MySQL Cluster is a highly available, distributed, shared-nothing database with
very interesting performance characteristics for
some workloads. Among other features, it supports automatic sharding and allows us to bypass the SQL layer if we don't need it, via the
NDB API (which in my eyes, makes it one of the few transactional nosql databases out there). In this post, I'll describe how we can set up replication from MySQL Cluster into a standalone MySQL server using Innodb as the storage engine.
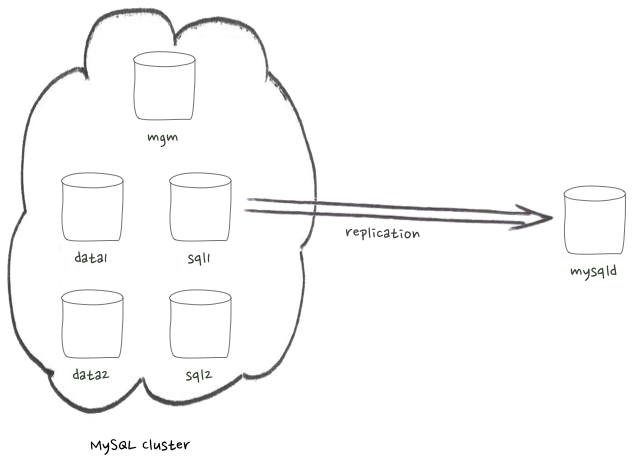 If you'd like to set up MySQL Cluster to try the commands shown in this post, but don't have much experience with it, I recommend using the
auto installer, or
this vagrant environment. The latter offers something very close to what's on the NDB side of that diagram, but with two management processes; each living in an sql node (so, 4 VMs in total).
If you'd like to set up MySQL Cluster to try the commands shown in this post, but don't have much experience with it, I recommend using the
auto installer, or
this vagrant environment. The latter offers something very close to what's on the NDB side of that diagram, but with two management processes; each living in an sql node (so, 4 VMs in total).
Introduction
There are a few reasons to set up replication between MySQL Cluster and a non-NDB based MySQL server. These reasons include (but are not limited to): the need to use other storage engines for various parts of the workload, improved availability courtesy of geographical distribution, or (based on my recent experience), migrating away from MySQL Cluster to MySQL (Galera Cluster in my case, but the procedure is the same). While the manual provides a lot of information on NDB asynchronous replication, it assumes the desired setup involves running NDB on both ends of the link. In the next few paragraphs, I'll describe the lab environment I used for my tests, go through the required configuration changes both on MySQL/NDB and MySQL/Innodb's side, and then outline the steps required to get replication working.Test environment
My test environment consists of a MySQL Cluster with 2 data nodes, 2 sql nodes and one management node, and a standalone MySQL server, as described by this diagram: If you'd like to set up MySQL Cluster to try the commands shown in this post, but don't have much experience with it, I recommend using the
auto installer, or
this vagrant environment. The latter offers something very close to what's on the NDB side of that diagram, but with two management processes; each living in an sql node (so, 4 VMs in total).
MySQL Cluster required configuration
MySQL Cluster uses its own synchronous replication system, independent of MySQL's asynchronous one. This is implemented at the storage engine level, so MySQL is unaware of it. Among other things, this means that the usual configuration options used by MySQL replication are not required for MySQL Cluster to work. On a MySQL Cluster, the sql nodes are normal mysqld processes that use the ndb storage engine to connect to ndb processes living (hopefully if it's production) on other hosts. Before we can set up a standalone mysqld as a replica of MySQL Cluster, we need to choose one sql node that will act as master, and set it up for replication, by adding the following to its global my.cnf file's [mysqld] section:binlog_format=ROW log-bin=binlog server_id=168150As with any normal replication setup, server_id can be any valid value for that range, provided it is unique across the topology. In my situation, I chose sql1 for this task. The server id reflects part of its IP address, since it is typically unique across a replication topology (often because on a multi-DC setup you may have the same private network on different DCs. I try not to do that). This is a change that requires a mysqld service restart on the affected sql node. Since this is MySQL Cluster, we can make the restart with no impact by simply removing this node from rotation. Additionally, we will need to create a replication user, which we can do by executing the following statements:
CREATE USER 'replica'@'10.0.2.15' IDENTIFIED BY 'examplepassword'; GRANT REPLICATION SLAVE ON *.* TO 'replica'@'10.0.2.15';
MySQL required configuration
The standalone mysqld instance also needs to be configured for replication, by adding the following to its global my.cnf's file [mysqld] section:server_id=100215 log-bin=binlog binlog_format=ROWMySQL also needs to be restarted here for this change to take effect.
Getting data out of MySQL Cluster
We will create a logical backup of the data with mysqldump: mysqldump --master-data=1 example > example.sql The
--master-data option set to 1 will include a CHANGE MASTER TO command on the resulting dump, so that we can START SLAVE when the load completes, and start replicating off the server where we generated the dump (sql1 in this case). I am including the database name explicitly, instead of using
--all-databases, to not get the mysql schema in the backup. You can backup multiple databases by using
--databases if needed. Additionally, I am not using
--single-transaction because NDB only supports the READ COMMITTED isolation level, and only on a per-row level, so this mysqldump option is not really supported for MySQL Cluster.
Getting data into MySQL
We will now load the logical backup into MySQL: mysql -e 'change master to master_host="192.168.1.50";create database example' mysql < example.sql example Besides loading the data, this will also run a CHANGE MASTER to command and set the right replication coordinates, thanks to the --master-data file. For example, here is the command generated in my test backup:
CHANGE MASTER TO MASTER_LOG_FILE='binlog.000001', MASTER_LOG_POS=154; Since it does not include a host specification, the previously set master_host will be used, which is the one we set with the 'change master to' command we ran right before creating the database and loading the data.
A Short Detour: How Does This Work?
A few readers will likely have noticed that, on MySQL Cluster's side, we enabled binary logging on sql1. What then happens to writes made on sql2? To understand what happens, we must remember that NDB handles its own replication, on a separate layer (and actually separate system processes) from MySQL's. In order to get NDB writes into the binary log, regardless of the originating node, MySQL Cluster uses the following auxiliary tables on the mysql schema: ndb_apply_status and ndb_binlog_index. On my installation using MySQL Community 5.7.17 as target version, only the ndb_binlog_index was present, so I had to manually create the ndb_apply_status table. The manual recommends verifying that the tables exist as a prerequisite to setting up asynchronous replication in MySQL Cluster. To create it, I took the structure from sql1, and then ran the following on the target host: mysql> use mysql Database changed mysql> CREATE TABLE `ndb_apply_status` ( -> `server_id` int(10) unsigned NOT NULL, -> `epoch` bigint(20) unsigned NOT NULL, -> `log_name` varchar(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL, -> `start_pos` bigint(20) unsigned NOT NULL, -> `end_pos` bigint(20) unsigned NOT NULL, -> PRIMARY KEY (`server_id`) USING HASH -> ); Query OK, 0 rows affected (0.02 sec) The 'USING HASH' will be ignored by Innodb, but it won't hurt (a usual btree index will be created instead). Now we're finally ready to start replication:
start slave user='replica' password='examplepassword'; We can now check and see that it is running:
mysql> pager egrep -i running PAGER set to 'egrep -i running' mysql> show slave status\G Slave_IO_Running: Yes Slave_SQL_Running: Yes Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates 1 row in set (0.00 sec)We can also verify that everything thing works as expected, we can insert into MySQL Cluster using sql2, which does not have binary logging enabled, and we'll still have the write propagated to the MySQL slave which is replicating off sql1:
[vagrant@sql2 ~]$ mysql -e 'select max(id) from example.t' +---------+ | max(id) | +---------+ | 9 | +---------+ [vagrant@sql2 ~]$ mysql -e 'select max(id) from example.t' +---------+ | max(id) | +---------+ | 9 | +---------+ [vagrant@sql2 ~]$ mysql -e 'insert into example.t values (null)' [vagrant@sql2 ~]$ mysql -e 'select max(id) from example.t' +---------+ | max(id) | +---------+ | 10 | +---------+ [root@mysql57 ~]# mysql -e 'select max(id) from example.t' +---------+ | max(id) | +---------+ | 10 | +---------+And we can see we have a working asynchronous replication channel from MySQL Cluster into MySQL.

