On this page
Share this
Share this
Linux file system for SQL Server DBAs
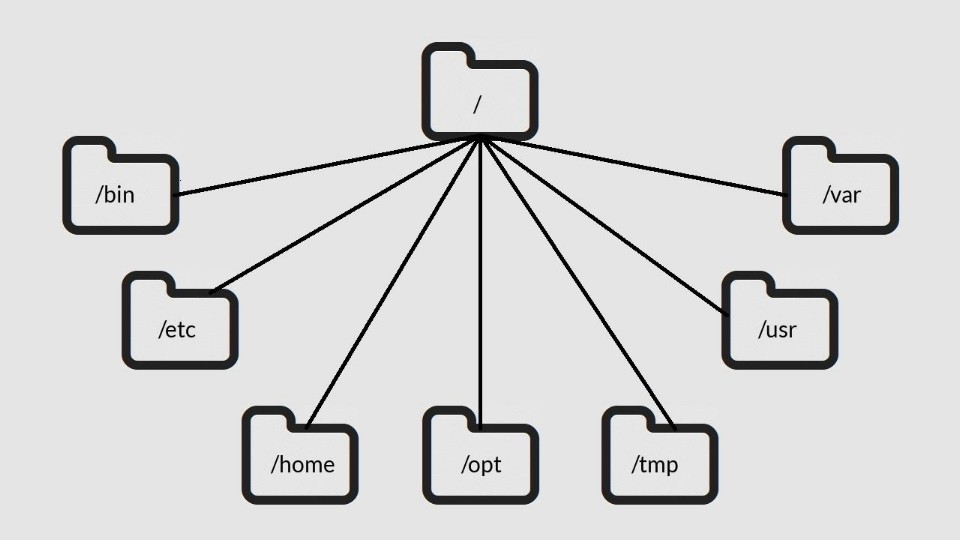
Linux file system for SQL Server DBAs
Jun 18, 2018 12:00:00 AM
7
min read
Exadata's Best Kept Secret: Storage Indexes
![]()
Exadata's Best Kept Secret: Storage Indexes
Jul 20, 2010 12:00:00 AM
2
min read
Observations and insights from Google Cloud Next '18
![]()
Observations and insights from Google Cloud Next '18
Nov 23, 2018 12:00:00 AM
7
min read