Introduction
I’ve been working with data in many forms for my entire career. During this time, I have occasionally needed to build or query existing databases to get statistical data. Traditional databases are usually designed to query specific data from the database quickly and support transactional operations. While the capability is there to perform statistical aggregates, they are not usually very fast. Especially when you are working with databases containing hundreds of millions of rows. To support purely analytic access to a database the column store was invented. See this link in Wikipedia for more on the history: https://en.wikipedia.org/wiki/Column-oriented_DBMSWhat makes a column store?
Most traditional databases store data in the form of records. Each record contains a set of fields containing values that are related to each other. In a relational database, records are rows and fields are columns. In general, what we get is something like this table:
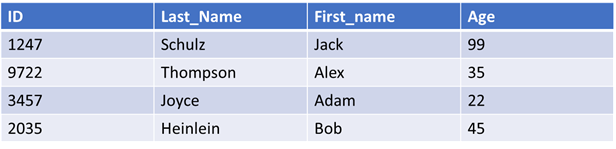
This approach works well when you are looking for some or most of the information in a record or row. It is not optimal when you are looking to compute statistics on a specific column. If I wanted to compute the average age in the table above I would have to read into memory and pass over all the ID and name information to get the age information which itself could easily be stored in a single byte for each record. What a column store does is defined in its name. Instead of storing data in rows or records the data is stored in columns. That way, when you want to compute the average age you only have to read the data with age information into memory instead of all the data in each row. The stored data ends up looking something like this:
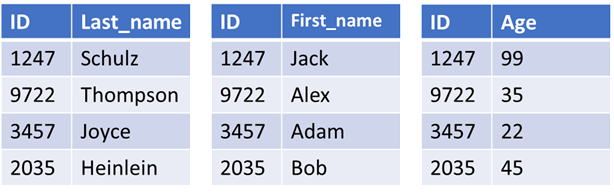
Column stores are lousy for transactional operations or selecting the contents of a specific row or record, but they can be awesome at producing statistics on a specific column in a table. If you are going to store data in columns rather than rows the cost of doing single inserts is very high and the number of raw bytes is much larger than what you would normally store. As a result, most column stores are traditionally loaded in batches that can optimize the column store process and the data is pretty much always compressed on disk to overcome the increased amount of data to be stored. In addition to compression most modern column stores store column data in blocks with several precomputed statistics which will make queries run much faster allowing computation by accessing much less data. An example of how significant the differences in performance column stores can provide, I was working with a customer last year with a database containing twenty million records related to purchasing information. Using MySQL MyISAM a typical query they would make against the purchase order table would take 30-40 minutes. Those same queries using MariaDB AX (a column store variant of MySQL) took between 0.1 seconds and 8 seconds. This is the kind of technology that makes Business Intelligence a real time endeavor.
The two kinds of column stores
It turns out that there are really two very different kinds of database that can be referred to as a column store. Cassandra and HBase store each column separately for reasons very different from other column stores. As a result the performance is also very different. The HBase and Cassandra column store concept does not enable rapid analytics. Instead they store individual columns clumped together to support their sparse table (big table) model and fast writes. When you hear or read references to these kinds of databases as column stores remember they aren’t going to give you the same kind of performance analytics. Since both Hbase and Cassandra are so very poor at doing analytics, they don't support much in the way of built in aggregates at all.Some examples of specific open source column stores
While there are many examples of proprietary column stores since I am deeply engaged in the open source world my examples come primarily from the open source world.MariaDB AX
MariaDB AX is a relative newcomer to the column store world although the source code they are using has been around for quite a while. The MariaDB corporation adopted the codebase from Infinidb: https://en.wikipedia.org/wiki/InfiniDB MariaDB AX uses the storage engine interface to allow users to use the MySQL SQL dialect against the distributed column store. One of the nice features of using MariaDB AX is you can also create tables using the Transactional InnoDB storage engine and mix both transactional and analytic workloads on the same database. Although you won’t be doing them on the same tables.
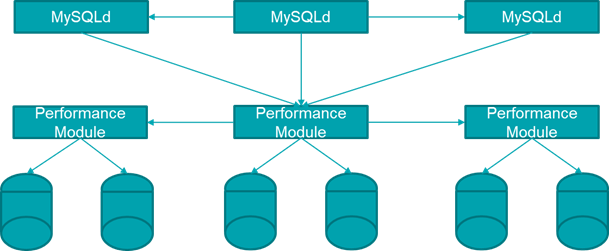
For more information on MariaDB AX see: https://mariadb.com/products/solutions/olap-database-ax
Parquet
Parquet isn’t a database. Instead it’s a file format which can be used to store database tables on distributed file systems like HDFS, CEPH or AWS S3. Data is stored in Parquet in chunks that contain blocks of column data in a fashion that makes it possible to break up a Parquet file. Storing the file on many distributed hosts while allowing it to be processed in parallel. You can access Parquet files using Apache Spark, Hive, Pig, Apache Drill and Cloudera’s Impala. For more information on Parquet: https://parquet.apache.org/documentation/latest/Clickhouse
Clickhouse was created by the Russian company Yandix to support their own internal requirements to provide analytics to their customers. Unlike MariaDB AX or Parquet it has its own dialect of SQL and its own APIs. Nevertheless, it is rapidly becoming very popular because it is very fast. For more information on Clickhouse: https://en.wikipedia.org/wiki/ClickHouseCitus Data
The Citus Data corporation builds extensions to PostgreSQL. One, which they are best known for, is a distributed cluster extension that turns PostgreSQL into a distributed cluster database. The other is a Hybrid column store feature which allows you to choose to make some tables within your PostgreSQL database column oriented while allowing you to keep others in the older transaction friendly model. For more information on Citus Data the company: https://www.citusdata.com/download/ For more information on the Citus Data Column store: https://www.citusdata.com/blog/2014/04/03/columnar-store-for-analytics/Greenplum
Greenplum has been in the data warehouse and business intelligence business for quite a while. Their product like Citus Data is based on PostgreSQL. Albeit a much older version of PostgreSQL. They offer both a proprietary version and an open source community version of their product. For more information on Greenplum see: https://en.wikipedia.org/wiki/GreenplumAll the rest
The ones I have listed here are the ones I have dealt with in the last couple of years. There are a bunch of database technologies in the column store category I have not mentioned here but you can find out about them here: https://en.wikipedia.org/wiki/List_of_column-oriented_DBMSesConclusion
Column store databases store data in columns instead of rows. They make it possible to compute statistics on those columns one to two orders of magnitude or more, faster than on traditional row-oriented databases. A column-oriented table is very good for analytics but usually terrible for traditional transactional workloads. Most, although not all, column stores are designed to operated on a distributed cluster of servers.
Data Analytics Consulting Services
Ready to make smarter, data-driven decisions?
Share this
Share this

Getting started with the OCI PostgreSQL service

How to Set Up REPMGR with WITNESS for PostgreSQL 10