Introduction: Why AI Agents Are the Next Step Beyond Traditional Systems
In recent years, Natural Language to SQL (NLP-to-SQL) systems have captured attention for their ability to translate human questions into database queries. Ask something like “Show me the total sales in 2024”, and the model generates an SQL statement instantly.
However, in real-world environments, databases are often complex and evolving, and many traditional NLP-to-SQL pipelines struggle once they move beyond controlled or demo scenarios.
The Problem with Traditional Approaches
Most NLP-to-SQL systems use a single LLM prompt or a rule-based parser to translate natural language into SQL. While this can work well in constrained or demo environments, the approach can encounter limitations in real-world scenarios.
This approach can struggle because:
- It may hallucinate tables and columns that do not exist.
- It can overlook important context such as schema relationships or dataset scope.
- It does not always validate whether the generated SQL is syntactically or logically correct.
- It lacks self-awareness, with no built-in mechanism to assess or refine its own outputs.
The result is unreliable queries, runtime failures, and limited transparency into why a model selected certain tables or filters.
Enter AI Agents: Thinking in Steps, Not Prompts
Instead of treating query generation as a one-shot task, AI agents divide reasoning into smaller, specialized steps, similar to how a human data analyst approaches the problem.
Imagine a data engineer faced with a question like:
“What types of schedules are available in Baseball?”
They would not immediately write SQL. Instead, they would first interpret the user’s intent, examine the available tables, determine which columns are relevant, and then construct the query, followed by validation.
AI agents replicate this multi-step reasoning through modular, cooperative components, each focused on a single responsibility.
This modularity makes them:
- Interpretable → You can trace every decision.
- Grounded → They only work with schema they’ve seen.
- Safe → They validate queries before execution.
- Extensible → You can plug in new agents like “Auto-Repair” or “Result Preview.”
This project brings that concept to life.
System Architecture Overview
The architecture is organized as a directed reasoning graph orchestrated by an agent framework. Each node in the graph represents a specialized agent, and edges define the flow of information between them.
At a high level, the system follows this sequence:
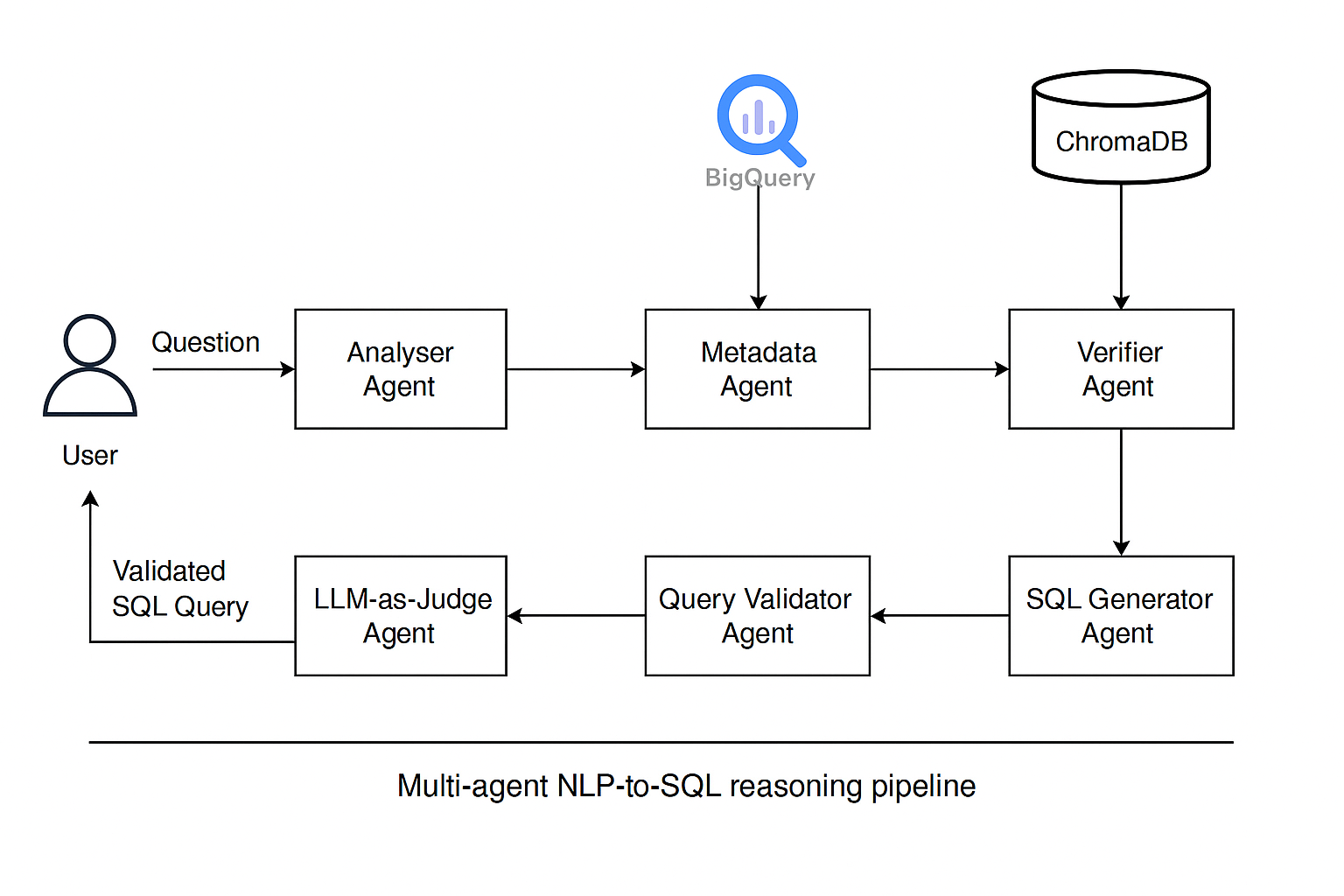
The Analyzer Agent interprets the user’s question, extracting intent and key entities. Its goal is not to produce SQL, but to clarify what the user is asking.
The Metadata Agent retrieves schema information from the data warehouse or a predefined schema source. This ensures all subsequent reasoning is grounded in known datasets and tables.
The Verifier Agent uses retrieval techniques to match the interpreted intent against relevant tables and columns. By narrowing the search space, it reduces the likelihood of hallucinated references.
The SQL Generator Agent constructs a query using verified schema elements. Because the input is constrained and structured, generation becomes more deterministic.
The Query Validator Agent performs a non-executing validation pass, checking syntax and schema correctness without consuming resources.
Finally, the LLM-as-Judge Agent evaluates whether the query is correct, safe, and complete relative to the original question. The output includes both a score and an explanation.
This modular pipeline transforms SQL generation into a controlled reasoning process.
Demonstration: Query Generation in Practice
The project includes Streamlit-based interface snippets that illustrate how natural language queries are processed and translated into SQL by the multi-agent pipeline.
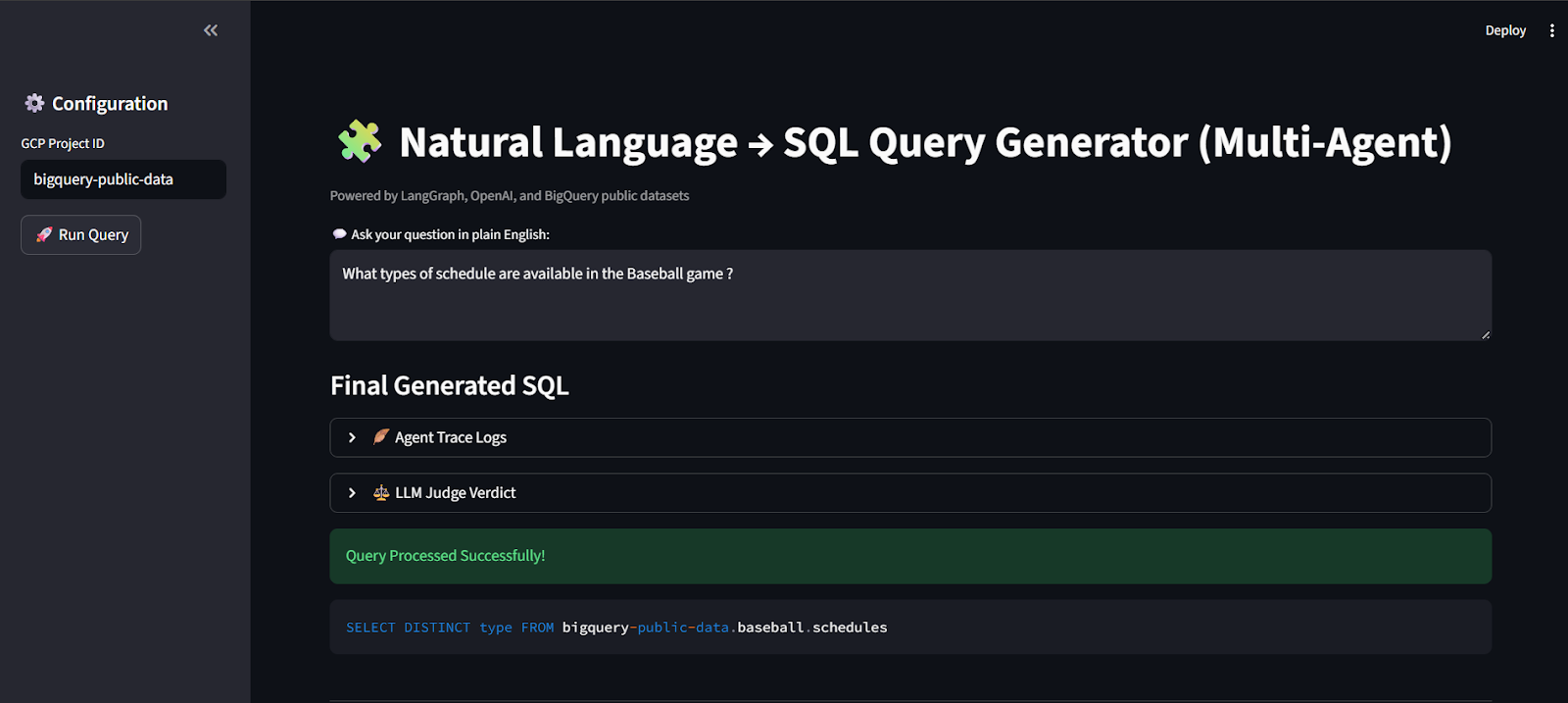
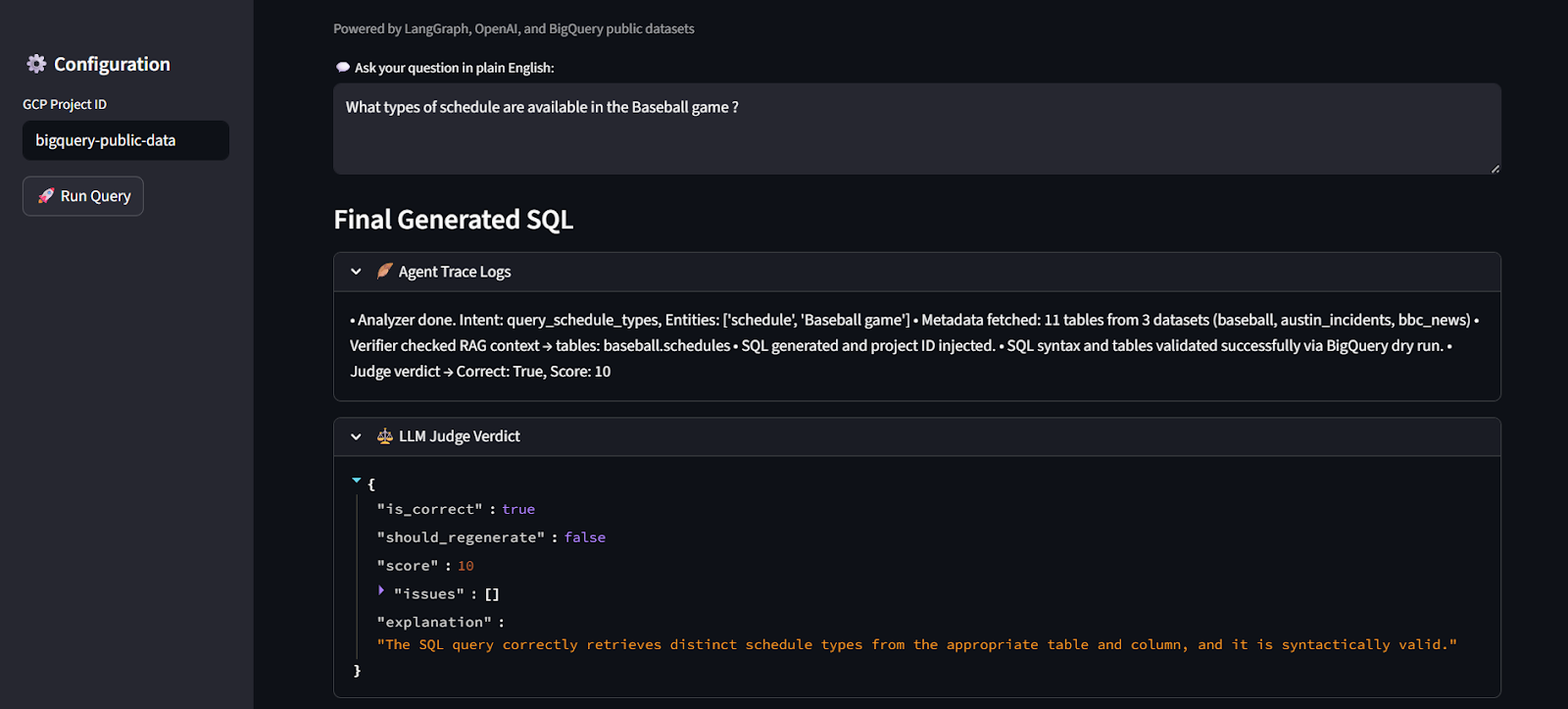
In the example shown above, a user asks a plain-English question related to baseball schedules. The system processes this request through the full reasoning flow, beginning with intent analysis and schema grounding, and ending with SQL generation, validation, and judgment.
The interface exposes key system outputs, including:
- Final generated SQL, constructed using verified schema elements
- Agent trace logs, which provide visibility into intermediate reasoning steps such as intent extraction, metadata resolution, and validation
- LLM-as-Judge verdict, which evaluates correctness, safety, and completeness using a structured assessment
This demonstration highlights how the system prioritizes transparency and reliability. Rather than returning SQL as a black-box output, it surfaces the reasoning and validation steps that led to the final result, making it easier to understand, debug, and trust in real-world usage.
Grounding Through Schema Awareness
One of the most significant contributors to reliability is explicit schema grounding. Instead of relying on the model’s latent knowledge, the system retrieves and embeds schema metadata, such as datasets, tables, and column descriptions.
By using retrieval mechanisms over schema embeddings, the system ensures that reasoning is constrained to known structures. This reduces ambiguity and prevents the introduction of nonexistent entities.
Importantly, schema grounding happens before SQL generation. This ordering matters: when generation is informed by verified context rather than raw intuition, the resulting queries are more accurate and consistent.
Validation and Judgment as First-Class Concepts
In many traditional NLP-to-SQL pipelines, validation is often handled outside the core generation process. This architecture integrates validation and judgment directly into the reasoning flow.
The validation step ensures that a query is syntactically valid and references existing schema elements. Because it runs in a non-executing mode, it provides safety without performance cost.
The judgment step goes further. It evaluates whether the query actually answers the question, whether it is read-only, and whether important constraints are missing. This introduces a feedback mechanism that is typically absent in generative systems.
By separating generation from evaluation, the system gains an internal check that mirrors peer review in human workflows.
Why Multi-Agent Architectures Are More Reliable
The reliability gains of this approach stem from several factors.
First, determinism improves because each agent operates within a bounded responsibility. The model is no longer asked to solve multiple problems at once.
Second, traceability improves as every decision, from table selection to validation outcomes, can be explicitly inspected and logged.
Third, extensibility becomes straightforward. New agents, such as auto-repair or result preview components, can be added without redesigning the entire system.
Most importantly, failure modes become explicit. When something goes wrong, the system can explain where and why, rather than returning an opaque error.
Limitations and Future Directions
While multi-agent systems significantly improve reliability, they are not without trade-offs. Increased orchestration adds complexity, and latency may increase as additional reasoning steps are introduced.
Future enhancements may include automated query repair, multi-turn conversational context, and interactive schema exploration. These additions further emphasize that NLP-to-SQL is best treated as an evolving system rather than a static model prompt.
Conclusion
NLP-to-SQL failures are rarely due to language misunderstanding alone. They often arise when interpretation, grounding, generation, and validation are combined into a single step. A multi-agent architecture addresses this by restoring clear reasoning boundaries and treating query generation as a structured reasoning process. By integrating validation and judgment as first-class components, such systems produce SQL that is not only syntactically correct, but also reliable and explainable in real-world settings.
AI Consulting Services
Ready to start your AI journey?
Share this
Share this

The Definitive Definition of Production AI: Moving from Pilot to ROI

Is Your Business AI-Ready?
