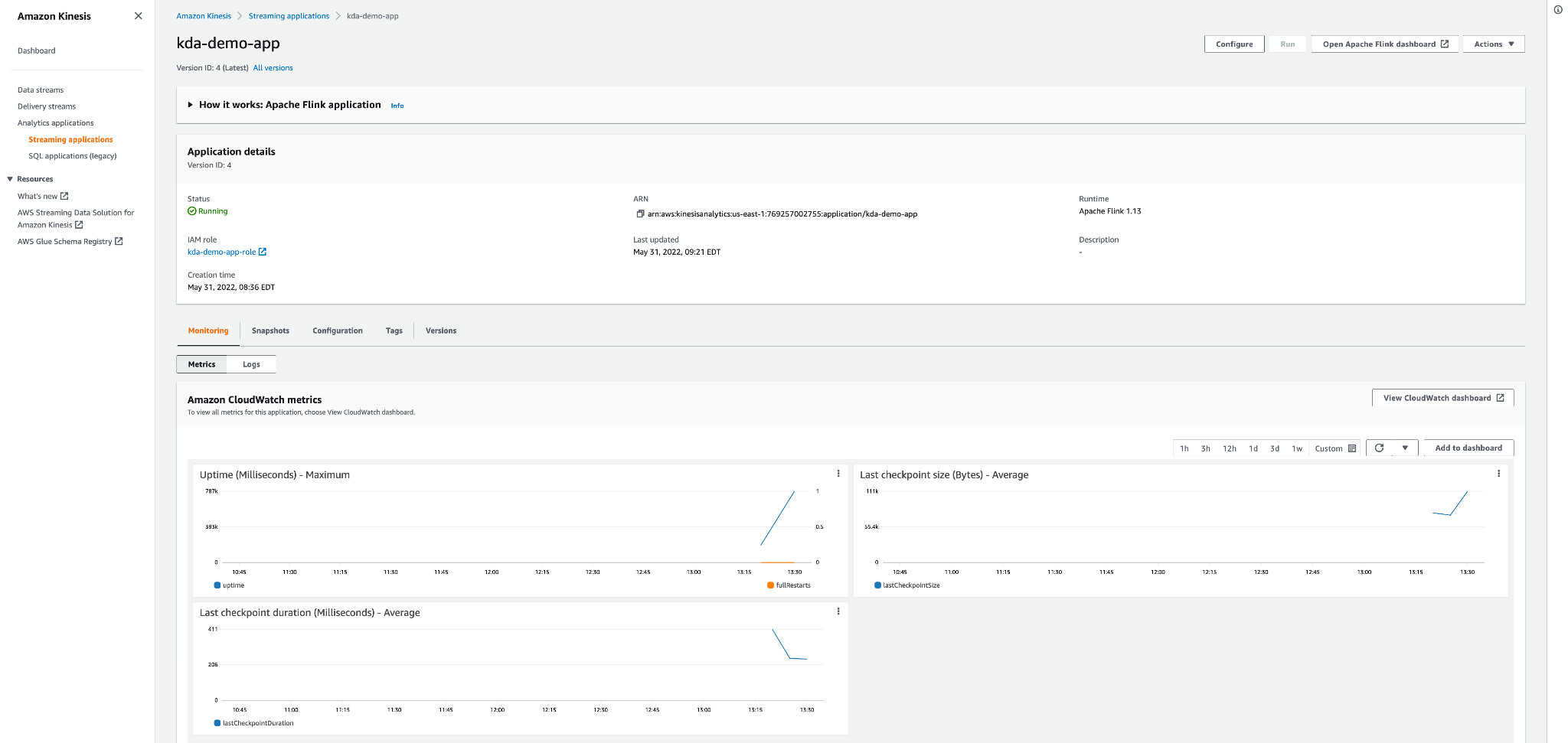
If you want to dig deeper and understand more details about the application performance, you can open the Apache Flink dashboard by clicking on the link on the top right corner of the page. In this dashboard you will find detailed information about memory usage, bytes received and sent, backpressure, watermarks, etc. Here’s a screenshot of the Apache Flink dashboard:
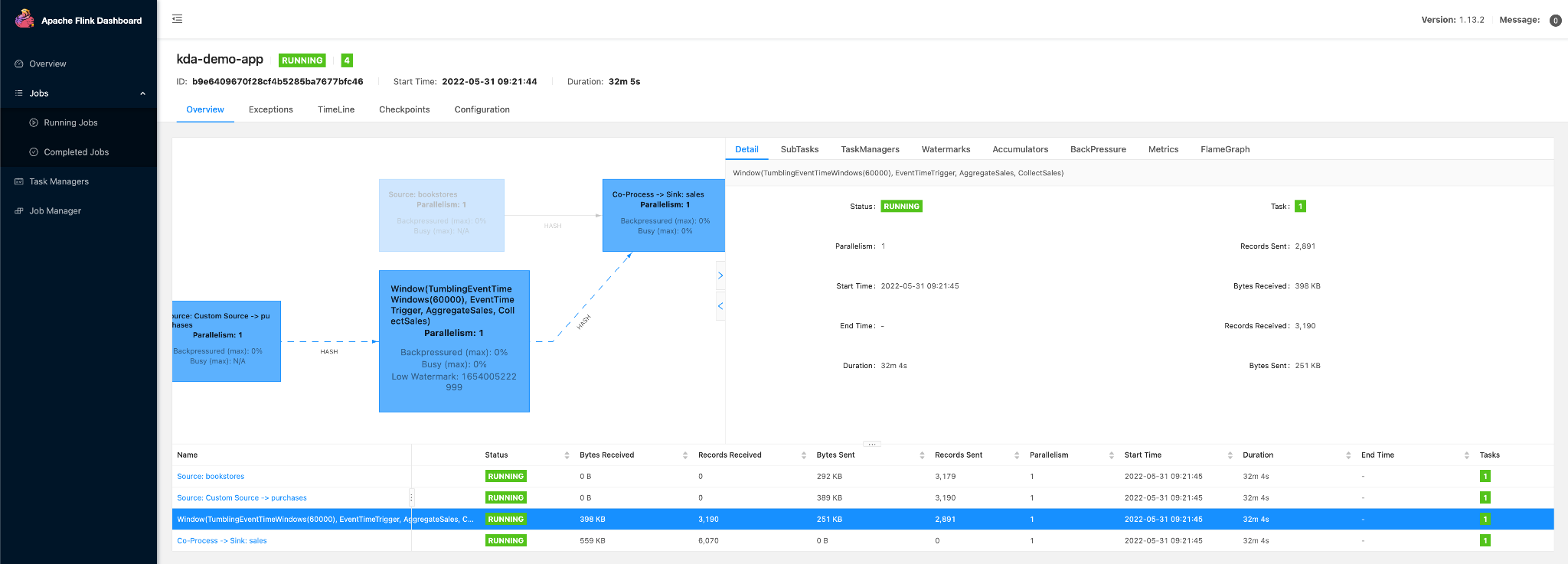
Result
After letting the application run for a few minutes we can connect to the bastion host through SSH as described in part 1 and use the kafkacat command to query the “sales” topic in the “msk-demo-cluster”. As you can see in the screenshot below, the data is aggregated per minute for each bookstore in the purchase events stream.

Conclusion
Deploying Apache Flink streaming applications on Amazon KDA is straightforward. Furthermore, you can concentrate on developing your application code instead of deploying and managing a cluster of machines to run your application in a highly-available and scalable manner. If you are already on AWS, you also benefit from the seamless integration with Amazon MSK (Apache Kafka) and several other services. These features, coupled with a pay-as-you-go pricing model, make Amazon KDA an attractive option for most streaming application use cases. Nevertheless, if your use case requires running Apache Flink on top of Kubernetes, you should consider the Ververica Platform. It is a distribution from the original creators of Apache Flink that includes features to simplify the deployment of the platform as well as auto-scaling, enterprise security and application lifecycle management. You can find instructions here about how to deploy it on AWS Elastic Kubernetes Service (EKS).
Thanks for reading. Feel free to drop any questions or share your thoughts in the comments.
Data Analytics Consulting Services
Ready to make smarter, data-driven decisions?
Share this
Share this

Data Streaming with Kafka and Flink on AWS – Part 1
Apache Beam: the Future of Data Processing?