In the modern era of data-driven decision-making, businesses rely heavily on robust and efficient data platforms to process, analyze, and derive insights from their vast amounts of data. Since 2019, Azure Synapse Analytics has been Microsoft’s main contender in this space, offering powerful capabilities to handle complex data workloads. Now, Microsoft has announced a new data platform called Microsoft Fabric, an evolution of the data platform built with a modified philosophy. It is a similar product but with enough differences to make them not interchangeable and so it’s very important to understand how they both compare and contrast if you’re planning a new data platform deployment. Microsoft wanted a product that was even simpler to deploy and operate and could function well outside of an Azure cloud environment as a full standalone Software As a Service offering. In this blog post, we'll compare Synapse Analytics and Fabric, highlighting their features, strengths, and considerations to help you make an informed decision for your organization's data needs.
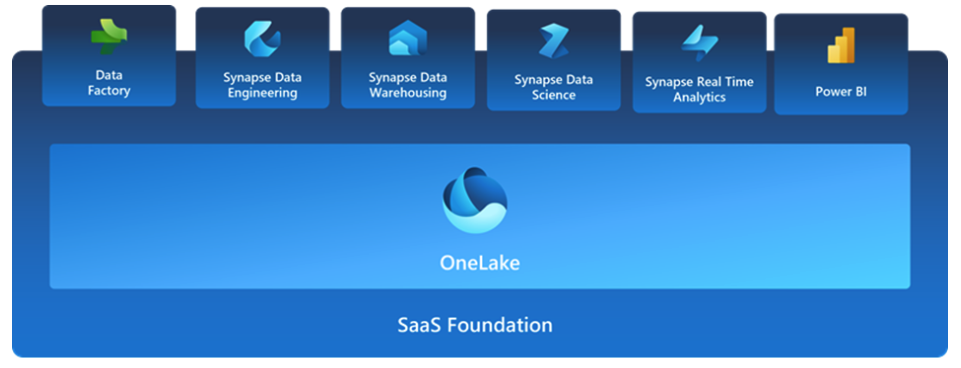
Architecture and Integration
Synapse Analytics: Azure Synapse Analytics, formerly known as SQL Data Warehouse, is tightly integrated with the Azure ecosystem. It seamlessly connects with various Azure services such as Azure Data Lake Storage, Azure Machine Learning, and Power BI. Its architecture combines data warehousing and big data analytics, providing a unified environment for processing both structured and unstructured data. As a direct descendant of SQL Data Warehouse, Synapse uses the SQL Server based MPP engine that still uses SQL Server native storage and its underlying architecture (60 underlying data distributions for example). This is known as a “Dedicated SQL Pool” in Synapse terms. Synapse uses Azure Data Lake Storage Gen 2 (ADLSG2) as its underlying storage for general storage and data lake workloads. You have direct access to this storage account in your Azure tenant and permissions need to match for a user to be able to modify this data.
Fabric: Fabric follows a new storage architecture that decouples storage and computation further than Synapse SQL Pools. It introduces a new fully managed storage layer called OneLake that Microsoft has built on top of Azure Data Lake Storage Gen2 and abstracts away all the underlying infrastructure security so that the end user just needs to manage permissions to Fabric resources and not have to worry about the permissions at the storage layer. It also breaks down the computation resources into serverless endpoints, each endpoint pointing to a different “Warehouse” or “Lakehouse”. This separation allows for efficient scaling, isolation of workloads and sharing of capacity. As expected Fabric can be integrated with the rest of Azure but it can be used completely stand-alone and it is definitely more integrated with Power BI than Synapse is. In fact, Fabric can in fact be used without having an Azure environment at all, the biggest integration difference with Synapse. So if you are looking for a puzzle piece in a larger Azure architecture, Synapse will fit better and offer more control for the administrator whereas Fabric is more of a SaaS solution with a bigger sandbox feel and even more management already done for you.
Storage Format
Synapse Analytics: As mentioned above, Synapse uses SQL Server native storage for its main warehousing engine (the Dedicated SQL Pool). This is a proprietary Microsoft format and you don’t have direct access to this underlying storage. If you want access to this storage your Dedicated SQL Pool needs to be running. The underlying ADLSG2 can be used to export data from the SQL engine into parquet files but Delta support is uneven.
Fabric: In a large departure from Synapse, Fabric does not use the SQL Server proprietary format at all and instead uses the open source Delta Lake parquet format. Created by Databricks, the Delta Lake file format offers features that are not available in the native parquet format. This includes ACID transactions, time-travel, cloning and more. So regardless of whether you are using the “Warehouse” endpoint and engine or the “Lakehouse” one, all the underlying table storage will be saved as Delta. Fabric then allows you to query the data that is from the “Warehouse” from the “Lakehouse” without having to have any dedicated engine resources running.
Data Sharing
Synapse Analytics: Synapse supports easy sharing to collaborators of the same Synapse workspace. Trying to share to anyone outside of that boundary however is more painful and requires either giving access to the underlying ADLSG2 or you need to export data out of your Dedicated SQL Pool storage. So if you are using the main SQL MPP engine, there is no way to do sharing with a no-copy mechanism.
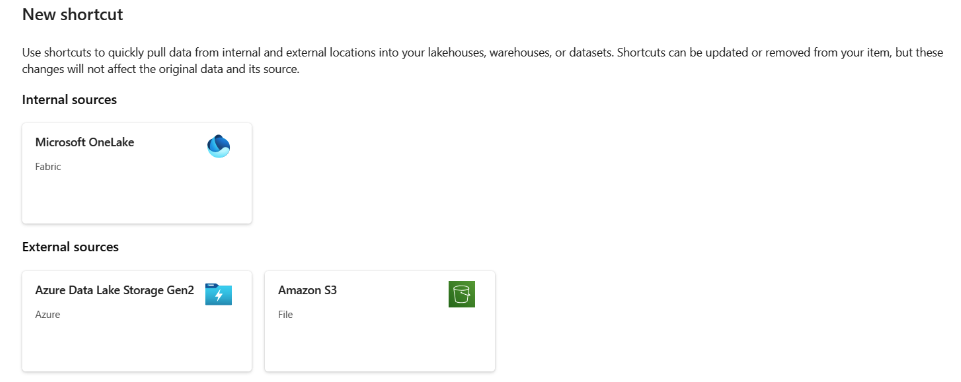
Fabric: Fabric introduces the concept of data “shortcuts”. The shortcuts point to datasets and can be shared and consumed from either the same or other trusted Fabric tenants. This is a big difference from the Synapse story and makes data sharing a lot more transparent. Once the shortcut has been imported then it can be consumed just like any other dataset that is inside your Fabric environment. The initial user pays for the storage of the dataset and the consuming user pays for the computation power to work with it. Shortcuts can also be created to other external sources like other ADLSG2 accounts or even Amazon S3 buckets. We expect the capabilities for shortcuts will continue evolving to reach into more cloud vendors (Google Cloud for example) or other products (Azure SQL Db, Cosmos Db, etc).
Performance and Scalability
Synapse Analytics: Synapse Analytics leverages its massively parallel processing (MPP) architecture to deliver high-performance query processing with dedicated resources and some serverless options. It enables on-demand provisioning of resources and the ability to pause them, making it suitable for variable workloads. If you need to fine tune resource allocations then you can create pool resource groups that define how much CPU and memory is available for a particular user group. Synapse also has capabilities related to running Spark, the Data Explorer engine, pipelines and each one of these has its own performance and scalability model. This requires more in-depth knowledge of each engine to know what to optimize, when and how. Lots of different knobs to move for individual objects like pools, Spark jobs, notebooks, pipelines, etc.
Fabric: Fabric's performance model is built around the concept of “capacities”. You provision a certain compute and memory capacity and then you can assign the different capacities to different workloads. This has its own pros and cons. On the pro side, it’s simpler to scale a given workload compared to Synapse however it does so at the expense of the finer grained control that you have on Synapse. Whether this is good or bad will definitely depend on the administrator of the solution, their knowledge and how much they are into optimization of individual processes.
Data Capabilities
Synapse Analytics: The Synapse workspace introduced a very powerful user experience that allowed SQL querying, creating notebooks, editing data pipelines and a somewhat “embedded” Power BI experience. All these experiences are bundled inside the Synapse workspace interface and they are mixed together into the user screen. Overall it flows pretty well but it can definitely be overwhelming for many users.
Fabric: For Fabric, Microsoft decided to have different interfaces tailored to different workloads, similar to what Databricks does with their web portal. Specifically you have the options of: Power BI, Data Factory, Data Engineering, Data Science, Data Warehouse and Real-time Analytics. Each different workload comes with a familiar but slightly different user interface that makes it easier to get going. So it is less overwhelming for new users however when you’re just starting you will need to familiarize yourself with what features are available under what workloads. 
Fabric also offers some features that target business users that might not be technical enough to do things like write complex SQL. For example, it comes with a feature rich Query Designer, that allows you to do a no-code step by step construction of your query and then generates the SQL for you.
Security and Compliance
Synapse Analytics: Azure's robust security features, including Azure Active Directory integration, role-based access control, and data encryption, extend to Synapse Analytics. It also supports compliance with industry standards such as GDPR, HIPAA, and ISO.
Fabric: There is no major discrepancy here in terms of capabilities since Fabric is also built on top of Azure and inherits the same security capabilities that Synapse does. The biggest difference would be the simplified security management, specifically when dealing with OneLake versus having to manage the ADLSG2 account directly when using Synapse. One big difference right now is that OneLake doesn’t offer the ability to bring your own key for the storage encryption of your data, however, we have to keep in mind that the service is in public preview and the capabilities will likely evolve over time to match everything that Synapse can do.
Pricing
Synapse Analytics: The pricing model of Synapse is composed of many different factors: the dedicated SQL Pools have individual prices based on Data Warehousing Units, the Spark pools are priced based on the cluster sizes, the pipelines are priced based on compute and numbers of executions and so on. This makes it harder to estimate and forecast the consumption of a Synapse workspace.
Fabric: Fabric simplifies the pricing by making it all about purchased capacity. You add up your capacity bundles and that is your price. You do have the option to pause a capacity and then the resources that you have assigned to that capacity will not be online until you turn it back on. So the pausing will add some variability to your bill but it is still simpler than the completely individualized pricing of Synapse.
Conclusion
Choosing between Synapse Analytics and Fabric right now depends on your organization's specific needs and existing technology stack. Let’s forget for a moment that Fabric is in preview and assume it is already generally available. In that scenario, Synapse would fit better on an architecture that is already built in Azure and is looking to integrate a platform into it. Fabric on the other hand is a great fit for an organization that wants to keep IT operations down and prefers a SaaS based approach with most things simplified, even if it is at the expense of more granular control. Both platforms have a lot of overlap that’s for sure but they excel in different areas, making it crucial to evaluate your data requirements, integration preferences, and long-term scalability goals before making a decision. However, regardless of which product you choose, you're equipping your business with a robust data solution to drive insights and innovation.
Microsoft Azure Consulting Services
Ready to optimize your use of Microsoft Azure Cloud's tools?
Share this
Share this
Three hidden Azure SQL database gotchas
Data classification with Microsoft SQL Server and Azure SQL DB (GDPR, PII, HIPPA...etc)
