On this page
Share this
Share this
Cassandra as a time series database
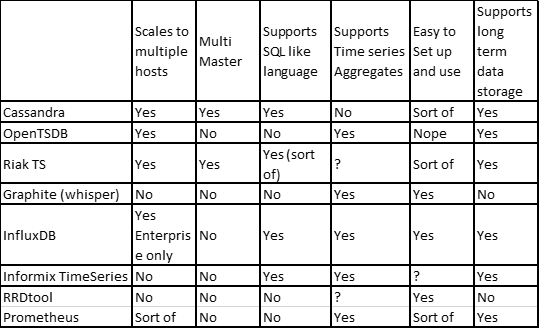
Cassandra as a time series database
Mar 23, 2018 12:00:00 AM
6
min read
MariaDB Temporal Tables: Uncut & Uncensored (Part I)
![]()
MariaDB Temporal Tables: Uncut & Uncensored (Part I)
Dec 2, 2019 12:00:00 AM
4
min read
Exposing MyRocks Internals Via System Variables: Part 3, Compaction
![]()
Exposing MyRocks Internals Via System Variables: Part 3, Compaction
May 7, 2019 12:00:00 AM
19
min read