It's already a fact: cloud is here to stay. As time goes by, we have a better understanding of how it really works as well as its real pros and cons. But here is the most important lesson: We don't need to completely move to the cloud in one shot. The complete "cloud-shift" may never happen, depending on the business requirements, future plans and business requirements. The cloud may act as a support for specific on-premises needs, creating a hybrid system which takes the best from both on-premises and from the cloud. This mix results in a system where you have control over the resources, and the advantage of cloud scalability. The cost constraint is the same as maintaining your systems on-premises. Microsoft SQL Server and Microsoft Azure offer different options to integrate an instance on-premises. In this article I will look at the "Hybrid Partitioning" capability.
What is hybrid partitioning?
Hybrid partitioning is not an official Azure service or even a SQL Server new feature. This is just a creative way to take advantage of some capabilities from both SQL Server and Azure:
- Azure storage
- SQL Server table partitioning
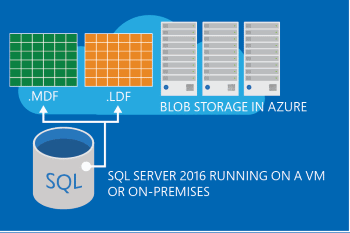
- SQL Server support for data & log files in Azure
Why not stretch database?
Stretch database is a SQL Server capability that helps with moving tables - or just some filtered rows - to Azure by using an Azure SQL Database as support service. This movement process is online and transparent, so by even having parts of your database in Azure, no application changes are required, and the data is going to still be available as before. This feature helps by minimizing the used disk space on-premises, which results in a smaller database backup size - reducing backup window - as well as improving the database maintenance. This was a quick description of the feature and it's easy to understand its great benefits, so what are the cons? Well, the price. Depending on the performance level, you may pay up to $36,500/month, with a starting price of $1,825/month.
Hybrid partitioning as stretch database alternative
The Hybrid Partitioning strategy sits on the possibility of maintaining an on-premises database working based on files located in Azure Storage, you can find more details here.
The price is the advantage here, as it won't provide the same performance as Stretch Database promises. Also, the data moved to Azure is still going to be included in the maintenance (backups, index operations, ...), unless you customize your scripts to better fit with this strategy. Here are few use cases where this would be useful:
- Historical data must be retained for X years, but this is not frequently used.
- Because of disk space constraints, old data is being purged to free up space.
- Create an Azure Storage account and container (more info here)
- Create a new database Filegroup (or multiple ones)
- Create one or more files inside of the created Filegroup, pointing to Azure Storage
- Create a partition scheme and function
- Enable the partitioning on the table
Here is an example on how it could be implemented:

By using this method, it would be possible to keep just the most current data in the local server, and move the cold data, which probably won't be too much requested, in Azure. It's also possible to move the entire table to Azure, and this is simpler... The steps are:
- Create an Azure Storage account and container (more info here)
- Create a new database Filegroup
- Create a table referring the new Filegroup - the default is the PRIMARY Filegroup
- You can also move the table from the current filegroup to the new one
In summary
Since SQL Server supports data and log files placed in Azure Storage, we can take advantage of the table partitioning feature to improve the system and save local storage costs. Always remember to match the application requirements and queries with the used partitioning strategy, this way you also get performance benefits when using table partitioning.
SQL Server Database Consulting Services
Ready to optimize your SQL Server Database for the future?