Introduction
The Levenshtein Distance, as discussed in my last post, is a way to measure how far two strings are located from each other. There are several T-SQL implementations of this functionality, as well as many compiled versions. In addition, the MDS library in SQL Server has a Similarity function which uses the Levenshtein Distance to find how similar two words are. In this post, I've done a simple comparison of performance using a C# CLR implementation of Levenshtein Distance ( The code is from the Wiki), and a well written T-SQL implementation from Arnold Fribble. As many of you might expect, the C# implementation is much quicker. Needing only 2504 ms to run through dictionary table of 203,118 words. The T-SQL implementation took 42718 ms for the same work. [caption id="attachment_81563" align="alignnone" width="360"]
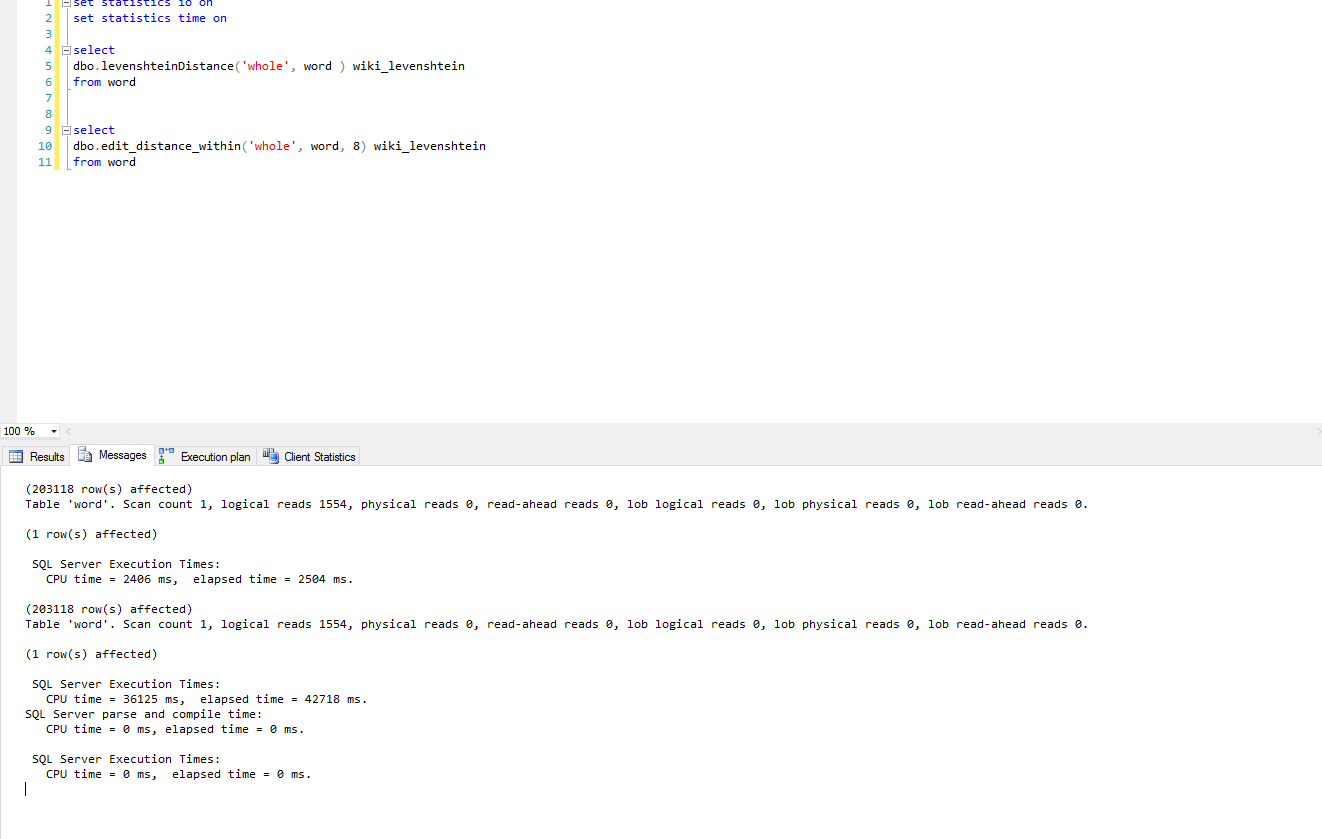
Levenshtein Distance Comparison[/caption]
Levenshtein Distance CLR
To implement the Levenshtein Distance CLR, run this SQL ScriptLevenshtein Distance T-SQL
To implement the Levenshtein Distance in T-SQL, run the below code. Please note that this function has a cut-off value (@d) where it simply gives up and returns -1. [code]CREATE FUNCTION edit_distance_within(@s nvarchar(4000), @t nvarchar(4000), @d int) RETURNS int AS BEGIN DECLARE @sl int, @tl int, @i int, @j int, @sc nchar, @c int, @c1 int, @cv0 nvarchar(4000), @cv1 nvarchar(4000), @cmin int SELECT @sl = LEN(@s), @tl = LEN(@t), @cv1 = '', @j = 1, @i = 1, @c = 0 WHILE @j <= @tl SELECT @cv1 = @cv1 + NCHAR(@j), @j = @j + 1 WHILE @i <= @sl BEGIN SELECT @sc = SUBSTRING(@s, @i, 1), @c1 = @i, @c = @i, @cv0 = '', @j = 1, @cmin = 4000 WHILE @j <= @tl BEGIN SET @c = @c + 1 SET @c1 = @c1 - CASE WHEN @sc = SUBSTRING(@t, @j, 1) THEN 1 ELSE 0 END IF @c > @c1 SET @c = @c1 SET @c1 = UNICODE(SUBSTRING(@cv1, @j, 1)) + 1 IF @c > @c1 SET @c = @c1 IF @c < @cmin SET @cmin = @c SELECT @cv0 = @cv0 + NCHAR(@c), @j = @j + 1 END IF @cmin > @d BREAK SELECT @cv1 = @cv0, @i = @i + 1 END RETURN CASE WHEN @cmin <= @d AND @c <= @d THEN @c ELSE -1 END END [/code]
SQL Server Consulting Services
Ready to future-proof your SQL Server investment?
Share this
Share this