A commonly encountered scenario is when EBS volumes are not performing at the expected theoretical performance. Let's look at some of the potential reasons for that and how we can "fix" it. (When I say EBS volume, I am talking about SSDs specifically. I rarely see HDDs in use anymore.)
Planning for success
First of all, keep in mind that theoretical IOPS are based on an IO size of 16KB. If you are doing 32KB operations and have a volume rated 1000 IOPS, it means you effectively have 500 IOPS available. Instance type is closely related to IO performance. When working with databases, you want to use an EBS-optimized instance type. This ensures dedicated bandwidth is available to the IO layer. In addition to that, instance types have a cap on bandwidth and IOPS. So when picking your instance type, don't base the decision on the number of CPUs and memory alone. Make sure to also look at the IO cap.Provisioned IOPS?
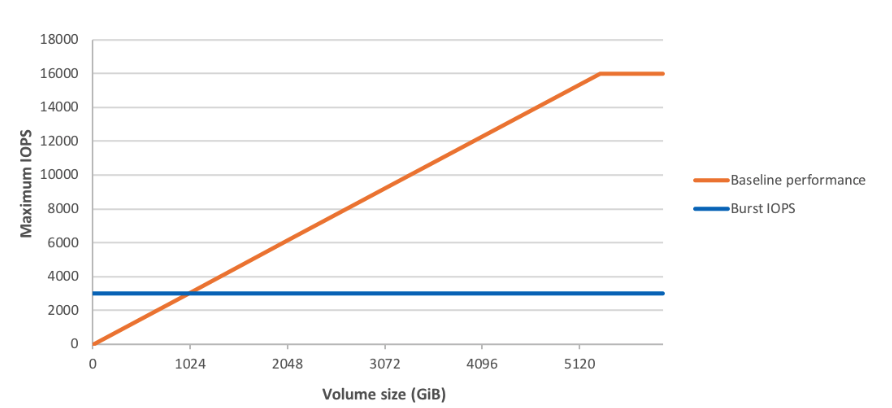
Provisioned IOPS volumes are often not selected because they are much more expensive than gp2. As of now, gp2 volumes have a max throughput of 16000 IOPS (this used to be 10k until not so long ago), so they are well-suited for a good number of use cases. Note that if you have an existing volume, you will first need to perform a ModifyVolume action on it to get it "updated" to have 16k IOPS. Provisioned IOPS volumes can go as high as 32k IOPS (64k with a certain instance type). The performance of gp2 volumes smaller than 1TB is also tied to their size. They have a baseline performance, and can "burst" to better performance based on the number of available credits, up to 3K IOPS. You can read more about this here .
Image (C) Amazon
Starting at 5TB size, gp2 volumes get the maximum performance of 16k IOPS. It is a very common practice to provision 5TB just to take advantage of the extra speed even if you need less space.Operating system considerations
According to the AWS docs , we need a kernel with support for indirect file descriptors to get the most out of EBS. Indirect file descriptors are available since kernel version 3.8. In practice, I haven't seen this as an issue (at least at the time of this writing) even though a lot of people are still running Centos 6 (kernel in the 2.6.x branch) Interrupt handling is really important too. When using irqbalance package versions older than 1.0.6, all disk-related interrupts go to core 0 which can cause a bottleneck. Newer versions of irqbalance spread the load between all CPU cores. There is a feature called RPS (receive packet steering) that basically does the same thing (spreading interrupt handling) for network-related interrupts. The way to enable it (e.g. for eth0) is as follows:echo ffff > /sys/class/net/eth0/queues/rx-0/rps_cpus
Snapshot caveats
When working with EBS snapshots, keep in mind restored volumes are lazy-loaded from S3. This means the first time you access a block, the performance will be poor. It is required to pre-warm the volume in order to get full performance. For multi-TB volumes, this can take several hours. So if your recovery strategy relies on snapshots, make sure to plan for that.Final thoughts
If all the above recommendations haven't solved your problem, you still have the option of using storage-optimized instances. These come with very fast NVM storage. The downside is that, as with all local volumes, they are ephemeral. If the instance is powered off then the data is gone, so make sure to have a way around that by using some kind of clustering solution. If you are interested in hearing more, come see me speak at Percona Live Europe 2019 which is hosted in Amsterdam this year. Use CMESPEAK-IVAN code to get 20% off the registration fee.Share this
Next story
Can you run Hadoop in the cloud? →
Embracing Flexibility to Improve Your Remote Team’s Performance

Embracing Flexibility to Improve Your Remote Team’s Performance
Mar 8, 2021 12:00:00 AM
3
min read
The Best Automation Tools to Power up Your SAP S/4 Migration Journey

The Best Automation Tools to Power up Your SAP S/4 Migration Journey
Mar 16, 2022 12:00:00 AM
4
min read
Black Friday is in the books. Did your IT systems keep up?
![]()
Black Friday is in the books. Did your IT systems keep up?
Dec 11, 2019 12:00:00 AM
2
min read
No Comments Yet
Let us know what you think