Introduction
Both Apache Spark and Beam are distributed programming languages. Apache Spark was initially open-sourced in 2010 and was initially released on May 26, 2014. Apache Beam was released on June 15, 2016. Both Apache Spark analytics engine and Apache Beam unified programming model have undergone—and are still undergoing—significant development phases to meet and satisfy the industry's needs.

Using the analogy of comparing a juice jar blade with a mixer. A blade/knife can chop the ingredients, and the mixer is the wrapper/helper that can run multiple types of jars to serve the purpose. Also, a comparison between a mixer and a knife is something like comparing apples to oranges, which are of different kinds. Similarly, Comparing Apache Beam with Apache Spark is something like comparing two different things.
Comparing Apache Beam and Apache Spark

Apache Beam and Apache Spark are powerful big data processing frameworks with different design goals and use cases.
Apache Beam
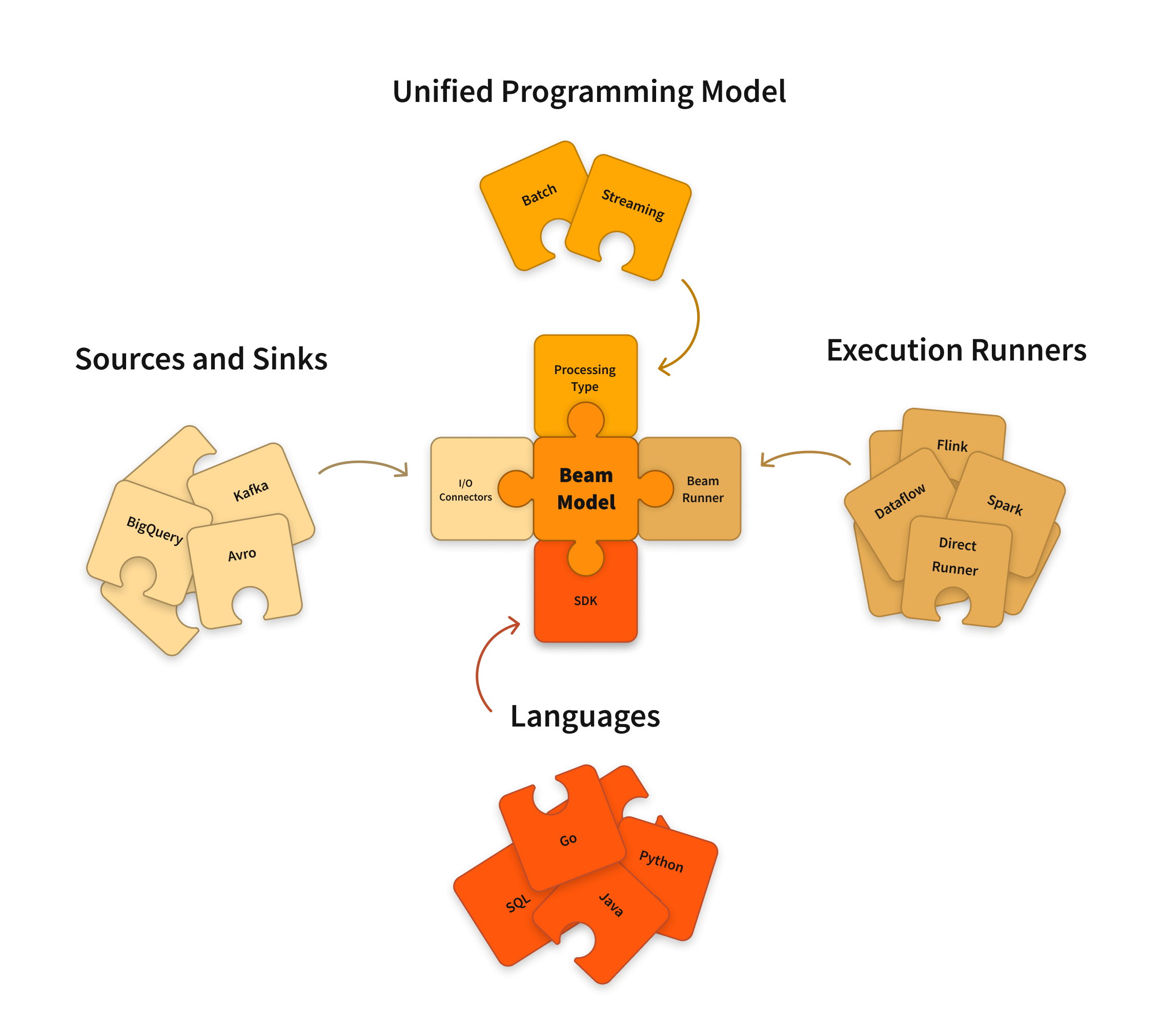
Apache BEAM(Batch + strEAM) is a unified portable programming model for both batch and streaming execution, allowing developers to write a single pipeline for both use cases that can then execute against multiple execution engines, Apache Spark being one. You can program a batch or a streaming program in Python, Java, Go (or others) and then execute that program on Several Runners like Apache Apex, Apache Flink, Apache Spark, Apache Samza, Apache Gearpump, or Google Cloud Dataflow. So, Apache Beam serves a different purpose, and it attempts to generalize the execution capabilities so that your program is portable across them.

Hence, Apache Beam's key strength lies in its portability across different execution engines. It enables you to write your data processing logic once and run it on different platforms without major modifications. Because the same pipeline can be executed on multiple processing engines, developers can choose the processing engine that best fits their needs without having to rewrite their pipeline code. In addition, Apache Beam provides a set of standard APIs and SDKs that can be used across different languages, making it easier to write portable and maintainable code.
The code snippet for basic WordCount implementation using Beam is as follows:
static class ExtractWordsFn extends DoFn<String, String> {
private final Counter emptyLines = Metrics.counter(ExtractWordsFn.class, "emptyLines");
private final Distribution lineLenDist =
Metrics.distribution(ExtractWordsFn.class, "lineLenDistro");
@ProcessElement
public void processElement(@Element String element, OutputReceiver<String> receiver) {
lineLenDist.update(element.length());
if (element.trim().isEmpty()) {
emptyLines.inc();
}
String[] words = element.split(ExampleUtils.TOKENIZER_PATTERN, -1);
for (String word : words) {
if (!word.isEmpty()) {
receiver.output(word); }
}
}
}
public static class CountWords
extends PTransform<PCollection<String>, PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> expand(PCollection<String> lines) {
PCollection<String> words = lines.apply(ParDo.of(new ExtractWordsFn()));
PCollection<KV<String, Long>> wordCounts = words.apply(Count.perElement());
return wordCounts;
}
}
static void runWordCount(WordCountOptions options) {
Pipeline p = Pipeline.create(options);
p.apply("ReadLines", TextIO.read().from(options.getInputFile()))
.apply(new CountWords())
.apply("WriteCounts", TextIO.write().to(options.getOutput()));
p.run().waitUntilFinish();
}
public static void main(String[] args) {
WordCountOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(WordCountOptions.class);
runWordCount(options); }
Apache Spark
On the other hand, Apache Spark is a full-fledged data processing engine that provides a rich set of libraries and APIs for processing large-scale data. Spark supports batch processing, real-time stream processing, machine learning, and graph processing. It includes a powerful distributed computing engine, a resilient distributed dataset (RDD) abstraction, and a wide range of built-in libraries for data manipulation and analysis.
Apache Spark provides very specific programming and execution functions alone, as do all of the execution engines. Apache Spark is a fast and general-purpose cluster computing system for big data processing. It is designed for iterative, in-memory computations and has built-in support for SQL, streaming, and machine learning.
One of the key benefits of Apache Spark is its performance. Spark provides efficient in-memory caching and optimized data processing algorithms, which can make it faster than other processing engines for certain workloads. It also has a large and active community, which has contributed to developing many useful libraries and tools for Spark.
The code snippet for basic WordCount implementation using Spark is as follows:
SparkSession spark = SparkSession
.builder()
.appName("JavaWordCount")
.getOrCreate();
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
}
Beam vs. Spark
Please take a high-level glimpse of the code snippet for basic WordCount implementation in both Beam and Spark.

It can be understood that Beam is more granular, lengthier, and contains boilerplate code when compared with Spark, and the reason behind that is Spark API was designed for the Spark engine alone. It is dependent and also specific to the Spark Run time environment. Hence, the Spark API is optimized, matured, and evolved to meet user requirements by reducing boilerplate code.
On the other hand, Beam is based on so-called abstract pipelines and can run on any engine like Spark, Flink, and Dataflow, and this is achieved by decoupling most of the API implementations of Spark into interfaces. The Beam user has to provide the respective functional implementation of each interface. There comes the overhead of implementing the basic, most common, and redundant implementation of interfaces by Beam users.
This overhead of boilerplate code in Beam is still accepted and can be ignored when we have other requirements like capturing metrics, portability, and Batch + Stream processing by single code.
Below are a few more differences/comparisons between Beam and Spark:
| Apache Beam | Apache Spark |
Use Beam when:
|
Use Spark when:
|
|
Apache Beam provides a unified programming model that can be executed on various execution engines, including Apache Spark, Apache Flink, and Google Cloud Dataflow. It offers portability across different platforms and flexibility in choosing the execution environment. |
Spark can run on Spark Engine alone(Spark core). |
|
Apache Beam supports both batch and streaming data processing. It provides a unified API for processing both bounded (batch) and unbounded (streaming) data. |
Although Spark supports both batch and streaming data, Spark has a different API (different context altogether) for batch and streaming data processing applications. |
|
Apache Beam integrates well with other data processing and analytics tools, such as Apache Kafka, Apache Hadoop, and Apache Cassandra. It enables easy integration into existing data pipelines and workflows. |
Spark itself is a mature and extensive ecosystem with support for various data sources, machine learning libraries (Spark MLlib), graph processing (GraphX), and SQL queries (Spark SQL). It offers a broad range of functionalities beyond just data processing, making it suitable for complex analytics workflows. |
|
Beam is suitable in environments where portability is needed. |
Spark best fits in environments where processing is highly important, including heavy computational and analytical workloads. |
|
Apache Beam is classified as a tool in the Workflow Manager category. |
Apache Spark is an open-source, distributed processing system used for big data workloads. |
|
Capture metrics in Beam code, which are available for other downstream applications to consume |
Metrics are captured by the Scheduler like Yarn and available in Spark UI. |
Can Apache Beam replace Apache Spark?
While Apache Beam can leverage Apache Spark as one of its execution engines, it only provides some of the advanced features and libraries that Apache Spark offers. Apache Spark has a larger ecosystem, mature machine learning libraries (such as MLlib), and better integration with other big data tools like Apache Hadoop.
Apache Beam provides a flexible and portable programming model for building data processing pipelines that can be executed on multiple processing engines. Apache Spark, on the other hand, is optimized for fast and general-purpose cluster computing and provides built-in support for SQL, streaming, and machine learning. Both frameworks have their strengths and can be used to build efficient and powerful big data pipelines.
In summary, if you are looking for a flexible, portable, and unified programming model that can run on different execution engines, Apache Beam is a good choice. However, Apache Spark would be more suitable if you require a comprehensive data processing and analytics platform with a broader range of features and libraries. The choice between the two depends on your specific requirements and the ecosystem you are working with.
References:
Data Analytics Consulting Services
Ready to make smarter, data-driven decisions?
Share this
Share this