This post is the first part of a series of blog posts regarding the lifecycle and management of tombstones. Deleting and expiring data in Cassandra is something that you should carefully plan. Especially if you’re about to delete a massive amount of data at once. Without proper planning, this can bring problems to the cluster like an increase in read-latency and disk usage footprint. Throughout this post, I will describe a way of tackling this and its caveats.
Understanding cassandra deletion basics
First, let's go over the basics. In Cassandra, the data files (SSTables) existing on disk are immutable files. When we are deleting something in Cassandra, a new SSTable is created that contains a marker. This marker indicates which partition, row, or cell was removed along with the timestamp for that deletion. This deletion marker is called a tombstone. The deleted data and the tombstone can coexist on the disk during a period called gc_grace_seconds, which is by default 10 days. During this time, although the data can still exist on the drive, it's not returned to the client if queried. Which means that from a client point of perspective, the data is deleted as soon as you execute the delete statement. However, from an operational point of view, both the data and the tombstone can still exist and occupy space on the disk. This deleted data which still exists on disk is called “shadowed data.” N.B.: In the previous paragraph I say that the data and the tombstones "can still coexist on disc" (emphasis on the "can") because if compaction occurs that involves the data and the tombstones, then the data is evicted. But the tombstone will remain if gc_grace_seconds has not passed.
The role of repair and zombie data
The gc_grace_seconds is a safety mechanism to ensure that the tombstone has enough time to replicate to all nodes that have a replica of the shadowed data. For this safety mechanism to be successful, you must be able to repair the cluster every gc_grace_seconds. Meaning that if you are using the default 10 days for gc_grace_seconds, a repair must be started and finished within every 10 days. The repair serves the purpose of preventing zombie data in the cluster. I won't go into the details of how this can happen, but basically, zombie data occurs when you delete data, but it returns sometime later. After gc_grace_seconds has passed, the data and the tombstone can finally be evicted from the disk, recovering the disk space previously used by them (Figure 1).
Disk space reclamation and compaction
The ETA to release the disk space is one of the first points that I want to clarify in this post. When using Cassandra, many people find this mechanism surprising, i.e., that after deleting data, the data still exists on disk. This confusion is usually quickly clarified as soon as people learn about tombstones and gc_grace_seconds. However, it seems that operators tend to think that the data and the tombstones are evicted right after gc_grace_seconds has finished. In fact, it's essential to be aware that this might not (and tends not) to be true. Usually, it takes longer than gc_grace_seconds for this eviction to happen and the disk space recovered. [caption id="attachment_106618" align="aligncenter" width="852"]
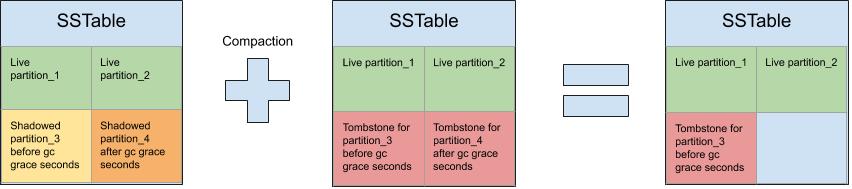
Figure 1 - compacting shadowed data with expired and non-expired tombstones[/caption]
How tombstones are effectively purged
The eviction mentioned above happens when compaction occurs that involves the SSTables that have the shadowed data and the tombstone. Only then, the data is effectively removed, and the disk space recovered. It's important to note that even if gc_grace_seconds has passed and the SSTable with the shadowed data is compacted with another SSTable that does not have the tombstone, then the shadowed data is not purged. The same thing happens for the tombstone markers, i.e., if the SSTable with the tombstone is not compacted with all the SSTables that still have data that was deleted, then the tombstone is not evicted from the disk. The reason this happens is that during compaction, Cassandra does not know what's in the SSTables that are not involved in the compaction. So it has no way to know that it can discard the data since it can't see the tombstone. You can see this in Figure 2 where, although gc_grace_seconds has passed for both tombstones, nothing is evicted after the compaction. [caption id="attachment_106620" align="aligncenter" width="851"]
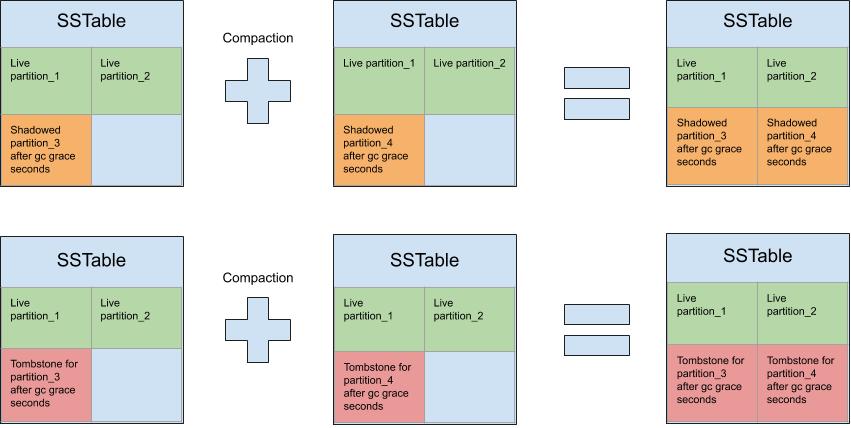
Figure 2 - compacting shadowed data and their tombstones separately[/caption]
Performance impacts and conclusion
Due to the disk usage by the data and the tombstone marker, the accumulation of tombstones can impact read-latency, because Cassandra needs to read lots of tombstones before returning live data. Deleting data is usually not a problem if these deletions are small and sparse. Because, over the natural compaction lifecycle, Cassandra eventually recovers the disk space and the purged tombstones.
Managing large-scale deletions
However, if you're deleting a large amount of data at once, that creates many tombstones and can quickly impact your read-latency. If you need to delete a large amount of data on an ad-hoc basis, then there are some steps in the next blog post that you can take to mitigate risks.
Cassandra Database Consulting
Ready to handle massive data volumes with zero downtime?