In this blog post, we continue our review of the new Oracle GoldenGate Big Data adapters. In the first part of the series, I tested the basic HDFS adapter and checked how it worked with some DML and DDL. In this article, I will try the Flume adapter and see how it performs.
1. Understanding Apache Flume
A quick reminder on what Flume is: we aren't talking about the popular Australian musician. Apache Flume is a pipeline or streaming system designed to move large amounts of data efficiently.
It has a simple architecture consisting of three main components:
- Source: Where data enters into Flume from an outside system.
- Sink: Responsible for passing data to the destination system (either the final destination or another flow).
- Channel: The conduit that connects the Source and the Sink.
The focus of this article is how we can pass data from Oracle to Flume using GoldenGate. Let's assume we have an Oracle source system replicating DML and DDL for the GGTEST schema using Oracle GoldenGate 12.2.
2. Preparing the Flume Agent
First, we ensure the GoldenGate for Big Data (OGG BD) manager is up and running:
GGSCI (sandbox.localdomain) 1> info manager Manager is running (IP port sandbox.localdomain.7839, Process ID 18521).
Configuring the Flume Configuration File
We need to prepare the configuration file for the agent to handle the incoming stream. We will set our source to Avro (though Thrift is also supported) and the sink to HDFS. While using Flume to write to HDFS might seem redundant (since OGG has a native HDFS adapter), this setup is excellent for comparing adapter capabilities.
Flume Agent Configuration (flume.conf):
# Name/aliases for the components on this agent agent.sources = ogg1 agent.sinks = hdfs1 agent.channels = ch1 # Avro source agent.sources.ogg1.type = avro agent.sources.ogg1.bind = 0.0.0.0 agent.sources.ogg1.port = 4141 # Describe the sink agent.sinks.hdfs1.type = hdfs agent.sinks.hdfs1.hdfs.path = hdfs://sandbox/user/oracle/ggflume # Use a channel which buffers events in memory agent.channels.ch1.type = memory agent.channels.ch1.capacity = 100000 agent.channels.ch1.transactionCapacity = 10000 # Bind the source and sink to the channel agent.sources.ogg1.channels = ch1 agent.sinks.hdfs1.channel = ch1
3. Configuring Oracle GoldenGate for Big Data
Now we prepare the OGG configuration. Examples for the Flume adapter can be found in $OGG_HOME/AdapterExamples/big-data/flume/.
Defining Adapter Properties
We need to adjust flume.props to point to our handler and define the format.
dirprm/flume.props snippet:
gg.handlerlist = flumehandler gg.handler.flumehandler.type=flume gg.handler.flumehandler.RpcClientPropertiesFile=custom-flume-rpc.properties gg.handler.flumehandler.format=avro_op gg.handler.flumehandler.mode=tx gg.handler.flumehandler.EventMapsTo=tx gg.handler.flumehandler.PropagateSchema=true gg.handler.flumehandler.format.WrapMessageInGenericAvroMessage=true
RPC Client Properties
The custom-flume-rpc.properties file is used by the OGG adapter to connect to the flume-ng agent
client.type=default hosts=h1 hosts.h1=localhost:4141 batch-size=100 connect-timeout=20000 request-timeout=20000
4. Testing Initial Load and Continuous Replication
With the configurations in place, we start with an initial load using a passive replicat.
Initial Load Executio
# Executing initial load [oracle@sandbox oggbd]$ ./replicat paramfile dirprm/irflume.prm reportfile dirrpt/irflume.rpt
Upon success, three new files appear on HDFS: two containing the schema description and one containing the actual data for the replicated tables.
Continuous DML Replication
Next, we start a permanent replicat (rflume) to handle ongoing changes. We tested this by inserting a row on the source Oracle database
orclbd> insert into ggtest.test_tab_1 values (7, dbms_random.string('x', 8), sysdate-7, dbms_random.string('x', 8), sysdate-6); orclbd> commit;
Immediately after the commit, Flume generates new files on HDFS. The first file contains the updated schema, and the second contains the payload (the transaction data).
Regression and Performance
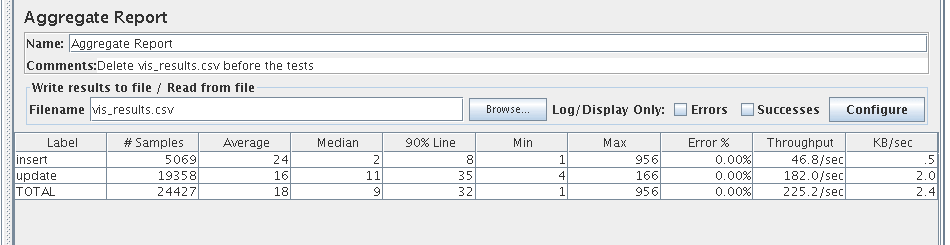
I executed regression testing using JMeter, pushing approximately 29 transactions per second. Even with a single Flume channel and a modest Hadoop environment, the system maintained a healthy response time without errors, packing about 900 transactions per HDFS file.
5. Handling DDL Operations
The adapter's behavior during DDL varies depending on the command:
- TRUNCATE: This command is not replicated by the Flume adapter.
- ALTER TABLE: Changes are not seen as a separate command. Instead, the adapter generates a new schema definition file followed by the transaction data for any subsequent DML.
Conclusion
The Oracle GoldenGate Flume adapter works as expected, successfully supporting the flow of transactions from Oracle to Flume using both Avro and Thrift sources. While this test served as a basic functional validation, a production implementation would require a more robust architecture.
Oracle Database Consulting Services
Ready to optimize your Oracle Database for the future?