Reasons
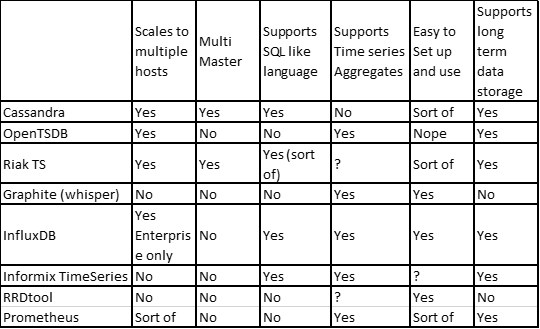
When I think of Time series databases, my first thoughts go to my own experiences using a relational database to store time series data. The mapping tends to be fairly straight forward. Each row stores data for a single event for a specific entity, whether it be a sensor, server metric, financial transaction etc. There are many, many kinds of time-based data. But, it often turns out that really small rows in a relational database aren’t all that efficient and the kinds of aggregate operations you may want to perform are just not available in your relational database of choice. Additionally, traditional B-Tree architectures are not necessarily well suited for writing time series data. B-Trees are great for reading and writing random or semi-random data. They are optimized for fast random reads with writes, updates and deletes being expensive. When writing time series data often writes are much more frequent than reads. There are no updates, the data is written once, and deletes are often over large ranges of data as it “Expires”. So the search is on for an alternative. We go to Wikipedia here: https://en.wikipedia.org/wiki/Time_series_database For a topic of major interest to many this is one of the poorest Wikipedia articles I have read in quite a while. Hmmm… Maybe I should finally sign up as an editor and fix it. Well that’s for later. The article leaves out a few time series databases I know of. The Wikipedia article lists seven databases or variants of databases designed or tuned for time series data. They are: Graphite, InfluxDB, Informix TimeSeries, RRDtool, Riak-TS , ExtremeDB and QuasarDB. In addition, I know of a few more, there is OpenTSDB, CeresDB and Prometheus. OpenTSDB doesn’t even have a page in Wikipedia but it’s a thriving Apache project. Hmmm… I should start contributing to Wikipedia. In addition, Splunk and Logstash are, in effect, time series databases specifically designed around storing and querying log data which is a special form of sparse time series data. That is the last I am going to discuss them in this blog entry. Graphite/Whisper, Ceres, RRDtool and Prometheus are very specialized. Designed to work with, or part of a monitoring and metrics system designed to collect server data produced on a regular basis for display on a Graphical user interface. The others are more general purpose-designed to support many kinds of time series data. So why, with all those special built or at least specially modified databases dedicated to time series data did I title this blog “Time series databases and Cassandra”? It turns out that even with all those existing Time series databases specially designed to support time series data, a whole lot of people are using Cassandra to store their time series data instead. Which brings me to the obvious next question, why?..... Right off the top Cassandra does not use B-Trees to store data. Instead it uses Log Structured Merge Trees (LSM-Trees) to store its data. This data structure is very good for high write volumes, turning updates and deletes into new writes. Reads are often an order of magnitude slower than writes which is exactly the opposite of B-Trees. The underlying storage mechanism would appear to be compatible with Time Series Data. Beyond that the reasons are not so simple. There are a number of reasons, including purpose, cost, scalability, availability, ease of use and my favorite, my competitor or buddy or just the guy down the street is doing it. So, let’s take a look at each of those reasons:
Purpose
Whisper (Graphite), RRDtool, Ceres and Prometheus are special purpose databases designed for, or part of existing monitoring and metrics systems and are not general purpose. If you are building a monitoring and metrics system to keep track of the performance of your server farm they are going to be obvious candidates. If you are tracking freeway sensor or fitness tracker data probably not so much.Cost
Some of the databases in the list are proprietary licensed products. Nothing wrong with that, but it does mean a potentially significant upfront cost and to be honest in the modern open source popular world this becomes a major negative to many organizations. Informix, InfluxDB enterprise and DataStax Enterprise Cassandra (DSE) loose on this score.Scalability
If you are tracking the processor, memory and disk utilization of a couple dozen servers you don’t need much disk space to store many years’ worth of your time series data and you don’t much care about scalability. In that case Graphite and the community version of InfluxDB will probably work just fine. But…., if you want to track server metrics from one hundred thousand virtual servers with one-minute granularity you probably need a really scalable platform. Then you are going to need InfluxDB enterprise, Riak TS OpenTSDB or can I say it now? Cassandra.Availability
If you are monitoring a large number of somethings you probably really want to monitor them all the time and outages of your metrics database is going to be a BAD thing. So you want a highly available database. In the highly available world the best highly available systems are those which are designed from the ground up to be highly available where you can write or read to/from any node in the system and get meaningful results. Master Slave architectures no matter how good are just not as effective in handling a continuously incoming stream of data as multi-master databases are. With that in mind you are going to be limited to Riak TS, OpenTSDB (sort of) and Cassandra. All three are based on some similar concepts involving a cluster of distributed nodes. although the implementations vary quite a bit.Ease of use
Graphite and open source InfluxDB are incredibly easy to set up and use although they have their own API languages for accessing the data that you have to learn they provide powerful aggregates very useful for Time series data. The Influx query language is SQL like. Graphite doesn’t really support a query language outside of the graphical UI beyond a basic csv export function. Cassandra and Riak TS are fairly easy to set up (more difficult primarily in that they are distributed in nature) and they offer an SQL like language to access the data, although they do not have some of the very nice aggregates available to Graphite and InfluxDB. They are also a bit more general purpose and can be used for other things. OpenTSDB is based on Hadoop and Hbase requiring that you set up a Hadoop cluster then install Hbase and zookeeper. Finally, you add the OpenTSDB Daemons. This is a lot of work to get your time series database up and running. OpenTSDB also uses its own proprietary Query language which although very powerful for Time Series data is not anything like SQL.Everyone is using it
Now we get to the more subjective warm and fuzzy (pun intended) logic for making a decision which database to use. If you are a big data user with Hadoop, Zookeeper and Hbase already running OpenTSDB is the obvious choice. If you are a DevOps person with experience building monitoring systems, you are probably going to lean in the direction of Graphite, InfluxDB or Prometheus. At least until you run into scaling issues. If you know Erlang and Riak you might try Riak TS (there are not so very many of us in that group and if you haven’t heard the company that developed Riak went Bankrupt last year). If you don’t have DevOps experience or the scale of your project eliminates InfluxDB or Graphite and you don’t have a Hadoop cluster ready to go for you a quick search of the internet or chatting with your buddy over at xyz organization, you are going to hear about the wonders of Cassandra for storing Time Series data.Conclusion
Cassandra is not a purpose-built for time series data. In fact, its lack of aggregates can make the choice an odd one at times but it accepts rapid writes (in fact writes are usually an order of magnitude faster than reads), scales to really, large clusters with lots of disk space and its multi-master write and read anywhere even in geographically separate locations with lots of other people doing it makes a lot of sense.The mandatory chart
Cassandra Database Consulting Services
Ready to optimize your Cassandra Database for the future?